







 本文详述了一个基于Node.js的实验,实现了数据爬取后的处理、数据库存储、路由创建、图表展示及页面设置。通过MySQL存储用户、新闻和行为数据,并利用Echarts制作图表。过程中遇到数据库安装问题,最终在朋友帮助下完成部分功能。
本文详述了一个基于Node.js的实验,实现了数据爬取后的处理、数据库存储、路由创建、图表展示及页面设置。通过MySQL存储用户、新闻和行为数据,并利用Echarts制作图表。过程中遇到数据库安装问题,最终在朋友帮助下完成部分功能。
一、实验内容
基于第一个项目爬虫爬取的数据(3-5
个数据源),完成数据展示网站。
基本要求:
1
、用户可注册登录网站,非注册用户不可登录查看数据
2
、用户注册、登录、查询等操作记入数据库中的日志
3
、实现
查询词支持
布尔表达式 (比如“新冠
AND
肺炎
”
或者“新冠
OR
肺炎”)
4
、爬虫数据查询结果列表支持分页和排序
5
、用
Echarts
或者
D3
实现
3
个以上的数据分析图表展示在网站中
扩展要求(非必须):
1
、实现对爬虫数据中文分词的查询
2
、实现查询结果按照主题词打分的排序
3
、用
Elastic
Search+Kibana
展示爬虫的数据结果
(因为时间和能力问题,扩展要求这里这次并没有涉及)
二、实验实现过程
注:需要安装的包上次已经安装过了
npm install -g express
npm install -g nodejieba以下是对于助教代码的理解、修改、添加后自己运行的产物
1.处理之前爬取的数据
对mysql进行了定义确认
module.exports = {
mysql: {
host: '127.0.0.1',
user: 'root',
password: 'root',
database:'test',
// 最大连接数,默认为10
connectionLimit: 10
}
};
//127.0.0.1代表本地的mysql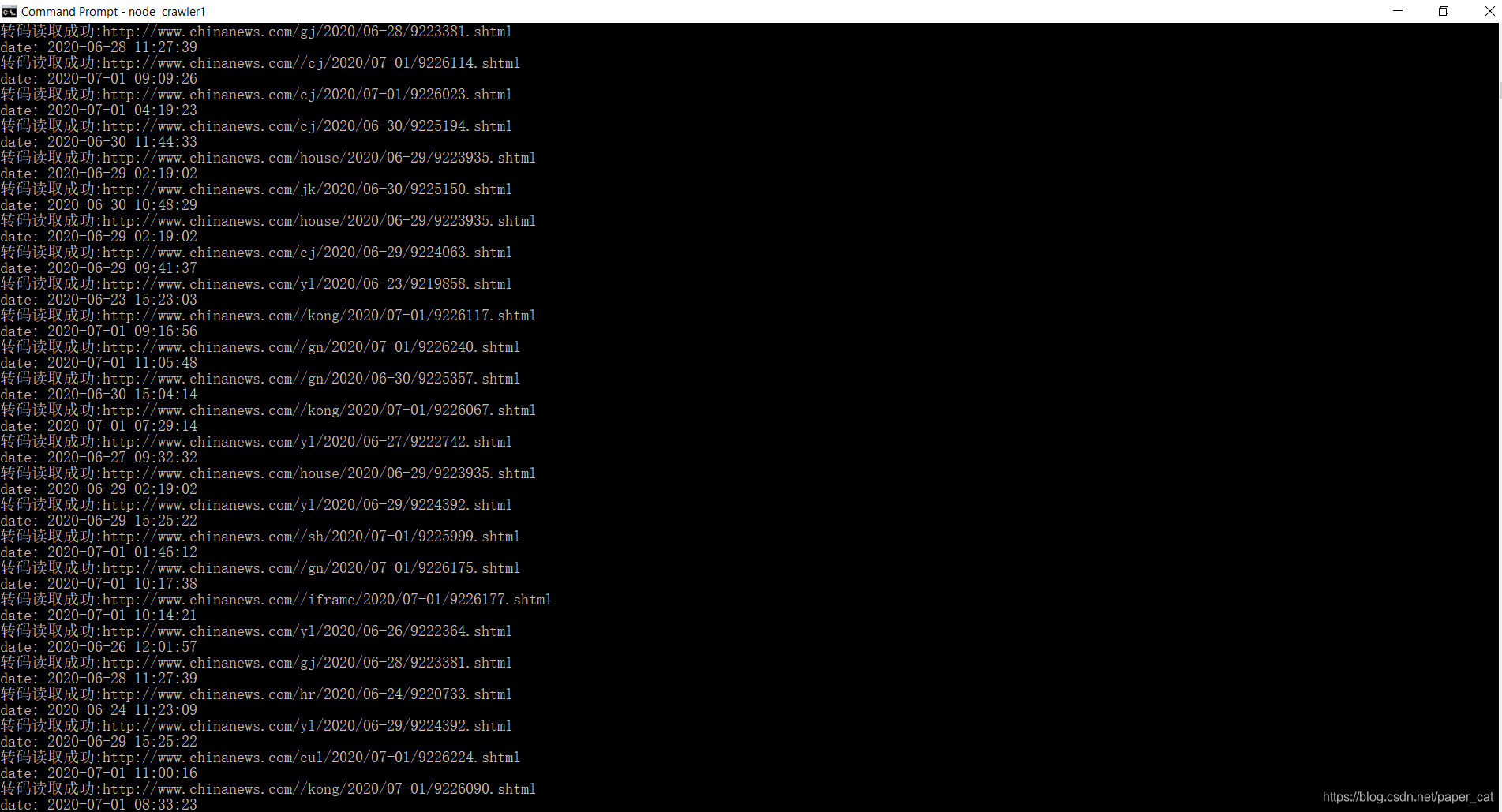
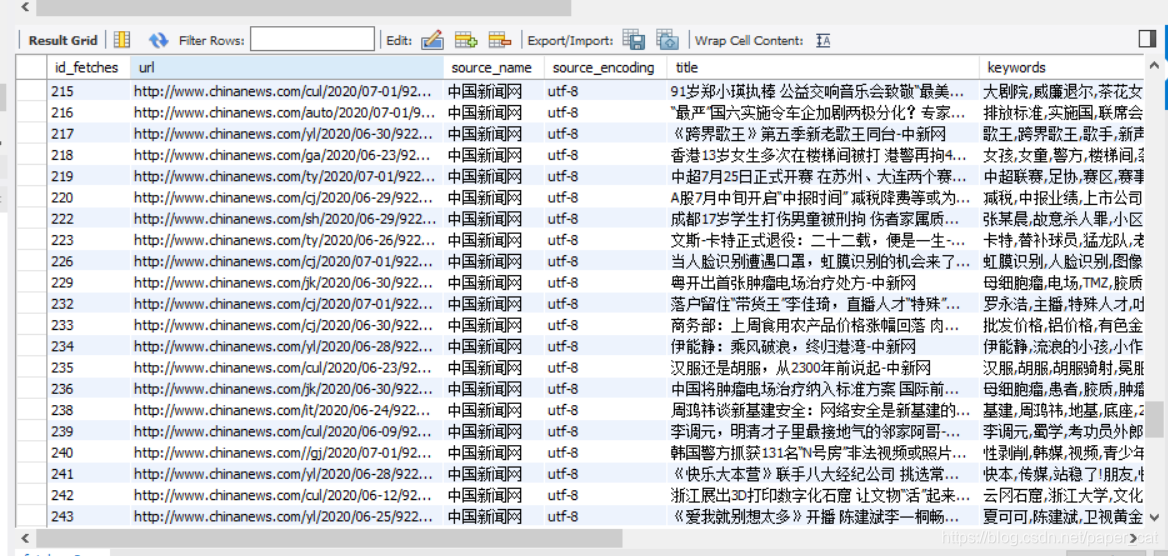
图中是上次作业中爬虫cmd的运行过程以及进入数据库的运行图。
接着,在mysql中创建三个表单,分别记录用户数据(用户ID、昵称、密码(MD5)、权限、账户余额等信息)、新闻数据(URL、标题、内容、编辑、来源等信息)以及用户具体行为(登录、查询等操作):
--之前的新闻数据表
CREATE TABLE `fetches` (
`id_fetches` int(11) NOT NULL AUTO_INCREMENT,
`url` varchar(200) DEFAULT NULL,
`source_name` varchar(200) DEFAULT NULL,
`source_encoding` varchar(45) DEFAULT NULL,
`title` varchar(200) DEFAULT NULL,
`keywords` varchar(200) DEFAULT NULL,
`author` varchar(200) DEFAULT NULL,
`publish_date` date DEFAULT NULL,
`crawltime` datetime DEFAULT NULL,
`content` longtext,
`createtime` datetime DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id_fetches`),
UNIQUE KEY `id_fetches_UNIQUE` (`id_fetches`),
UNIQUE KEY `url_UNIQUE` (`url`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
--创建用户信息数据表
CREATE TABLE `crawl`.`user` (
`id` INT UNSIGNED NOT NULL AUTO_INCREMENT,
