




背景与现状
随着容器技术的迅速发展,容器引擎已经成为云原生时代的基石。容器具有高度可移植、便捷快速部署、弹性可伸缩等优点,在云计算、大数据、人工智能等领域中作为关键的软件开发和部署方法,展现出了卓越的价值。在人工智能和大数据越来越普及的今天,如何让容器能够更快速、更便捷的使用GPU、NPU等设备也成为了社区热门课题之一。这也是容器引擎在大数据时代的短板之一。
底层运行时的复杂度
在过去,设备的使用比较简单,因此如果需要在容器中使用某设备,仅需在容器中暴露这个设备节点即可。例如,如果容器需要使用宿主机上的某个设备,只需要通过--device参数即可完成。
$ isula run -d -name test-device --device <major>:<minor> busybox:latest sleep 1000随着AI浪潮的到来,越来越复杂的设备和配套软件对容器的部署提出了新的要求,GPU、高性能 NIC、FPGA、 InfiniBand 适配器等设备及其配套软件要求用户在部署容器时不仅仅只是挂载一个设备节点,往往还需要用户配置相关环境变量,挂载主机路径,甚至提前启动相关进程。以NVIDIA GPU为例, 用户在使用容器时,需要挂载大量文件,对于如此多的文件,每个容器使用 GPU 时都使用 --mount 去挂载无疑是低效且繁琐的。
$ nvidia-container-cli list/dev/nvidiactl/dev/nvidia-uvm/dev/nvidia-uvm-tools/dev/nvidia-modeset/dev/nvidia0/usr/bin/nvidia-smi/usr/bin/nvidia-debugdump/usr/bin/nvidia-persistenced/usr/bin/nvidia-cuda-mps-control/usr/bin/nvidia-cuda-mps-server......
为了方便用户使用,供应商通常不得不为不同的运行时编写和维护多个插件,甚至直接在运行时中插入特定于供应商的代码。例如,NVIDIA为使用 GPU 的容器提供了专门的NVIDIA Container Runtime方案,示意图如下:
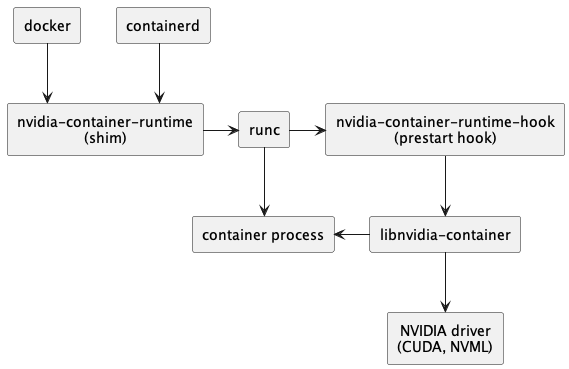
图1 NVIDIA Container Runtime设计图[1]
NVIDIA Container Runtime 的主要功能是将使用 GPU 设备所必需的驱动文件和可执行命令绑定到容器内,并执行一些hook命令,再调用runc原有流程启动容器。
很显然,一旦更换其他异构计算设备,就需要重新开发一套这样专门服务于该设备的容器运行时,这无疑是难以接受的。事实上,这些配置存在一些固定的特征,如果能有一种统一规范来规定整个流程,就可以轻松地为每个容器设备进行特定配置。
Kubernetes管理面的复杂度
如果供应商没有提供底层运行时,用户往往需要在容器管理面提供
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 4839
4839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











