



数据简介
电影票房是衡量一部电影商业表现的重要指标,通常指电影的售票收入。其受到多种因素的影响,包括影片质量、宣传力度、观众口碑、上映时间、同期竞争等。因此,电影票房数据会随着时间、地区等因素的变化而波动。
数据名称:电影票房数据
数据年份:2015-2025年
指标:
排名 片名 上映年份 票房(万元) 平均票价 场均人次 上榜年份
数据截图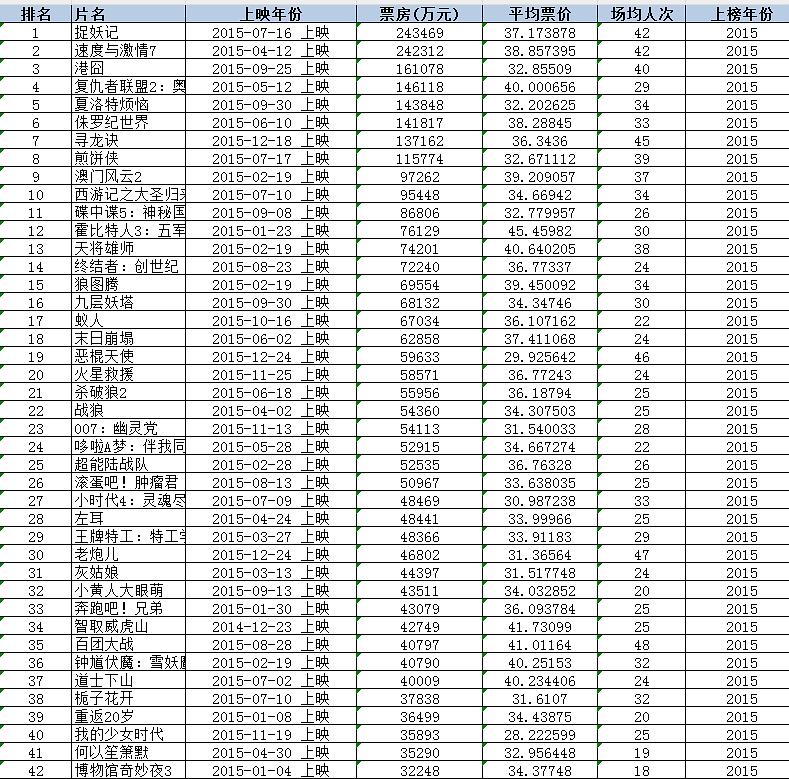
【下载→
方式一(推荐):主页 ↓个人↓简介
方式二:数据下载地址汇总_-优快云博客
数据简介
电影票房是衡量一部电影商业表现的重要指标,通常指电影的售票收入。其受到多种因素的影响,包括影片质量、宣传力度、观众口碑、上映时间、同期竞争等。因此,电影票房数据会随着时间、地区等因素的变化而波动。
数据名称:电影票房数据
数据年份:2015-2025年
指标:
排名 片名 上映年份 票房(万元) 平均票价 场均人次 上榜年份
数据截图
【下载→
方式一(推荐):主页 ↓个人↓简介
方式二:数据下载地址汇总_-优快云博客
 1669
1669

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























