




 本文深入探讨了在模型未知的情景下,强化学习中的Monte Carlo(MC)方法的应用。主要内容包括MC方法估计状态值和动作状态值函数的原理,通过Blackjack游戏示例展示First-Visit与Every-Visit两种策略的实现细节。此外,还介绍了Monte Carlo ES算法及ε-soft策略在策略改进中的应用,并提供了详细的代码解释。
本文深入探讨了在模型未知的情景下,强化学习中的Monte Carlo(MC)方法的应用。主要内容包括MC方法估计状态值和动作状态值函数的原理,通过Blackjack游戏示例展示First-Visit与Every-Visit两种策略的实现细节。此外,还介绍了Monte Carlo ES算法及ε-soft策略在策略改进中的应用,并提供了详细的代码解释。
本文是看David Silver的强化学习视频的时候记的笔记,整理了视频的思路,补充了一些证明。写博客
开始MC方法。
前面对策略估计和改进都是在模型(转移概率 + 奖励)已知的情况下进行的。如果模型未知(model-free),怎么估计和改进策略呢?
从前面章节看,策略估计和改进的大致分两步:计算状态值和动作-状态值估计策略,然后在此基础上用贪婪算法改进策略;
先看看MC方法如何计算值函数:
1,MC计算值函数
MC通过学习的方法,计算值函数
样本:有终点的episodes;
学习方法:对episodes的return求均值;
2,状态值函数的估计
MC方法估计状态值函数有First-Visit和Every-Visit两种方法,不写了,看PPT,直接上代码;
3,First-Visit和Every-Visit估计状态值的例子
黑杰克,也就是21点,游戏规则看PPT。
下面代码的作用是评估21点游戏中,评估闲家player的策略为POLICY_PLAYER对应的状态值函数;
在Shangtong Zhang代码上修改,上代码如下:
#######################################################################
# Copyright (C) #
# 2016-2018 Shangtong Zhang(zhangshangtong.cpp@gmail.com) #
# 2016 Kenta Shimada(hyperkentakun@gmail.com) #
# 2017 Nicky van Foreest(vanforeest@gmail.com) #
# Permission given to modify the code as long as you keep this #
# declaration at the top #
#######################################################################
import numpy as np
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
import seaborn as sns
from tqdm import tqdm
# actions: hit or stand
ACTION_HIT = 0
ACTION_STAND = 1 # "strike" in the book
ACTIONS = [ACTION_HIT, ACTION_STAND]
# policy for player
POLICY_PLAYER = np.zeros(22)
for i in range(12, 20):
POLICY_PLAYER[i] = ACTION_HIT
POLICY_PLAYER[20] = ACTION_STAND
POLICY_PLAYER[21] = ACTION_STAND
# function form of target policy of player
def target_policy_player(usable_ace_player, player_sum, dealer_card):
return POLICY_PLAYER[player_sum]
# policy for dealer
POLICY_DEALER = np.zeros(22)
for i in range(12, 17):
POLICY_DEALER[i] = ACTION_HIT
for i in range(17, 22):
POLICY_DEALER[i] = ACTION_STAND
# get a new card
def get_card():
card = np.random.randint(1, 14)
card = min(card, 10)
return card
# get the value of a card (11 for ace).
def card_value(card_id):
return 11 if card_id == 1 else card_id
# play a game
# @policy_player: specify policy for player
# @initial_state: [whether player has a usable Ace, sum of player's cards, one card of dealer]
# @initial_action: the initial action
def play(policy_player, initial_state=None, initial_action=None):
# player status
# sum of player
player_sum = 0
# trajectory of player
player_trajectory = []
# whether player uses Ace as 11
usable_ace_player = False
# dealer status
dealer_card1 = 0
dealer_card2 = 0
usable_ace_dealer = False
if initial_state is None:
# generate a random initial state
# initialize cards of player
while player_sum < 12:
# if sum of player is less than 12, always hit
card = get_card()
player_sum += card_value(card)
usable_ace_player = (card == 1)
