







目录
Rethinking the Inception Architecture for Computer Vision
摘要
卷积网络是最先进的计算机视觉解决方案的核心,适用于各种任务。自2014年以来,非常深的卷积网络开始成为主流,在各种基准中产生了实质性的收益。虽然模型大小和计算成本的增加往往会转化为大多数任务的直接质量提升(只要提供足够的标签数据进行训练),但计算效率和低参数数仍然是各种用例(如移动视觉和大数据场景)的有利因素。** 在这里,我们正在探索如何通过适当的因子卷积(factorized convolutions)和主动正则化(aggressive regularization)来尽可能高效地利用增加的计算量来扩展网络。**我们在ILSVRC 2012分类挑战验证集上对我们的方法进行了基准测试,证明了我们的方法比目前的技术水平有很大的提高:使用一个计算成本为50亿乘加的网络进行单帧评估,并且使用少于2500万个参数,前1名和前5名的误差分别为21.2%和5.6%。在4个模型的集合和多作物评估中,我们报告了3.5%的top-5误差和17.3%的top-1误差。
目的是为了增加网络的宽度,通过因子卷积和主动正则化的方式。
1、引言
AlexNet和VGG网络结构的计算量和参数量都比较大
在本文中,我们首先描述了一些通用的原则和优化思想,这些原则和思想被证明对于以有效的方式扩展卷积网络是有用的。虽然我们的原则并不局限于Inception类型的网络,但在这种情况下,它们更容易被观察到,因为Inception风格构件的通用结构足够灵活,可以自然地纳入这些约束。这得益于Inception模块的维度缩减和并行结构的大量使用,这可以减轻结构变化对附近组件的影响。不过,人们仍然需要谨慎地这样做,因为应该遵守一些指导原则,以保持模型的高质量。
2、通用的设计原则
- 在网络上结构的早期避免表征瓶颈结构设计-表征的维度应逐渐减少
- 高维度的表征更容易在网络中传递-每个卷积层中激活函数的应用
- 空间聚合可以在较低维度上进行,而不会造成太多或任何表征能力的损失
- 平衡网络的深度和宽度
3、大尺寸滤波器的因式分解
3.1 大卷积转换成小卷积
将两个3x3的卷积替换一个5x5的卷积,较少计算时间增加滤波器的数目
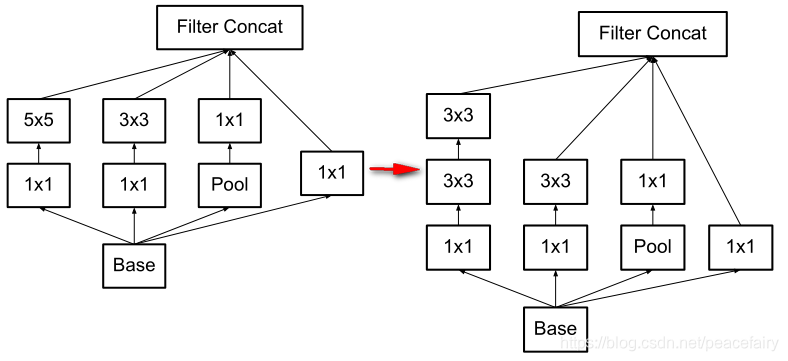
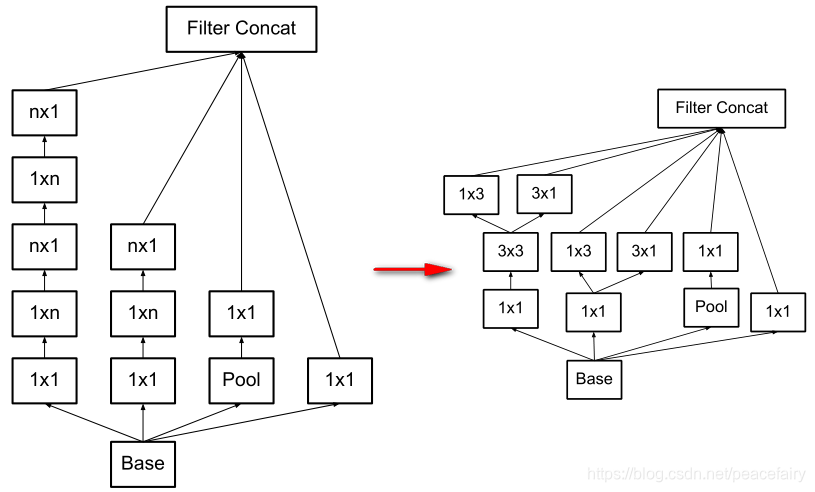
3.2 分解为非对称卷积
在输入和输出通道数保持一致时,将 nxn的卷积换成 nx1 和1xn两层卷积,在实践上,当处在网络中层时,当特征图的尺寸为(12~20)时,该模块的效果会好。
4、辅助分类器的使用
- 为了改善非常深的网络收敛问题,提出了辅助分类器的概念。
最初的动机是将有用的梯度推到更低的层,使它们立即有用,并通过解决非常深的网络中的消失梯度问题来改善训练过程中的收敛性。
作者发现
有趣的是,我们发现辅助分类器并没有在训练早期导致更好的收敛:在两个模型达到高精度之前,有侧头和不带侧头的网络的训练过程看起来实际上是相同的。在训练接近尾声时,有辅助支路的网络开始超越没有任何辅助支路的网络的精度,并达到一个稍高的平台期。
引入辅助分类器,其实起regularizer作用。当辅助分类器使用了batch-normalized或dropout时,主分类器效果会更好。
5、有效降低特征图的大小
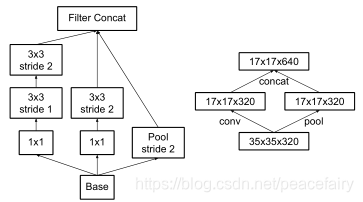
池化操作降低特征图大小,本文使用两个并行的步长为2的模块, P(池化) 和 C(卷积)。然后将两个模型的结果concat到一起,来更多的降低计算量
6、Inception V2

