







一、主题:Spark RDD 求员工工资总额及排名
问题提出:近三年来,全球新冠疫情已经严重影响了现有经济情况,公司高层领导对公司运行情况进行深入了解,需要了解每个部门的人力成本,以至于更加合理的优化人力资源配置,最大程度的开源节流。根据项目实际需要,要求使用Spark RDD 求各部门员工工资总额,以及按照各部门的人力成本进行排序。
二、需求:
任务1、根据员工工资表(emp.csv),求出各部门员工总工资
任务2、对各部门工资开销情况按部门进行排序(升序)
任务3、对各部门工资开销情况,按照部门员工总工资进行排序(升序)
三、问题解决:
1、读取员工工资表(emp.csv)
2、获取员工工资信息和部门信息
3、对各部门工资进行汇总
4、按部门进行排序(升序)
测试数据:
一、回顾上一节课的内容:
1、程序框架的搭建
2、Spark程序的运行的必要条件
二、需求分析
1、分析工资表(哪一列是工资,哪一列是部门)
2、根据工资表的数据,分析如何求出总工资,
3、根据工资表的数据,分析如何按照部门编号排序
三、基本思路
1、读取文件
2、提取相关字段(F,H)
3、映射成键值对(部门,工资)
4、汇聚
5、排序
6、结果输出
四、需求实现
1、创建单例对象
2、入口函数
3、创建CONF
4、创建SC
5、读取文件创建RDD
6、切分(“,”)
7、提取下标5,7字段
8、映射成键值对(部门,工资)
9、汇聚
10、排序
11、结果输出
12、关闭资源
五、可选择的算子:
1、textFile
2、split
3、map
4、reduceByKey
5、sortByKey
6、 collect
7、foreach
六、布置任务
任务3、对各部门工资开销情况,按照部门员工总工资进行排序(升序)
七、下节课预告
1、如何将RDD写入MySQL数据库
2、Spark SQL基础操作实验课
参考代码:
import org.apache.spark.{SparkConf, SparkContext}
object EmpSalByDeptNo {
def main(args: Array[String]): Unit = {
//1、创建conf 和 sc
val conf = new SparkConf().setAppName("EmpSalByDeptNo").setMaster("local[2]")
val sc = new SparkContext(conf)
// 2.业务逻辑(重点)
sc.textFile("file:///D:\\temp\\emp.csv")
.map(x => {
val strings = x.split(",")
val sal = strings(5).toInt
val deptNo = strings(7).toInt
(deptNo,sal)
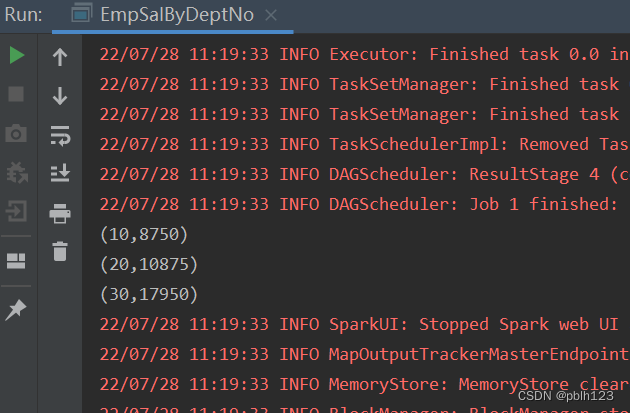
}).reduceByKey(_+_).sortByKey(ascending = true).collect().foreach(println)
//3.关闭资源
sc.stop()
}
}


















 445
445

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