# Always use an ace as 11, unless there are two.
# If the player's sum is larger than 21, he must hold two aces.
if player_sum > 21:
assert player_sum == 22
# use one Ace as 1 rather than 11
player_sum -= 10
# initialize cards of dealer, suppose dealer will show the first card he gets
dealer_card1 = get_card()
dealer_card2 = get_card()
else:
# use specified initial state
usable_ace_player, player_sum, dealer_card1 = initial_state
dealer_card2 = get_card()
# initial state of the game
state = [usable_ace_player, player_sum, dealer_card1]
# initialize dealer's sum
dealer_sum = card_value(dealer_card1) + card_value(dealer_card2)
usable_ace_dealer = 1 in (dealer_card1, dealer_card2)
# if the dealer's sum is larger than 21, he must hold two aces.
if dealer_sum > 21:
assert dealer_sum == 22
# use one Ace as 1 rather than 11
dealer_sum -= 10
assert dealer_sum <= 21
assert player_sum <= 21
# game starts!
# player's turn
while True:
if initial_action is not None:
action = initial_action
initial_action = None
else:
# get action based on current sum
action = policy_player(usable_ace_player, player_sum, dealer_card1)
# track player's trajectory for importance sampling
player_trajectory.append([(usable_ace_player, player_sum, dealer_card1), action])
if action == ACTION_STAND:
break
# if hit, get new card
card = get_card()
# Keep track of the ace count. the usable_ace_player flag is insufficient alone as it cannot
# distinguish between having one ace or two.
ace_count = int(usable_ace_player)
if card == 1:
ace_count += 1
player_sum += card_value(card)
# If the player has a usable ace, use it as 1 to avoid busting and continue.
while player_sum > 21 and ace_count:
player_sum -= 10
ace_count -= 1
# player busts
if player_sum > 21:
return state, -1, player_trajectory
assert player_sum <= 21
usable_ace_player = (ace_count == 1)
# dealer's turn
while True:
# get action based on current sum
action = POLICY_DEALER[dealer_sum]
if action == ACTION_STAND:
break
# if hit, get a new card
new_card = get_card()
ace_count = int(usable_ace_dealer)
if new_card == 1:
ace_count += 1
dealer_sum += card_value(new_card)
# If the dealer has a usable ace, use it as 1 to avoid busting and continue.
while dealer_sum > 21 and ace_count:
dealer_sum -= 10
ace_count -= 1
# dealer busts
if dealer_sum > 21:
return state, 1, player_trajectory
usable_ace_dealer = (ace_count == 1)
# compare the sum between player and dealer
assert player_sum <= 21 and dealer_sum <= 21
if player_sum > dealer_sum:
return state, 1, player_trajectory
elif player_sum == dealer_sum:
return state, 0, player_trajectory
else:
return state, -1, player_trajectory
def EveryVisit(rounds):
G1_sum = np.zeros((10, 10));
# initialze counts to 1 to avoid 0 being divided
count1 = np.ones((10, 10));
G2_sum = np.zeros((10, 10));
# initialze counts to 1 to avoid 0 being divided
count2 = np.ones((10, 10));
pi = target_policy_player;
for i in tqdm(range(0, rounds)):
#_, reward, player_trajectory = play(target_policy_player)
_, reward, episodes = play(pi);
for (usable_ace, player_sum, dealer_showing), _ in episodes:
player_sum -= 12;
dealer_showing -= 1;
if usable_ace:
count1[player_sum, dealer_showing] += 1;
G1_sum[player_sum, dealer_showing] += reward;
else:
count2[player_sum, dealer_showing] += 1;
