






 本文介绍如何使用sklearn库的决策树和随机森林模型进行预测,并展示了如何评估模型性能和可视化特征贡献度。通过泰坦尼克号幸存者数据集,详细解释了模型评估指标的计算方法及特征重要性的图形展示。
本文介绍如何使用sklearn库的决策树和随机森林模型进行预测,并展示了如何评估模型性能和可视化特征贡献度。通过泰坦尼克号幸存者数据集,详细解释了模型评估指标的计算方法及特征重要性的图形展示。
模型训练完成后,即使模型评估很好,各项指标都很到位,业务人员肯定也是心里没底的,哪怕有模型公式,他们也看不懂啊。咋整,当然是先把模型的重要评估指标打印给他们看,再把特征贡献度从大到小,画成图给他们看啦。今天就通过sklearn实现模型评估指标和特征贡献度的图形查看。
本文的数据集采用泰坦尼克号幸存者数据。使用sklearn的决策树和随机森林进行预测,然后查看模型的评估指标,最后将特征的贡献度从大到小以柱状图展示。
直接上代码:
# -*- coding: utf-8 -*-
# @Time : 2018/12/13 上午10:30
# @Author : yangchen
# @FileName: featureimportance.py
# @Software: PyCharm
# @Blog :https://blog.youkuaiyun.com/opp003/article
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, precision_recall_fscore_support
from sklearn.model_selection import train_test_split
#导入数据
df = pd.read_csv('processed_titanic.csv', header=0)
#设置y值
X = df.drop(["survived"], axis=1)
y = df["survived"]
#训练集和测试集划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=0, shuffle=True)
#训练模型
dtree = DecisionTreeClassifier(criterion="entropy", random_state=123,
max_depth=4,
min_samples_leaf=5)
dtree.fit(X_train, y_train)
# 预测
pred_train = dtree.predict(X_train)
pred_test = dtree.predict(X_test)
#准确率
train_acc = accuracy_score(y_train, pred_train)
test_acc = accuracy_score(y_test, pred_test)
print ("训练集准确率: {0:.2f}, 测试集准确率: {1:.2f}".format(train_acc, test_acc))
#其他模型评估指标
precision, recall, F1, _ = precision_recall_fscore_support(y_test, pred_test, average="binary")
print ("精准率: {0:.2f}. 召回率: {1:.2f}, F1分数: {2:.2f}".format(precision, recall, F1))
#特征重要度
features = list(X_test.columns)
importances = dtree.feature_importances_
indices = np.argsort(importances)[::-1]
num_features = len(importances)
