







XML
概念
什么是XML?
XML (Extensible Markup Language) 可扩展标记语言
什么是可扩展?
可扩展的意思就是是标签可以自定义的;例如<people> </people>
有什么功能?
它常用与存储数据;例如配置文件中;再例如也用在网络中传输
语法
基本语法
- xml文档的后续名就为
.xml - xml的行必须定义为文档声明;例如下面声明了版本为1.0
<?xml version="1.0"?>
- xml文档中
有且仅有一个根标签;例如下面的<users>就是根标签
<?xml version="1.0"?>
<users>
<user id="1">
.
.
</user>
<user number="2">
.
.
</user>
</users>
- 属性值必须用引号(或者是单引号)引起来
- 标签必须要正确关闭;也可以使用自闭合标签;和HTML一样
- xml标签是区分大小写的;这一点要注意
组成部分
- 文档声明格式:
<?xml 属性列表 ?>
属性列表可以有:version(版本号/必须的属性);encoding(编码方式/告知浏览器使用的字符集);standalone(是否独立)
通常standalone都不用设置的;需要设置时它的值只有yes或no
<?xml version="1.0" encoding="utf-8"?>
- 指令:可以结合css对样式进行修改;这个用处不大
<?xml-stylesheet type="text/css" href="a.css" ?>
-
标签:自定义标签时需要注意的是不用数字开头和xml开始和名称中不能含有空格
-
属性:要注意id属性值唯一即可
-
文本:有一个叫纯文本区
<?xml version="1.0" encoding="utf-8" ?>
<users>
<user id="1">
<name>tony</name>
<age>23</age>
<gender>male</gender>
<![CDATA[
<age>24</age>
<gender>male</gender>
]]>
</user>
</users>
用浏览器打开查看时:

约束
什么是约束?
约束就是规定了xml文档的书写规则;没有约束的话由于是自定义就会导致数据的混乱以及出错
如果是作为框架的使用者那么我们只需要知道怎么引入约束文档以及能简单懂得即可
约束文档的分类
-
DTD:一种简单的约束技术
-
Schema:一种复杂的约束技术
DTD
内部dtd:将约束约束规则定义在xml文档中
外部dtd分为两种:
本地:
<!DOCTYPE 根标签名 SYSTEM "dtd文件的位置">
网络:
<!DOCTYPE 根标签名 PUBLIC "dtd文件名字" "dtd文件的位置URL">
例如一个dtd约束文件
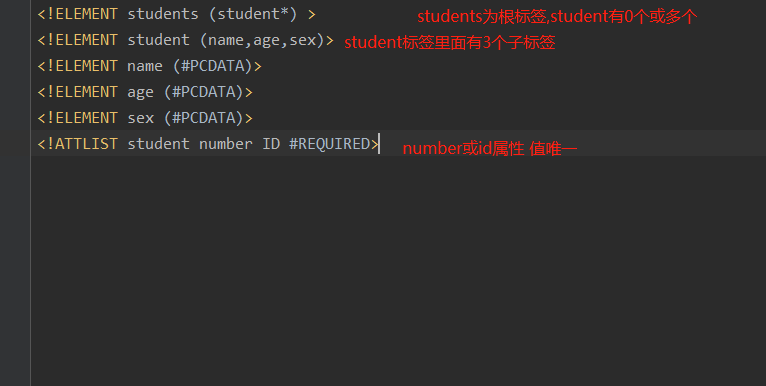
<?xml version="1.0" encoding="utf-8" ?>
<!DOCTYPE students SYSTEM "student.dtd"> //使用本地dtd引入
<students>
<student number="s1">
<name>tony</name>
<age>12</age>
<sex>male</sex>
</student>
</students>
Schema
Schema文件的后缀名是.xsd;它之所以比dtd复杂是因为约束的细节更多了;这使得数据更加严谨
例如一个.xsd文档
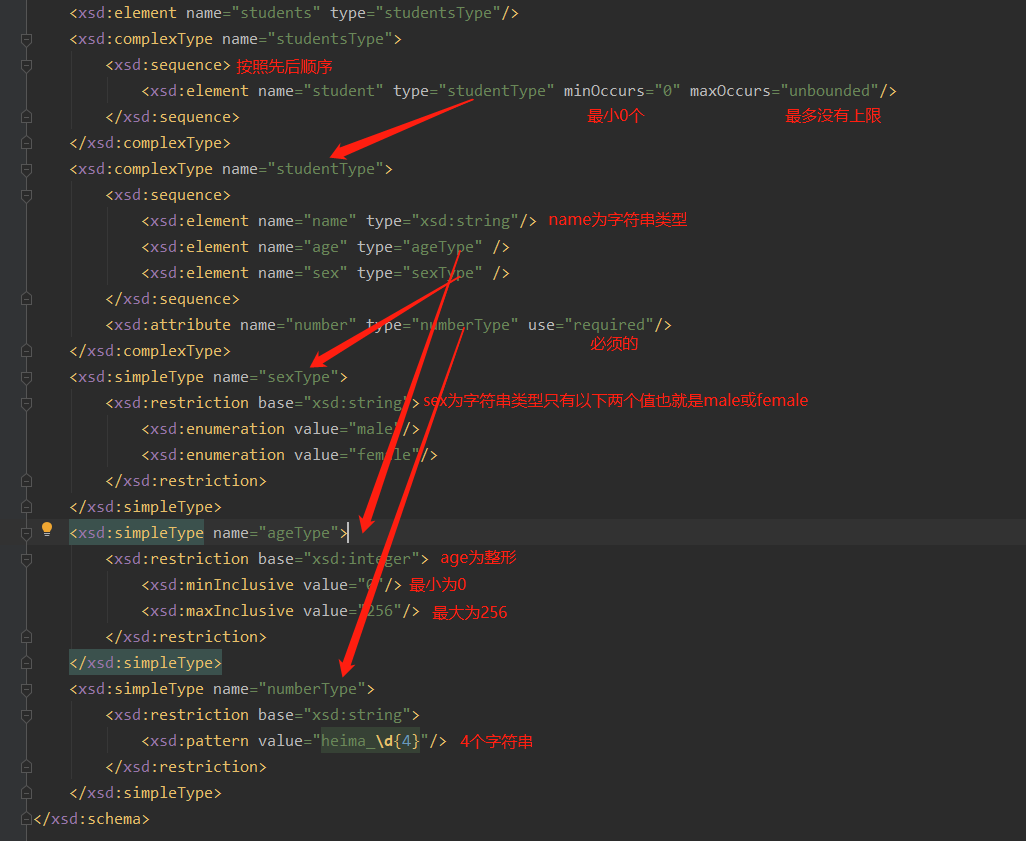
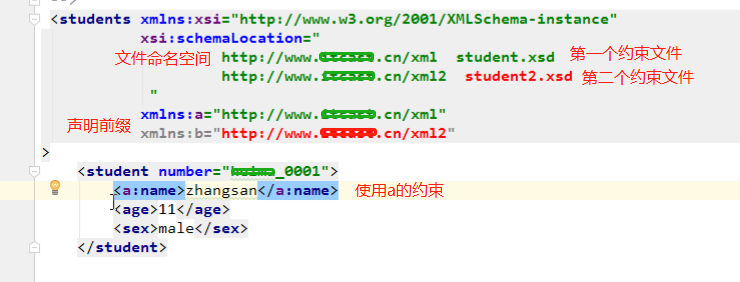
关于引入xsd文档:
- 填写xml文档的根元素
- 引入xsi前缀
- 引入xsd文件命名空间
- 为每一个xsd约束声明一个前缀
解析
什么是解析?
解析就是对xml文档进行操作;将文档中的数据读取到内存中;还可以将内存中的数据保存到xml文档中
解析xml的方法
解析xml的方法有两种:DOM;SAX
DOM:将标记语言文档一次性加载进内存然而形成一个dom树;操作方便但是比较占内存;可以增删改查
SAX:逐行读取;不占内存但是不能增删改
常见的xml解析器
这里介绍Jsoup;jsoup是java的HTML解析器;可以解析出某个url地址和html文本内容;还提供了省力的API
可以通过DOM和CSS以及类似jquery的操作方法来取出和操作数据
如何使用Jsoup
首先同样需要导入jar包 Jsoup ;提取码:2aih
导入jar包这个基本操作就不再细说了
然后获取Document对象;获取document对象之前首先要找到xml的path然后;然后使用parse方法进行解析xml文件;例如
String path = Jsoup_demo2.class.getClassLoader().getResource("example.xml").getPath();//利用类加载器获取路径
Document document = Jsoup.parse(new File(path), "utf-8"); //解析xml文件
有了document对象就可获取标签element对象
Elements name = document.getElementsByTag("name"); //返回的是一个集合
Element element = name.get(0); //获取第一个
String text = element.text(); //获取纯文本内容
System.out.println(text); //输出纯文本内容
各个对象使用的方法
Jsoup;这个类是一个工具类;可以解析xml文档或解析html文档;返回Document
| 方法名 | 说明 |
|---|---|
| parse(File in, String charsetName) | 解析xml或html文件的。 |
| parse(String html) | 解析xml或html字符串 |
parse(URL url, int timeoutMillis) | 通过网络路径获取指定的html或xml的文档对象 |
Document;文档对象;代表内存中的dom树;用来获取Element对象
| 方法名 | 说明 |
|---|---|
| getElementById(String id) | 根据id属性值获取唯一的element对象 |
| getElementsByTag(String tagName) | 根据标签名称获取元素对象集合 |
| getElementsByAttribute(String key) | 根据属性名称获取元素对象集合 |
| getElementsByAttributeValue(String key, String value) | 根据对应的属性名和属性值获取元素对象集合 |
Elements;Element对象的集合可以当将它看成ArrayList<Element>来使用
Element;元素对象;可以使用上述文档对象的方法来获取子元素对象
获取属性值
| 方法名 | 说明 |
|---|---|
| String attr(String key) | 根据属性名称获取属性值 |
获取文本内容
| 方法名 | 说明 |
|---|---|
| String text() | 获取文本内容 |
| String html() | 获取标签体的所有内容(包括字标签的字符串内容) |
要注意的是:html()使用获取包括标签在内的内容
Node;节点对象;它是Document和Element的父类
快速查询方式
由于通过上述的方法进行查询要进行非常多的步骤;那么可以采用以下方式进行快速查询
selector;选择器
例如获取所有name标签:
Elements name = document.select("name"); //返回所有name标签的集合
再例如获取id值为1的标签
Elements select = document.select("#1");
再再例如获取number属性值为2的user下的子标签age:
Elements select = document.select("user[number=\"2\"]> age");
Xpath
什么是Xpath?
Xpath是XML路径语言;它是用来用确定XML文档中某部分位置的语言
它需要导入jar包:Xpath 提取码:1z6f
导包完成后需要通过一个document对象来创建JXDocument对象;例如
JXDocument jxDocument = new JXDocument(document);
有了jxDocument 对象就可以查询;
例如查询含有id属性的user标签:
List<JXNode> jxNodes = jxDocument.selN("//user[@id]");
跟多的Xpath语法可以查看:W3School的Xpath参考手册


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