G2_sum[player_sum, dealer_showing] += reward;
Vpi_usable_ace = G1_sum / count1;
Vpi_no_usable_ace = G2_sum / count2;
print(Vpi_usable_ace, Vpi_no_usable_ace);
return;
def FirstVisit(rounds):
G1_sum = np.zeros((10, 10));
# initialze counts to 1 to avoid 0 being divided
count1 = np.ones((10, 10));
G2_sum = np.zeros((10, 10));
# initialze counts to 1 to avoid 0 being divided
count2 = np.ones((10, 10));
pi = target_policy_player;
for i in tqdm(range(0, rounds)):
#_, reward, player_trajectory = play(target_policy_player)
_, reward, episodes = play(pi);
isVisited1 = np.zeros((10, 10));
isVisited2 = np.zeros((10, 10));
for (usable_ace, player_sum, dealer_showing), _ in episodes:
player_sum -= 12;
dealer_showing -= 1;
if usable_ace:
if(isVisited1[player_sum, dealer_showing] == 0):
count1[player_sum, dealer_showing] += 1;
G1_sum[player_sum, dealer_showing] += reward;
isVisited1[player_sum, dealer_showing] = 1;
else:
if(isVisited2[player_sum, dealer_showing] == 0):
count2[player_sum, dealer_showing] += 1;
G2_sum[player_sum, dealer_showing] += reward;
isVisited2[player_sum, dealer_showing] = 1;
Vpi_usable_ace = G1_sum / count1;
Vpi_no_usable_ace = G2_sum / count2;
print(Vpi_usable_ace, Vpi_no_usable_ace);
return;
if __name__ == '__main__':
FirstVisit(10000);
EveryVisit(10000);
4,模型未知情况下估计动作-状态值函数的必要性
如第3章中所述,对值函数估计的最终目的是进行策略改进,得到最优策略。以第3章中的策略迭代为例,策略估计与改进的基本过程是:
a)策略估计,计算当前策略对应的状态值函数;
b)策略改进,用a)中计算出的状态值函数计算 动作-状态值函数;随后用贪婪算法,改进当前策略
c)如果改进后的策略不是最优策略,则跳到a)继续策略估计,再到b)策略改进;
需要注意的是,状态值函数的计算需要用到模型,因此在模型未知的情况下考虑直接估计动作状态值函数:
a)计算动作-状态值函数;
b)贪婪算法,改进当前策略;
c)如果改进后的策略不是最优策略,则跳到a)。。。
所以说,模型未知的情况下估计动作状态值函数比估计状态值函数有用;
5,动作-状态值函数的估计
动作状态值函数的估计和前面的状态值函数的估计差不多;唯一需要注意的是,需要保证每对动作-状态都能被访问到;即要和k-摇臂模型中的情形一致,要保持探索,其中一个方法是,保证在episode的开始,每个state-action都有一定的概率会出现,于是有Monte Carlo ES算法,此算法其实包含了整个的策略估计和策略改进(control);
6,Monte Carlo ES
算法描述为:

7,Monte Carlo ES的示例代码
基本照搬了Shangtong Zhang的代码:
#######################################################################
# Copyright (C) #
# 2016-2018 Shangtong Zhang(zhangshangtong.cpp@gmail.com) #
# 2016 Kenta Shimada(hyperkentakun@gmail.com) #
# 2017 Nicky van Foreest(vanforeest@gmail.com) #
# Permission given to modify the code as long as you keep this #
# declaration at the top #
#######################################################################
import numpy as np
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
import seaborn as sns
from tqdm import tqdm
# actions: hit or stand
ACTION_HIT = 0
ACTION_STAND = 1 # "strike" in the book
ACTIONS = [ACTION_HIT, ACTION_STAND]
# policy for player
POLICY_PLAYER = np.zeros(22)
for i in range(12, 20):
POLICY_PLAYER[i] = ACTION_HIT
POLICY_PLAYER[20] = ACTION_STAND
POLICY_PLAYER[21] = ACTION_STAND
# function form of target policy of player
def target_policy_player(usable_ace_player, player_sum, dealer_card):
return POLICY_PLAYER[player_sum]
# function form of behavior policy of player
def behavior_policy_player(usable_ace_player, player_sum, dealer_card):
if np.random.binomial(1, 0.5) == 1:
return ACTION_STAND
return ACTION_HIT
# policy for dealer
POLICY_DEALER = np.zeros(22)
for i in range(12, 17):
POLICY_DEALER[i] = ACTION_HIT
for i in range(17, 22):
POLICY_DEALER[i] = ACTION_STAND
# get a new card
def get_card():
card = np.random.randint(1, 14)
card = min(card, 10)