7、基于标签平滑的模型正则化(LSR)
这里我们提出了一种机制,通过估计训练过程中标签丢弃的边际效应来规范分类器层。
没有搞懂这一步要干什么
8、训练方法
9、低分辨率图像的识别
视觉网络的典型用例是用于检测的后期分类,例如在Multibox [4]上下文中。这包括分析在某个上下文中包含单个对象的相对较小的图像块。任务是确定图像块的中心部分是否对应某个对象,如果是,则确定该对象的类别。这个挑战的是对象往往比较小,分辨率低。这就提出了如何正确处理低分辨率输入的问题。
普遍的看法是,使用更高分辨率感受野的模型倾向于导致显著改进的识别性能。然而,区分第一层感受野分辨率增加的效果和较大的模型容量、计算量的效果是很重要的。如果我们只是改变输入的分辨率而不进一步调整模型,那么我们最终将使用计算上更便宜的模型来解决更困难的任务。当然,由于减少了计算量,这些解决方案很自然就出来了。为了做出准确的评估,模型需要分析模糊的提示,以便能够“幻化”细节。这在计算上是昂贵的。因此问题依然存在:如果计算量保持不变,更高的输入分辨率会有多少帮助。确保不断努力的一个简单方法是在较低分辨率输入的情况下减少前两层的步长,或者简单地移除网络的第一个池化层。
如果只是单纯地按照输入分辨率减少网络尺寸,那么网络的性能就会差得多
10、实验结果和比较
11、结论
- 提出了扩展卷积网络的四个原则
- 我们已经研究了在神经网络中如何分解卷积和积极降维可以导致计算成本相对较低的网络,同时保持高质量。较低的参数数量、额外的正则化、批标准化的辅助分类器和标签平滑的组合允许在相对适中大小的训练集上训练高质量的网络。

















 300
300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