#将特征重要度以柱状图展示
plt.figure()
plt.title("Feature importances")
plt.bar(range(num_features), importances[indices], color="g", align="center")
plt.xticks(range(num_features), [features[i] for i in indices], rotation='45')
plt.xlim([-1, num_features])
plt.show()
#输出各个特征的重要度
for i in indices:
print ("{0} - {1:.3f}".format(features[i], importances[i]))
核心代码:
importances = dtree.feature_importances_
indices = np.argsort(importances)[::-1]
第一行,是通过模型的feature_importances_方法获取特征贡献度。使用sklearn的算法都有这个方法。然后使用argsort对其进行排序,由于argsort排序是从小到大的,因此要用[::-1]进行倒序,得到从大到小的排序。
整个代码运行得到输出如下:
训练集准确率: 0.80, 测试集准确率: 0.79
精准率: 1.00. 召回率: 0.70, F1分数: 0.82
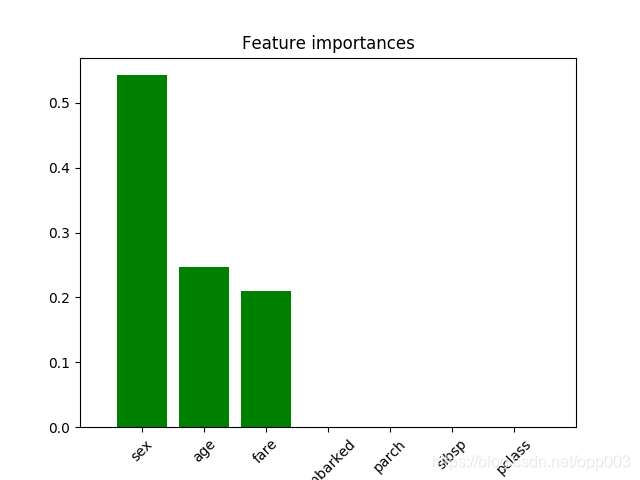
sex - 0.543
age - 0.247
fare - 0.211
embarked - 0.000
parch - 0.000
sibsp - 0.000
pclass - 0.000
特征贡献度图形如下:
另外,也可以使用score方法获取模型得分,但是参数得换下:
train_acc = dtree.score(X_train, y_train)
test_acc = dtree.score(X_test, y_test)
最后再来看下,使用随机森林的方法,表现如何:
# -*- coding: utf-8 -*-
# @Time : 2018/12/14 上午09:13
# @Author : yangchen
# @FileName: randomforests.py
# @Software: PyCharm
# @Blog :https://blog.youkuaiyun.com/opp003/article
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, precision_recall_fscore_support
from sklearn.model_selection import train_test_split
from sklearn import metrics
#导入数据
df = pd.read_csv('processed_titanic.csv', header=0)
#设置y值
X = df.drop(["survived"], axis=1)
y = df["survived"]
#训练集和测试集划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=0, shuffle=True)
#训练模型
forest = RandomForestClassifier(
n_estimators=10, criterion="entropy",
max_depth=4, min_samples_leaf=5)
forest.fit(X_train, y_train)
# 预测
pred_train = forest.predict(X_train)