return card
# get the value of a card (11 for ace).
def card_value(card_id):
return 11 if card_id == 1 else card_id
# play a game
# @policy_player: specify policy for player
# @initial_state: [whether player has a usable Ace, sum of player's cards, one card of dealer]
# @initial_action: the initial action
def play(policy_player, initial_state, initial_action):
# player status
# sum of player
player_sum = 0
# trajectory of player
player_trajectory = []
# whether player uses Ace as 11
usable_ace_player = False
# dealer status
dealer_card1 = 0
dealer_card2 = 0
usable_ace_dealer = False
# use specified initial state
usable_ace_player, player_sum, dealer_card1 = initial_state
dealer_card2 = get_card()
# initial state of the game
state = [usable_ace_player, player_sum, dealer_card1]
# initialize dealer's sum
dealer_sum = card_value(dealer_card1) + card_value(dealer_card2)
usable_ace_dealer = 1 in (dealer_card1, dealer_card2)
# if the dealer's sum is larger than 21, he must hold two aces.
if dealer_sum > 21:
dealer_sum -= 10
# game starts!
# player's turn
while True:
if initial_action is not None:
action = initial_action
initial_action = None
else:
# get action based on current sum
action = policy_player(usable_ace_player, player_sum, dealer_card1)
# track player's trajectory for importance sampling
player_trajectory.append([(usable_ace_player, player_sum, dealer_card1), action])
if action == ACTION_STAND:
break
# if hit, get new card
card = get_card()
# Keep track of the ace count. the usable_ace_player flag is insufficient alone as it cannot
# distinguish between having one ace or two.
ace_count = int(usable_ace_player)
if card == 1:
ace_count += 1
player_sum += card_value(card)
# If the player has a usable ace, use it as 1 to avoid busting and continue.
while player_sum > 21 and ace_count:
player_sum -= 10
ace_count -= 1
# player busts
if player_sum > 21:
return state, -1, player_trajectory
assert player_sum <= 21
usable_ace_player = (ace_count == 1)
# dealer's turn
while True:
# get action based on current sum
action = POLICY_DEALER[dealer_sum]
if action == ACTION_STAND:
break
# if hit, get a new card
new_card = get_card()
ace_count = int(usable_ace_dealer)
if new_card == 1:
ace_count += 1
dealer_sum += card_value(new_card)
# If the dealer has a usable ace, use it as 1 to avoid busting and continue.
while dealer_sum > 21 and ace_count:
dealer_sum -= 10
ace_count -= 1
# dealer busts
if dealer_sum > 21:
return state, 1, player_trajectory
usable_ace_dealer = (ace_count == 1)
# compare the sum between player and dealer
assert player_sum <= 21 and dealer_sum <= 21
if player_sum > dealer_sum:
return state, 1, player_trajectory
elif player_sum == dealer_sum:
return state, 0, player_trajectory
else:
return state, -1, player_trajectory
# Monte Carlo with Exploring Starts
def monte_carlo_es(episodes):
# (playerSum, dealerCard, usableAce, action)
state_action_values = np.zeros((10, 10, 2, 2))
# initialze counts to 1 to avoid division by 0
state_action_pair_count = np.ones((10, 10, 2, 2))
# behavior policy is greedy
def behavior_policy(usable_ace, player_sum, dealer_card):
usable_ace = int(usable_ace)
player_sum -= 12
dealer_card -= 1
# get argmax of the average returns(s, a)
values_ = state_action_values[player_sum, dealer_card, usable_ace, :] / \
state_action_pair_count[player_sum, dealer_card, usable_ace, :]
return np.random.choice([action_ for action_, value_ in enumerate(values_) if value_ == np.max(values_)])
# play for several episodes
for episode in tqdm(range(episodes)):
