



目录
库存系统架构设计
- 可用库存=现货库存-预占库存-锁定库存
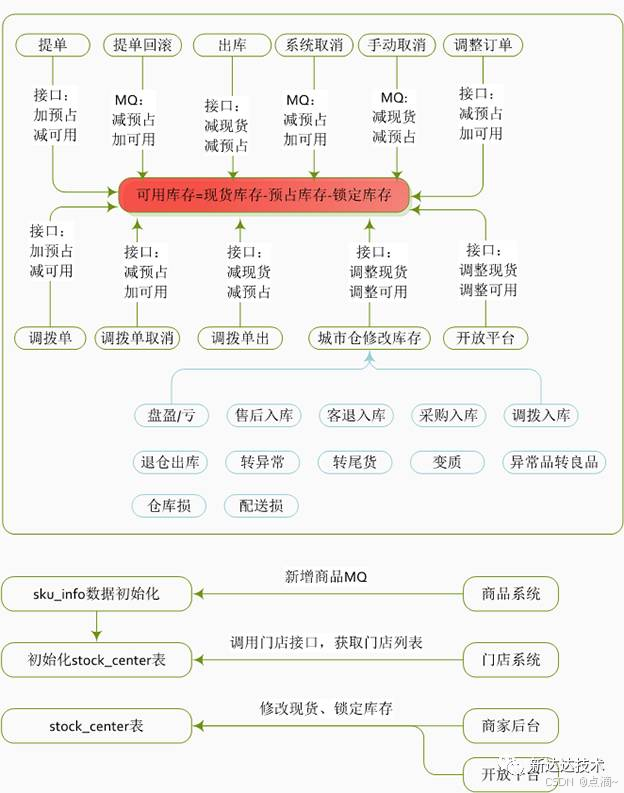
- 库存什么时候进行预占(或者扣减)呢? 提交订单时进行库存预占。
- 重复提交订单的问题?(1、用户善意行为)app侧在用户第一次单击“提交订单”按钮后对按钮进行置灰,禁止再次提交订单(2、用户恶意行为)采用令牌机制,用户每次进入结算页,提单系统会颁发一个令牌ID(全局唯一),当用户点击“提交订单”按钮时发起的网络请求中会带上这个令牌ID,这个时候提单系统会优先进行令牌ID验证,令牌ID存在&令牌ID访问次数=1的话才会放行处理后续逻辑,否则直接返回(3、提单系统重试)这种情况则需要后端系统(比如库存系统)来保证接口的幂等性,每次调用库存系统时均带上订单号,库存系统会基于订单号增加一个分布式事务锁
- 库存数据的回滚机制如何做?库存回滚的场景:(1、用户未支付)用户下单后后悔了(2、用户支付后取消)用户下单&支付后后悔了(3、风控取消)风控识别到异常行为,强制取消订单(4、耦合系统故障)比如提交订单时提单系统T1同时会调用积分扣减系统X1、库存扣减系统X2、优惠券系统X3,假如X1,X2成功后,调用X3失败,需要回滚用户积分与商家库存。
- 其中场景1,2,3比较类似,都会造成订单取消,订单中心取消后会发送MQ出来,各个系统保证自己能够正确消费订单取消MQ即可。而场景4订单其实尚未生成,相对来说要复杂些,如上面提到的,提单系统T1需要主动发起库存系统X2、优惠券系统X3的回滚请求(入参必须带上订单号),X2、X3回滚接口需要支持幂等性。
- 其实针对场景4,还存在一种极端情况,如果提单系统T1准备回滚时自身也宕机了,那么库存系统X2、优惠券系统X3就必须依靠自己为完成回滚操作了,也就是说具备自我数据健康检查的能力,具体来说怎么实现呢?可以利用当前订单号所属的订单尚未生成的特点,可以通过定时任务,每次捞取40分钟(这里的40一定要大于容忍用户的支付时间)前的订单,调用订单中心查询订单的状态,确保不是已取消的,否则进行自我数据的回滚。即定时任务库存校对。
- 多人同时购买1件商品,如何安全地库存扣减? 可以在where条件里增加了and stockNum>="+requestBuyNum即可防止超卖的行为,不用使用悲观锁串行执行,先检查再更新,直接可以在SQL语句中判断。50%的流量将直接告诉其抢购失败。同一个用户,不允许多次抢购同一件商品。
参考:京东到家库存系统架构设计
库存系统的痛点
电商库存业务的查询量往往远大于写入数量,例如写入TPS在 500 的业务,QPS 查询数量级往往可以达到 3000,例如访问量极高的商品详情页面会展示商品库存,这将带来极高的查询并发,也给数据库带来极大的压力,将商品的库存数据从 MySQL异构到 Redis 中,是解决库存查询高并发的必然方案。这就带来一个问题,数据一致性问题,以及加减法扣减还是同步更新法?