pred_test = forest.predict(X_test)
#准确率
train_acc = accuracy_score(y_train, pred_train)
test_acc = accuracy_score(y_test, pred_test)
print ("训练集准确率: {0:.2f}, 测试集准确率: {1:.2f}".format(train_acc, test_acc))
#其他模型评估指标
precision, recall, F1, _ = precision_recall_fscore_support(np.array(y_test), np.array(pred_test), average='binary')
#特征重要度
features = list(X_test.columns)
importances = forest.feature_importances_
indices = np.argsort(importances)[::-1]
num_features = len(importances)
#将特征重要度以柱状图展示
plt.figure()
plt.title("Feature importances")
plt.bar(range(num_features), importances[indices], color="g", align="center")
plt.xticks(range(num_features), [features[i] for i in indices], rotation='45')
plt.xlim([-1, num_features])
plt.show()
#输出各个特征的重要度
for i in indices:
print ("{0} - {1:.3f}".format(features[i], importances[i]))
输出结果:
训练集准确率: 0.80, 测试集准确率: 0.75
precision: 0.83. recall: 0.81, F1: 0.82
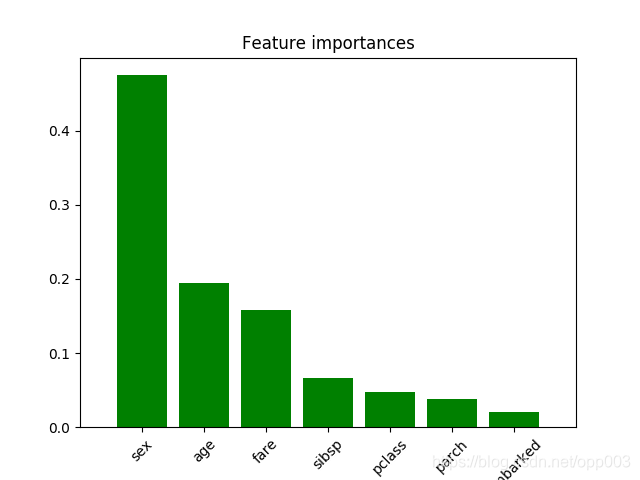
sex - 0.437
age - 0.300
fare - 0.176
pclass - 0.034
parch - 0.031
embarked - 0.016
sibsp - 0.007
特征贡献度图形如下:
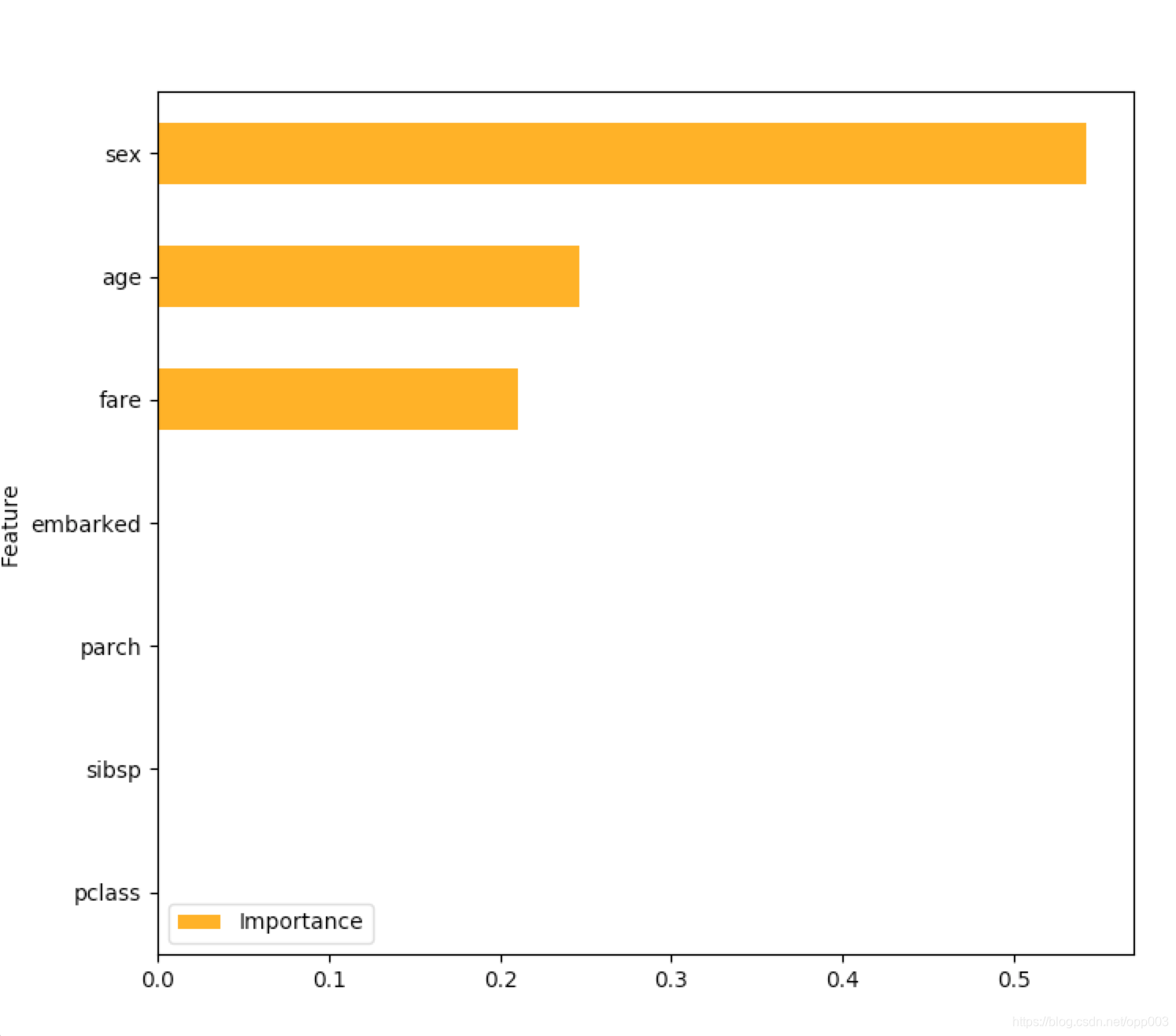
也可以这么写,来查看特征重要度:
(12-19补充另一种写法,由于数据出了问题,导致图形的不一致,主要看方法。。。)
features = list(X_test.columns)
importance_frame = pd.DataFrame({'Importance': list(dtree.feature_importances_), 'Feature': list(features)})
importance_frame.sort_values(by='Importance', inplace=True)
#importance_frame['rela_imp'] = importance_frame['Importance'] / sum(importance_frame['Importance'])
importance_frame.plot(kind='barh', x='Feature', figsize=(8, 8), color='orange')
plt.show()

















 882
882

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