# for each episode, use a randomly initialized state and action
initial_state = [bool(np.random.choice([0, 1])),
np.random.choice(range(12, 22)),
np.random.choice(range(1, 11))]
initial_action = np.random.choice(ACTIONS)
current_policy = behavior_policy if episode else target_policy_player
_, reward, trajectory = play(current_policy, initial_state, initial_action)
for (usable_ace, player_sum, dealer_card), action in trajectory:
usable_ace = int(usable_ace)
player_sum -= 12
dealer_card -= 1
# update values of state-action pairs
state_action_values[player_sum, dealer_card, usable_ace, action] += reward
state_action_pair_count[player_sum, dealer_card, usable_ace, action] += 1
return state_action_values / state_action_pair_count
def figure_5_2():
state_action_values = monte_carlo_es(500000)
# get the optimal policy
action_no_usable_ace = np.argmax(state_action_values[:, :, 0, :], axis=-1)
action_usable_ace = np.argmax(state_action_values[:, :, 1, :], axis=-1)
print(action_no_usable_ace);
print(action_usable_ace);
if __name__ == '__main__':
figure_5_2();8,上面代码的解释
a)探索和采样阶段
看这两行代码:
current_policy = behavior_policy if episode else target_policy_player
_, reward, trajectory = play(current_policy, initial_state, initial_action)initial_state, initial_action的随机性体现了探索;
current_policy基本是behavior_policy,用贪婪加随机,区别于固定策略target_policy_player,可以产生不一样的episode;
b)贪婪求最优策略
action_no_usable_ace = np.argmax(state_action_values[:, :, 0, :], axis=-1)
action_usable_ace = np.argmax(state_action_values[:, :, 1, :], axis=-1)9,没有ES的MC control
重点介绍了-soft算法:策略改进时,以
的概率直接选择当前动作状态值最大的动作,
的概率选择其他动作(包含当前动作状态值最大的动作);
先上-soft对应的代码,自己写了个,仍然用了Shangtong Zhang的部分代码,如下:
10,-soft的示例代码
#######################################################################
# Copyright (C) #
# 2016-2018 Shangtong Zhang(zhangshangtong.cpp@gmail.com) #
# 2016 Kenta Shimada(hyperkentakun@gmail.com) #
# 2017 Nicky van Foreest(vanforeest@gmail.com) #
# Permission given to modify the code as long as you keep this #
# declaration at the top #
#######################################################################
import numpy as np
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
import seaborn as sns
from tqdm import tqdm
hitNum = 1;
standNum = 1;
# actions: hit or stand
ACTION_HIT = 0
ACTION_STAND = 1 # "strike" in the book
ACTIONS = [ACTION_HIT, ACTION_STAND]
EPSILON = 0.3;
EPSILON_POLICY = np.zeros((10, 10, 2, 2));
Returns = np.zeros((10, 10, 2, 2));
Q = np.zeros((10, 10, 2, 2));
count = np.ones((10, 10, 2, 2));
# policy for dealer
POLICY_DEALER = np.zeros(22)
for i in range(12, 17):
POLICY_DEALER[i] = ACTION_HIT
for i in range(17, 22):
POLICY_DEALER[i] = ACTION_STAND
# get a new card
def get_card():
card = np.random.randint(1, 14)
card = min(card, 10)
return card
# get the value of a card (11 for ace).
def card_value(card_id):
return 11 if card_id == 1 else card_id
# play a game
# @policy_player: specify policy for player
# @initial_state: [whether player has a usable Ace, sum of player's cards, one card of dealer]
# @initial_action: the initial action
def play(policy_player, initial_state=None, initial_action=None):
# player status
# sum of player
player_sum = 0
# trajectory of player
player_trajectory = []
# whether player uses Ace as 11
usable_ace_player = False
# dealer status
dealer_card1 = 0
dealer_card2 = 0
usable_ace_dealer = False
if initial_state is None:
# generate a random initial state
# initialize cards of player
while player_sum < 12:
# if sum of player is less than 12, always hit
card = get_card()
player_sum += card_value(card)
usable_ace_player = (card == 1)