虚拟电商领域中库存系统在高并发场景下的架构挑战及相关问题,包括秒杀场景下库存系统的难点与优化,如MySQL的死锁检测、AliSQL的排队思路;多商品库存扣减的一致性保证;库存扣减的幂等性;是否需要预占库存;库存接口的语义设计;记录库存余额还是售卖数量;下单扣减库存还是支付扣减库存;分时库存的实现;以及除商品库存外的其他库存类型等9个关键问题。
秒杀等高并发场景的库存系统难点
MySQL实现秒杀库存的瓶颈点:
在秒杀场景中,当大量用户同时抢购同一件商品时,需要同时更新商品库存。在使用InnoDB数据库时,通过行锁和死锁检测机制来确保数据并发的一致性。然而,由于大量的竞争和并发操作,行锁和死锁检测机制会导致数据库的CPU资源被短时间内占满,使得整个数据库几乎无法响应其他请求。可以考虑关闭死锁检测;阿里的AliSQL 也提供了排队的思路解决 MySQL 热点记录更新问题。(需要你在SQL中明确指定更新记录的ID,以让AliSQL知道在哪个记录上排队)
AliSQL是基于MySQL官方版本的一个分支,由阿里云数据库团队维护。宣称“在通用基准测试场景下,AliSQL版本比MySQL官方版本有着 70% 的性能提升。在秒杀场景下,性能提升 100倍”。
美团的MTSQL也使用排队思路解决热点记录更新问题。
多商品库存扣减如何保证一致性?
低并发场景:完全可使用MySQL事务保证库存操作的一致性。
高并发场景:
Redis单机模式,可以利用Lua脚本实现多个商品库存扣减的事务性;Redis Cluster集群模式,无法保证Lua脚本中多个Key的操作路由到一个节点,自然无法保证多Key操作的一致性。所以使用Lua脚本实现多商品库存修改,必须确保Redis不得使用Cluster集群模式。
使用 MTSQL、AliSQL 时,将多个商品的库存操作放到一个事务中,可保证同时成功和失败。方案更加简单,所以推荐高并发场景使用MTSQL、AliSQl实现库存方案,不推荐使用Redis。
如何保证库存扣减的幂等?
库存操作的SQL,如果重复执行会导致库存重复扣减。可以考虑在库存操作事务中,新增库存扣减流水,使用订单ID作为流水幂等键,当流水新增冲突时,则说明库存重复扣减,回滚事务即可。
先新增流水,再扣减库存?
AliSQL 支持在第三步,扣减库存时,自动提交事务,省却了一次网络开销。
同时,先扣减库存再增加流水,会导致行锁持有的时间更长,降低了库存扣减并发度。新增库存流水在前,新增流水时,还未锁定 库存行锁,其他事务可扣减库存,这样并发度更高。
是否需要预占库存?
虚拟商品库存无需预占库存。实物商品库存领域需要预占库存。
预占库存是实物商品库存领域的设计,用户下单完成库存预占,仓储系统发货后释放预占库存,预占库存可以监控已下单未发货库存量。由于实物商品下单完成到发货完成有一段较长的时间窗口,并且为了更好的监控未发货库存数量,设计出预占库存这样一个概念。虚拟商品领域库存不存在发货这个动作,直接扣减库存就完事,整预占库存这个概念,徒增系统理解难度。
如何设计库存接口的语义?
不需要设置预占库存。没有预占库存后,库存接口只有两个,扣减库存和回滚库存。这两个接口如何设计接口语义呢?换句话说,上游调用这两个接口何时为成功,何时为失败呢?
