



目录
水平切分
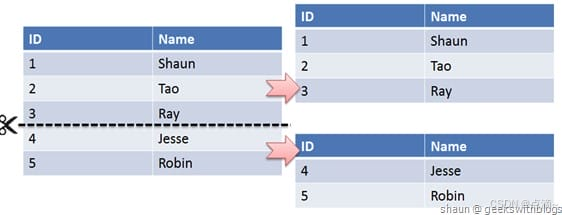
水平切分又称为 Sharding,它是将同一个表中的记录拆分到多个结构相同的表中。
当一个表的数据不断增多时,Sharding 是必然的选择,它可以将数据分布到集群的不同节点上,从而缓存单个数据库的压力。
垂直切分
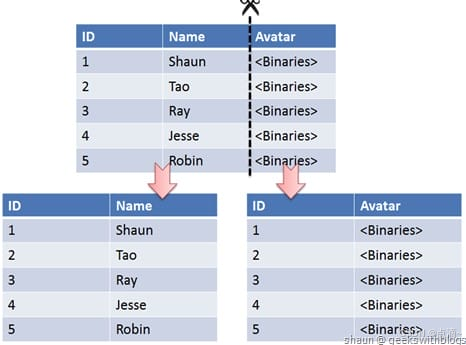
垂直切分是将一张表按列切分成多个表,通常是按照列的关系密集程度进行切分,也可以利用垂直切分将经常被使用的列和不经常被使用的列切分到不同的表中。
在数据库的层面使用垂直切分将按数据库中表的密集程度部署到不同的库中,例如将原来的电商数据库垂直切分成商品数据库、用户数据库等。
Sharding 策略
-
哈希取模: hash(key) % NUM_DB
-
范围: 可以是 ID 范围也可以是时间范围
-
映射表: 使用单独的一个数据库来存储映射关系
Sharding 存在的问题及解决方案
-
事务问题
使用分布式事务来解决,比如 XA 接口。
-
链接
可以将原来的 JOIN 分解成多个单表查询,然后在用户程序中进行 JOIN。
-
ID 唯一性
-