# Always use an ace as 11, unless there are two.
# If the player's sum is larger than 21, he must hold two aces.
if player_sum > 21:
assert player_sum == 22
# use one Ace as 1 rather than 11
player_sum -= 10
# initialize cards of dealer, suppose dealer will show the first card he gets
dealer_card1 = get_card()
dealer_card2 = get_card()
else:
# use specified initial state
usable_ace_player, player_sum, dealer_card1 = initial_state
dealer_card2 = get_card()
# initial state of the game
state = [usable_ace_player, player_sum, dealer_card1]
# initialize dealer's sum
dealer_sum = card_value(dealer_card1) + card_value(dealer_card2)
usable_ace_dealer = 1 in (dealer_card1, dealer_card2)
# if the dealer's sum is larger than 21, he must hold two aces.
if dealer_sum > 21:
assert dealer_sum == 22
# use one Ace as 1 rather than 11
dealer_sum -= 10
assert dealer_sum <= 21
assert player_sum <= 21
# game starts!
# player's turn
while True:
if initial_action is not None:
action = initial_action
initial_action = None
else:
# get action based on current sum
action = policy_player(usable_ace_player, player_sum, dealer_card1)
# track player's trajectory for importance sampling
player_trajectory.append([(usable_ace_player, player_sum, dealer_card1), action])
if action == ACTION_STAND:
break
# if hit, get new card
card = get_card()
# Keep track of the ace count. the usable_ace_player flag is insufficient alone as it cannot
# distinguish between having one ace or two.
ace_count = int(usable_ace_player)
if card == 1:
ace_count += 1
player_sum += card_value(card)
# If the player has a usable ace, use it as 1 to avoid busting and continue.
while player_sum > 21 and ace_count:
player_sum -= 10
ace_count -= 1
# player busts
if player_sum > 21:
return state, -1, player_trajectory
assert player_sum <= 21
usable_ace_player = (ace_count == 1)
# dealer's turn
while True:
# get action based on current sum
action = POLICY_DEALER[dealer_sum]
if action == ACTION_STAND:
break
# if hit, get a new card
new_card = get_card()
ace_count = int(usable_ace_dealer)
if new_card == 1:
ace_count += 1
dealer_sum += card_value(new_card)
# If the dealer has a usable ace, use it as 1 to avoid busting and continue.
while dealer_sum > 21 and ace_count:
dealer_sum -= 10
ace_count -= 1
# dealer busts
if dealer_sum > 21:
return state, 1, player_trajectory
usable_ace_dealer = (ace_count == 1)
# compare the sum between player and dealer
assert player_sum <= 21 and dealer_sum <= 21
if player_sum > dealer_sum:
return state, 1, player_trajectory
elif player_sum == dealer_sum:
return state, 0, player_trajectory
else:
return state, -1, player_trajectory
def epsilon_policy_player(usable_ace_player, player_sum, dealer_card):
usable_ace_player = int(usable_ace_player);
player_sum -= 12;#12 ~ 21
dealer_card -= 1;#A ~ 10
p1 = EPSILON_POLICY[player_sum, dealer_card, usable_ace_player, ACTION_HIT];
p2 = EPSILON_POLICY[player_sum, dealer_card, usable_ace_player, ACTION_STAND];