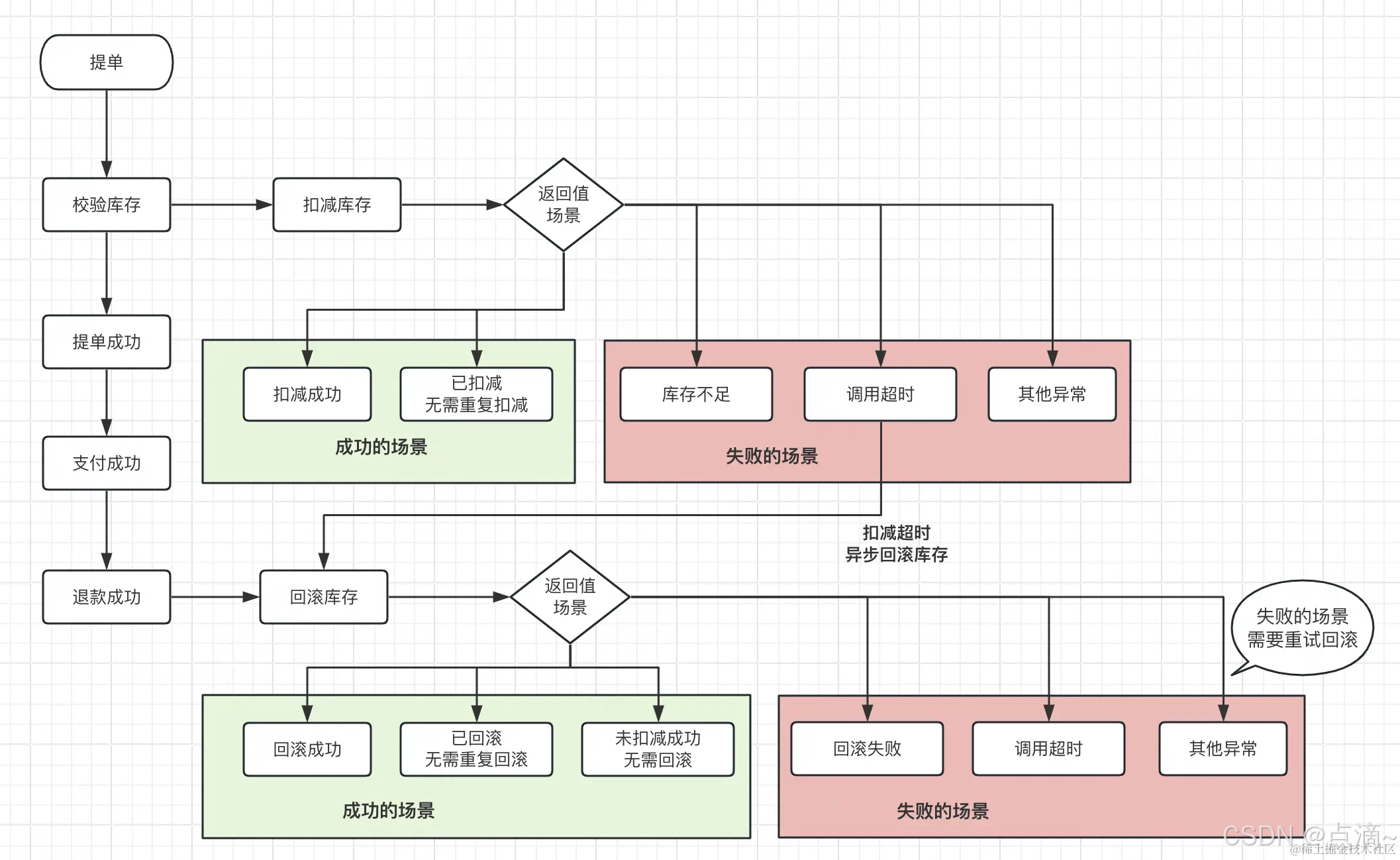
库存扣减返回值处理
库存扣减的返回场景和对应处理如下
| 库存扣减的返回场景 | 上游处理办法 |
|---|---|
| 库存扣减成功 | 上游认定:扣减成功 |
| 库存不足,扣减失败 | 上游认定:扣减失败 |
| 库存已扣减,无需重复扣减 | 上游认定:扣减成功 |
| 上游调用超时 | 上游认定:扣减失败 |
| 其他异常 | 上游认定扣减失败 |
扣减成功和库存不足失败的场景,上游分别认定为成功和失败处理即可,无需赘言。
如果上游调用扣减库存超时,应如何处理?重新扣减库存还是直接认定失败。两者都可以,但是要区分场景。
对时间不敏感的场景
当调用扣减库存超时,如果是时间不敏感的场景,例如异步发券等,可以考虑通过重试接口,获取准确的结果。一般情况下,库存都是充足的,接口超时的时候,大多数重试扣减都是可以扣减成功的。
对时间敏感的场景
当调用扣减库存超时,如果库存接口上游对时间比较敏感,调用库存扣减超时,则认定为失败。
例如提单扣减库存接口对耗时极为敏感。因为提单接口调用链路非常复杂,往往需要很多次下游接口调用和数据库调用,所以提单接口的耗时较长。同时提单时间太长,对用户影响非常大。当提单阶段扣减库存超时了,就应该认定为库存扣减失败,终止提单即可。因为库存接口超时,说明提单接口耗时已经很长了,再次重试,则会雪上加霜,不如选择抛出异常,由用户发起重试提单。
调用库存扣减超时,认定为失败,还需要调用库存回滚接口,尝试回滚库存。因为接口超时时,无法确定库存是否扣减成功。 上游应该发消息,尝试异步回滚库存。
库存回滚接口返回值
除了扣减库存超时,需要异步回滚库存。其他场景,包括订单退款,也需要扣减库存。
库存接口的语义如下
| 库存回滚的返回场景 | 上游处理 |
|---|---|
| 回滚成功 | 认定为成功 |
| 已回滚,无需重试回滚 | 重试请求,认定成功 |
| 已回滚,无需重试回滚 | 重试请求,认定成功 |
| 回滚失败 | 重试回滚接口 |
| 上游收到超时 | 重试回滚接口 |
回滚库存接口应该保证,如果扣减成功,则立即回滚库存;如果扣减失败或未扣减,则回滚失败。
异步回滚库存时,如果调用接口超时,上游应该重试回滚;如果返回库存已回滚,则认定为回滚成功。
总之,异步回滚库存,应该通过重试,保证回滚接口返回 成功或重复回滚 两个返回值中的一个。
记录库存余额还是记录售卖数量?
推荐记录售卖数量。
使用库存余额更加复杂,并且没有明显的收益。
记录售卖数量的方案更加简单,调整库存更加简洁优雅,而且不会出现数据一致性问题。通过记录售卖数量,很容易就可以知道当前商品的已售卖数量。
下单扣减库存还是支付扣减库存?
最好使用下单扣减库存,确保用户体验,30分钟后未支付的订单自动取消,释放库存。
除商品库存外,还有其他库存吗?
在电商环境中,并非只有商品具备库存,很多资源实体都有库存。
例如用户领券时,当库存不足时,则无法领券,需要设置发券的库存。