使用全局唯一 ID: GUID
-
为每个分片指定一个 ID 范围
-
分布式 ID 生成器 (如 Twitter 的 Snowflake 算法)
现有的分库分表中间件
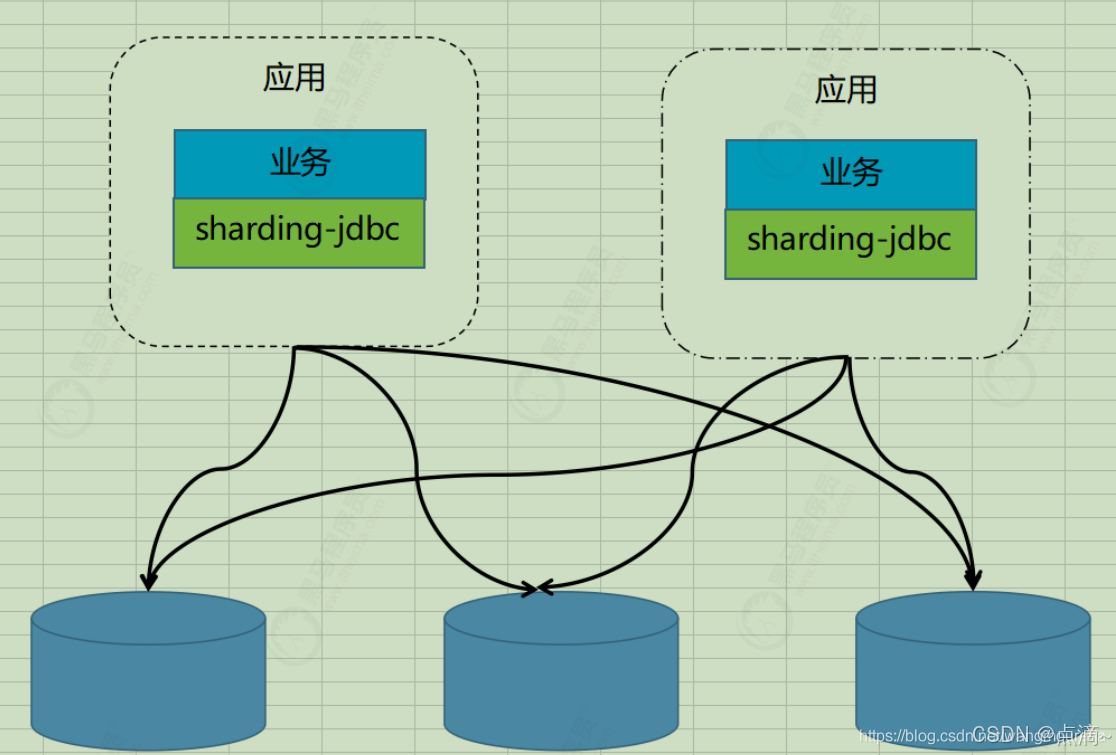
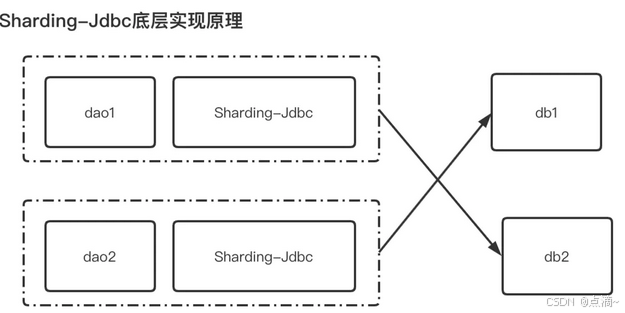
1、client客户端模式
代表有阿里的TDDL,开源社区的sharding-jdbc(sharding-jdbc的3.x版本即sharding-sphere已经支持了proxy模式)。
架构如下:
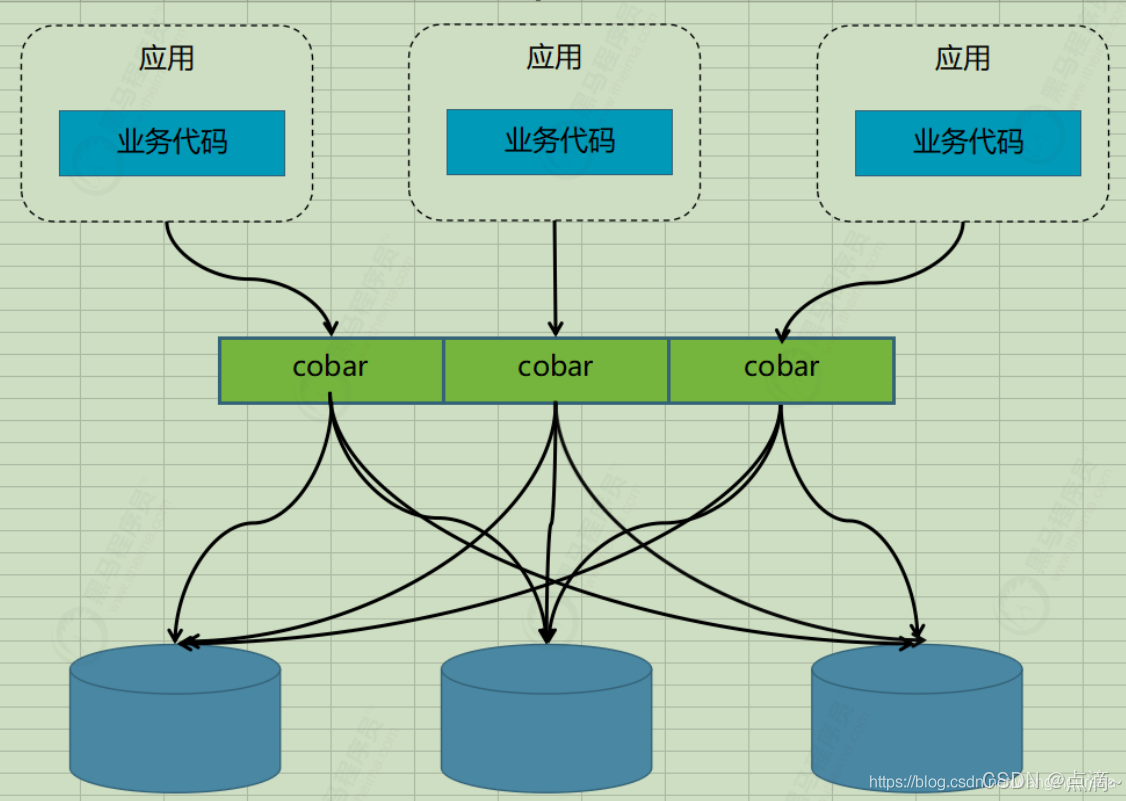
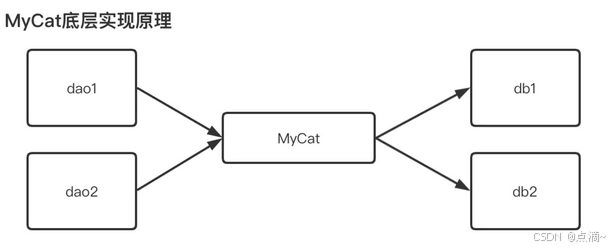
2、proxy代理模式:
代表有阿里的cobar,民间组织的MyCAT。架构如下:
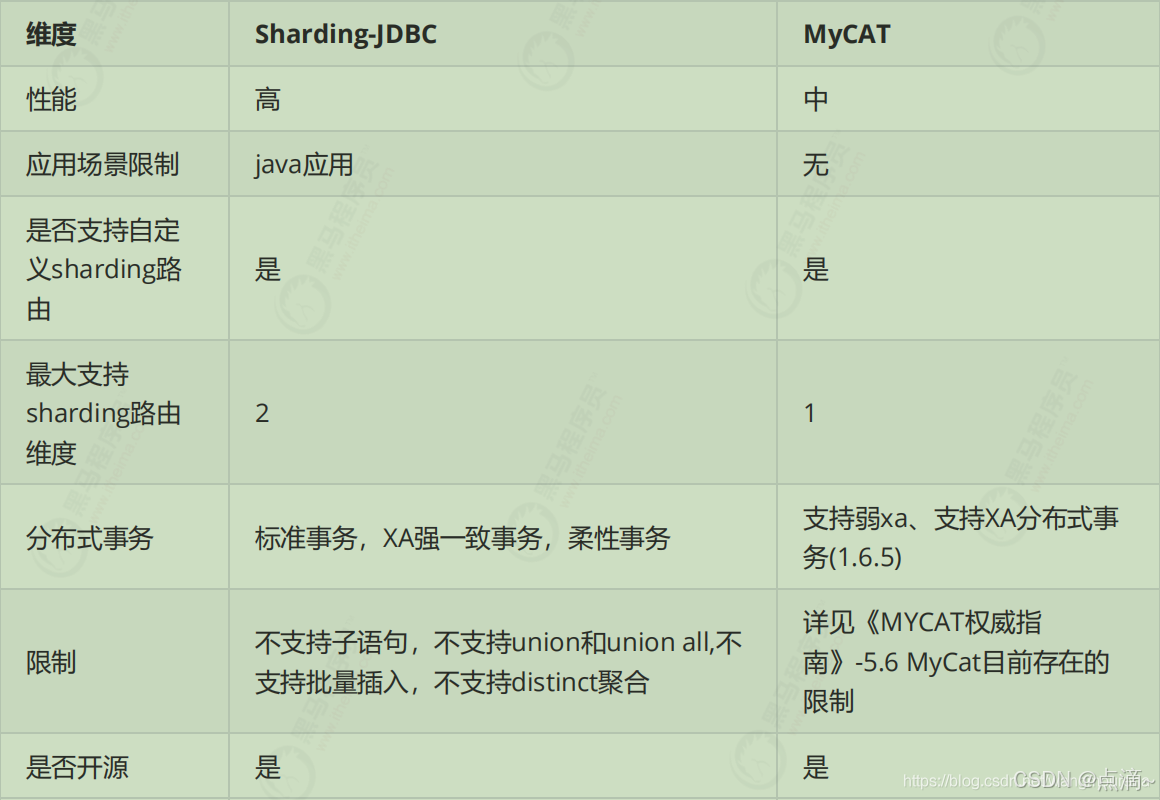
3、比对
从以上两种模式可以看出sharding-jdbc作为一个组件集成在应用内,而mycat则作为一个独立的应用需要单独部署。
但是,无论是client客户端模式,还是proxy代理模式。几个核心的步骤是一样的:SQL解析,重写,路由,执行,结果归并。
client模式,架构简单,性能损耗比较小,运维成本低。
mycat的单机模式无法保证可靠性,一旦宕机则服务就变得不可用,你又不得不引入HAProxy来实现他的高可用集群部署方案,为了解决HAProxy的高可用问题,有需要采用keepalived来实现。
分库分表后带来的问题及处理
分库分表,其在解决如 IO 瓶颈、读写性能、物理存储瓶颈、内存瓶颈、单机故障影响面等问题的同时,也带来如事务性、主键冲突、跨库 join、跨库聚合查询等问题。
无论如何,在综合业务场景考虑,正如缓存的使用一样,非必须使用分库分表,则不应过度设计采用分库分表方案。如数据库确实成为性能瓶颈时,在设计分库分表方案时也应充分考虑方案的扩展性。或者说可以考虑采用成熟热门的分布式数据库解决方案,如 TiDB。
实践参考
KnowledgePlanet / road-map / xfg-dev-tech-db-router · GitCode


















 2576
2576

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