`username` VARCHAR(45) NOT NULL,
`password` VARCHAR(45) NOT NULL,
`registertime` datetime DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
UNIQUE KEY `username_UNIQUE` (`username`))
ENGINE=InnoDB DEFAULT CHARSET=utf8;
--记录用户的登陆,查询(具体查询语句)操作
CREATE TABLE `crawl`.`user_action` (
`id` INT UNSIGNED NOT NULL AUTO_INCREMENT,
`username` VARCHAR(45) NOT NULL,
`request_time` VARCHAR(45) NOT NULL,
`request_method` VARCHAR(20) NOT NULL,
`request_url` VARCHAR(300) NOT NULL,
`status` int(4),
`remote_addr` VARCHAR(100) NOT NULL,
PRIMARY KEY (`id`))
ENGINE=InnoDB DEFAULT CHARSET=utf8;2.创建路由
创造一个调用数据的路径(路由),来让网页与服务器连接。以下是调用搜索新闻数据、图表的路径:
var newsDAO = require('../dao/newsDAO');
var express = require('express');
var router = express.Router();
router.get('/search', function(request, response) {
console.log(request.session['username']);
//sql字符串和参数
if (request.session['username']===undefined) {
// response.redirect('/index.html')
response.json({message:'url',result:'/index.html'});
}else {
var param = request.query;
newsDAO.search(param,function (err, result, fields) {
response.json({message:'data',result:result});
})
}
});
router.get('/histogram', function(request, response) {
//sql字符串和参数
console.log(request.session['username']);
//sql字符串和参数
if (request.session['username']===undefined) {
// response.redirect('/index.html')
response.json({message:'url',result:'/index.html'});
}else {
var fetchSql = "select publish_date as x,count(publish_date) as y from fetches group by publish_date order by publish_date;";
newsDAO.query_noparam(fetchSql, function (err, result, fields) {
response.writeHead(200, {
"Content-Type": "application/json",
"Cache-Control": "no-cache, no-store, must-revalidate",
"Pragma": "no-cache",
"Expires": 0
});