例如售卖商品时,不同的渠道共用一个库存,此时库存的维度并非商品,而是渠道库存。
例如某个营销活动需要控制预算,需要配置活动库存,此时的库存维度并非商品,而是活动库存。
所以在原有的库存模型上,需要增加维度。
在查询和扣减库存时,我们需要额外指定所需库存资源的类型。如果客户端是商品库存场景,就需要指定资源类型为商品;如果客户端是活动库存场景,就需要指定资源类型为活动。通过新增资源类型,我们可以实现多种业务场景共用一个库存系统。
参考:https://juejin.cn/post/7313776114912182313
加减法扣减 Redis 库存
使用加减法扣减 Redis 库存的时机在 MySQL 库存被更新后。一般情况下各个公司都有 MySQL binlog 的订阅消费能力,所以通过监听库存表的binlog 变更即可。当出现一次更新时,获取当前扣减的数量,则扣减相应的 Redis 库存。
当 Redis 扣减出现超时,超时重试的时候如何保证幂等性呢?应该在 incrBy 时,同时新增一个幂等记录,例如订单 id。
更新库存时同步新增幂等记录
这个过程共有两次 Redis 操作。也可以使用更复杂的 Lua脚本方案,将以上操作统一放在 lua 脚本中执行。
但是要注意一个问题: pipeline 和 lua 脚本都只能使用单机版的 redis,不能使用 Redis 集群模式。因为 Redis 集群模式将全量数据 hash 到多个子节点, pipeline 和 lua 中操作的两个 key 无法保证在同一个节点上,也就无法保证操作的原子性。
设置合理过期时间
幂等记录设置合理的超时时间,比如1个小时。
长期的库存不一致问题。
使用加减法扣减库存,无法保证长期上完全一致。虽然引入幂等记录解决了超时重试带来的一致性问题,但是系统运行的长期时间里,难以保证两者是完全一致的。在某些异常场景,例如binlog 消息存在丢失,重复消费(间隔很短时)导致的重复扣减,系统宕机等等预料之外的问题,都有可能导致两者的数据不一致。 使用加减法扣减的方式,无法保证系统长期能一致,如果要做到这一点,就需要额外的校正极值,定期校正两者是否一致。
定期校正 Redis和 MySQL 的一致性
简单的方案是在系统的业务低峰期执行一个定时任务,对全量库存进行扫描和处理。例如,通过查询数据库和Redis中的库存A是否一致来判断Redis库存是否准确,若不一致,则强制更新Redis库存。
同步更新法扣减
同步扣减法即每次库存更新都 使用 set 命令覆盖 Redis 库存,不管是扣减库存还是回滚库存,统统使用 set 命令强制更新。
这种方式有一个好处,不用担心幂等问题。因为 Redis set 超时后,可以直接重试。不同于 incrBy 操作,执行多次会有不同的结果,set 命令不需要担心重试和幂等问题。
但是 同步更新法也有一致性问题,因为在库存扣减并发度非常高的时候,很难保证扣减的顺序性。
顺序消费带来的一致性问题