p = np.array([p1, p2]);
action = np.random.choice([ACTION_HIT, ACTION_STAND], p = p.ravel());
global hitNum, standNum;
if action == ACTION_HIT:
hitNum += 1;
if action == ACTION_STAND:
standNum += 1;
return action;
def InitEpsilonPolicy():
for i in range(0, 10):
for j in range(0, 10):
EPSILON_POLICY[i, j, 0, 0] = 0.5;
EPSILON_POLICY[i, j, 0, 1] = 1.0 - EPSILON_POLICY[i, j, 0, 0];
EPSILON_POLICY[i, j, 1, 0] = 0.5;
EPSILON_POLICY[i, j, 1, 1] = 1.0 - EPSILON_POLICY[i, j, 1, 0];
return;
def GenerateEpisode(policy):
return play(policy);
def Initialize():
InitEpsilonPolicy();
return;
def ImprovePolicy():
global Q
for i in range(0, 10):
for j in range(0, 10):
for k in range(0, 2):
valueHit = Q[i, j, k, ACTION_HIT];
valueStand = Q[i, j, k, ACTION_STAND];
if valueHit != 0.0 or valueStand != 0.0:
if valueHit > valueStand:
EPSILON_POLICY[i, j, k, ACTION_HIT] = 1.0 - EPSILON + EPSILON / 2.0;
EPSILON_POLICY[i, j, k, ACTION_STAND] = 1.0 - EPSILON_POLICY[i, j, k, ACTION_HIT];
else:
EPSILON_POLICY[i, j, k, ACTION_STAND] = 1.0 - EPSILON + EPSILON / 2.0;
EPSILON_POLICY[i, j, k, ACTION_HIT] = 1.0 - EPSILON_POLICY[i, j, k, ACTION_STAND];
return;
def EvaluatePolicy(reward, trajectory):
global Q
isFirstVisited = np.zeros((10, 10, 2));
for (usable_ace, player_sum, dealer_card), action in trajectory:
usable_ace = int(usable_ace)
player_sum -= 12
dealer_card -= 1
# update values of state-action pairs
if(isFirstVisited[player_sum, dealer_card, usable_ace] == 0):
Returns[player_sum, dealer_card, usable_ace, action] += reward;
count[player_sum, dealer_card, usable_ace, action] += 1;
isFirstVisited[player_sum, dealer_card, usable_ace] = 1;
Q = Returns / count;#average
return;
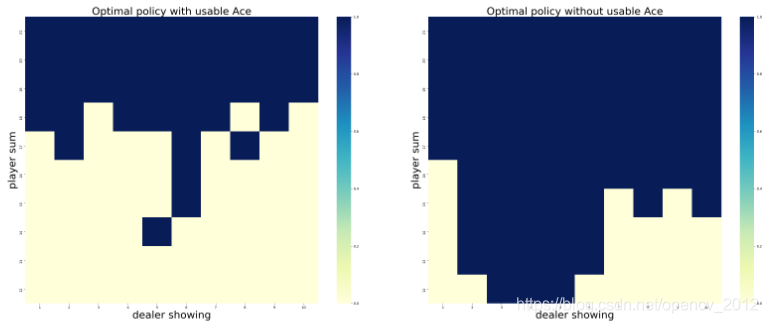
def draw():
# get the optimal policy
global Q
action_no_usable_ace = np.argmax(Q[:, :, 0, :], axis=-1)
action_usable_ace = np.argmax(Q[:, :, 1, :], axis=-1)
print(action_no_usable_ace);
images = [action_usable_ace,
action_no_usable_ace]
titles = ['Optimal policy with usable Ace',
'Optimal policy without usable Ace']
_, axes = plt.subplots(1, 2, figsize=(40, 15))
plt.subplots_adjust(wspace=0.1, hspace=0.2)
axes = axes.flatten()
for image, title, axis in zip(images, titles, axes):
fig = sns.heatmap(np.flipud(image), cmap="YlGnBu", ax=axis, xticklabels=range(1, 11),
yticklabels=list(reversed(range(12, 22))))
fig.set_ylabel('player sum', fontsize=30)
fig.set_xlabel('dealer showing', fontsize=30)
fig.set_title(title, fontsize=30)
plt.savefig('../images/EpsilonSoft.png')
plt.close()
return;
def EpsilonSoft(rounds):
Initialize();
for i in tqdm(range(0, rounds)):
state, reward, trajectory = GenerateEpisode(epsilon_policy_player);
EvaluatePolicy(reward, trajectory);
ImprovePolicy();
draw();
return;
if __name__ == '__main__':
EpsilonSoft(400000);
结果如下:
11,-soft的证明


















 320
320

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