response.write(JSON.stringify({message:'data',result:result}));
response.end();
});
}
});
router.get('/pie', function(request, response) {
//sql字符串和参数
console.log(request.session['username']);
//sql字符串和参数
if (request.session['username']===undefined) {
// response.redirect('/index.html')
response.json({message:'url',result:'/index.html'});
}else {
var fetchSql = "select author as x,count(author) as y from fetches group by author;";
newsDAO.query_noparam(fetchSql, function (err, result, fields) {
response.writeHead(200, {
"Content-Type": "application/json",
"Cache-Control": "no-cache, no-store, must-revalidate",
"Pragma": "no-cache",
"Expires": 0
});
response.write(JSON.stringify({message:'data',result:result}));
response.end();
});
}
});
router.get('/line', function(request, response) {
//sql字符串和参数
console.log(request.session['username']);
//sql字符串和参数
if (request.session['username']===undefined) {
// response.redirect('/index.html')
response.json({message:'url',result:'/index.html'});
}else {
var keyword = '疫情'; //也可以改进,接受前端提交传入的搜索词
//var fetchSql = "select content,publish_date from fetches where content like'%" + keyword + "%' order by publish_date;";
var fetchSql = "select count(1) as y,publish_date as x from fetches where content like'%" + keyword + "%' group by publish_date order by publish_date;";
newsDAO.query_noparam(fetchSql, function (err, result, fields) {
response.writeHead(200, {
"Content-Type": "application/json",
"Cache-Control": "no-cache, no-store, must-revalidate",
"Pragma": "no-cache",
"Expires": 0
});
response.write(JSON.stringify({message:'data',result:result}));
response.end();
}); 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 418
418

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