举个例子库存 A 的当前库存是 5,经过五次扣减后,分别变为 4,3,2,1,0。 很难保证这五条 binlog是顺序投递到 Kafka,也无法保证 Kafka 能顺序消费 5 个消息。如果没有顺序消费,5 次扣减完成后,Redis 最终的库存数据可能不是 0,而是其他 4 个值。
库存实际上已经没有了,Redis 库存还是非零值,用户能看到有库存,但是无法购买成功,这种用户体验很差。
所以要解决顺序扣减库存的难题。
生产端到消费端保证顺序
如果可以保证库存更新的 binlog 从发送到 Kafka 到消费能完全顺序,就可以保证Redis 库存更新也是有序的。可以通过创建一个分片,保证 Kafka 消费时顺序消费。然而如何保证 binlog 到 Kafka 是有序的呢? 这比较难,我们无法苛求 binlog 消费中间件(例如canal)顺序投递到 Kafka。
要想完全的顺序生产和消费是非常困难的,所以一般情况下我们采用方案 2,即版本号机制。
版本号控制顺序消费
一般情况下 mysql 库存更新的 SQL 会同步新增版本号,例如下面这个 SQL。
update inventory set cnt = cnt + #{buyCnt}, version=version+1 WHERE productId = #{productId1} AND cnt + #{buyCnt} <= totalCnt
这样每条 binlog 都带有对应的版本号,当更新库存时,先尝试检查当前版本号是否落后于 Redis 版本号,如果落后,那么说明无需更新,如果超前,则尝试更新 Redis 库存值和版本号。
这个过程是先检查再更新,需要保证一致性,可以使用 Lua 脚本。版本号和库存值需要存在 Redis 中,可以使用 redis hash 结构存储两个子 key。
如果存在,则校验 redis 版本号和当前传参的版本号,如果超过 redis 版本号,则立即更新库存。如果落后于 redis 库存,则不更新,返回-1 非法值。
| 方案 | 加减法扣减 | 同步更新法 |
|---|---|---|
| 缺点 | 需要保证重试和幂等、无法保证长期一致 | 难以保证同时修改版本号和库存值的原子性 |
| 补充方案 | 新增幂等记录保证幂等 2、定时任务保证长期一致 | 使用 lua 脚本保证同时成功和失败 |
- 在库存场景,查询的数量级要远高于写入的数量级。
- 库存查询能力基于 Redis 实现可以提供更强的查询性能,速度更快,扛并发能力更强
- 将MySQL数据库 库存同步到 Redis 中,可以使用同步更新法,即每当库存更新后,即将新库存值和版本号更新到 Redis 中,使用版本号和lua脚本控制顺序,保证Redis库存值是最新的,而不是历史值。
参考:https://juejin.cn/post/7336779196600107062?share_token=600992af-e524-405b-a8e7-9ba70645ff13


















 760
760

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









