






 JDK1.8的HashMap在数据结构上采用了hash数组加链表和红黑树的组合,相比于1.7的纯链表有显著提升。插入操作由头插法变为尾插法,解决了链表逆序问题。扩容策略和链表转红黑树的阈值进行了调整,提高了性能。此外,hash计算方法通过与高16位异或确保高位参与运算,提高哈希分布均匀性。
JDK1.8的HashMap在数据结构上采用了hash数组加链表和红黑树的组合,相比于1.7的纯链表有显著提升。插入操作由头插法变为尾插法,解决了链表逆序问题。扩容策略和链表转红黑树的阈值进行了调整,提高了性能。此外,hash计算方法通过与高16位异或确保高位参与运算,提高哈希分布均匀性。
与1.7对比
- 数据结构:1.7是hash数组 + 链表;1.8采用hash数组 + 链表 + 红黑树;
- 数据插入:1.7头插法;1.8尾插法;
- 扩容后数据分布方式:1.7是对所有key重新hash(key的hash值的二进制 & length-1的二进制);1.8是原位置或者(原位置+oldlen)
四个关键常量(扩容&链表转红黑树)
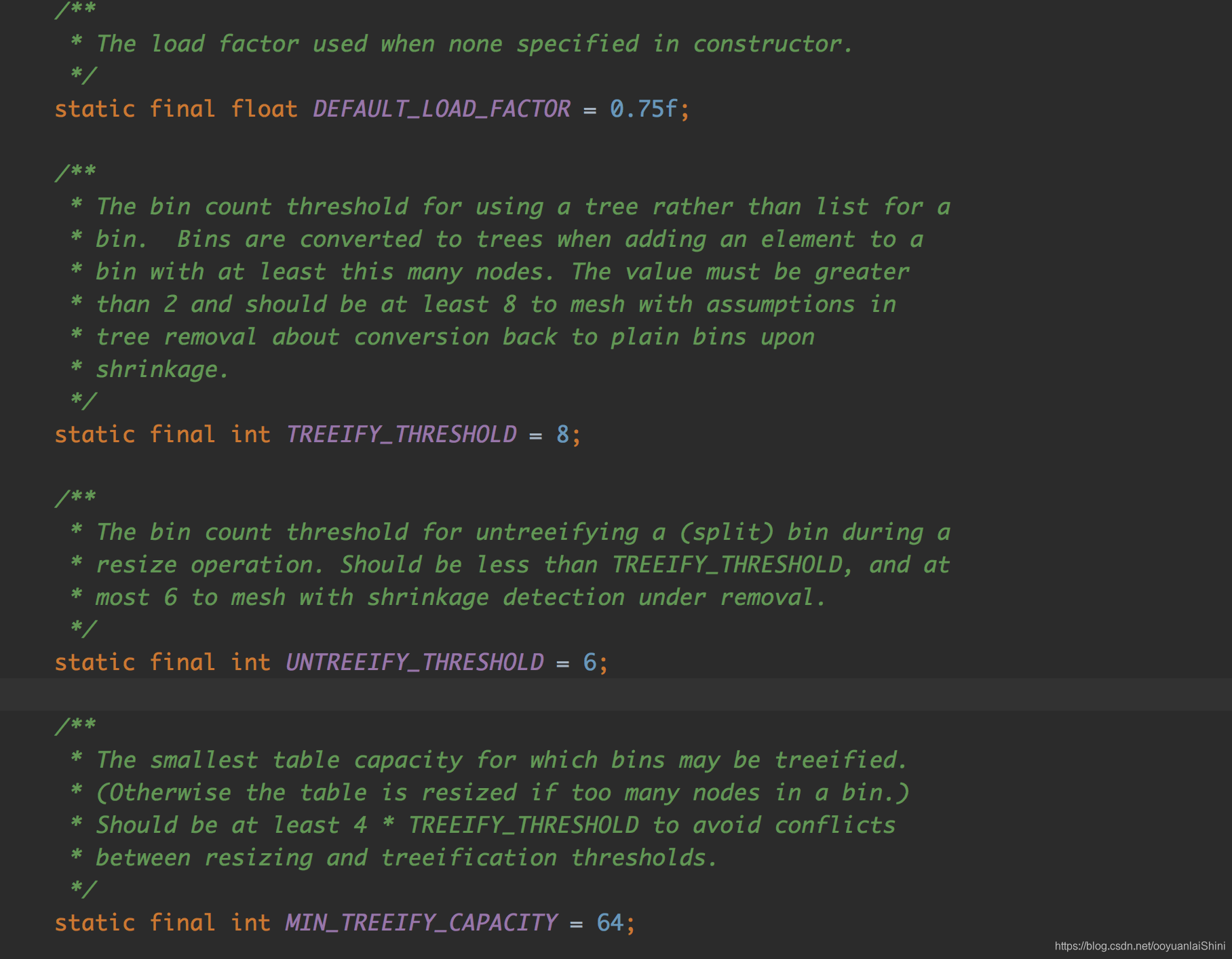
- DEFAULT_LOAD_FACTOR 扩容因子
threshold = table长度 * 扩容因子

- TREEIFY_THRESHOLD & MIN_TREEIFY_CAPACITY 控制链表转红黑树
链表转红黑树的两个条件


- UNTREEIFY_THRESHOLD 控制红黑树转链表

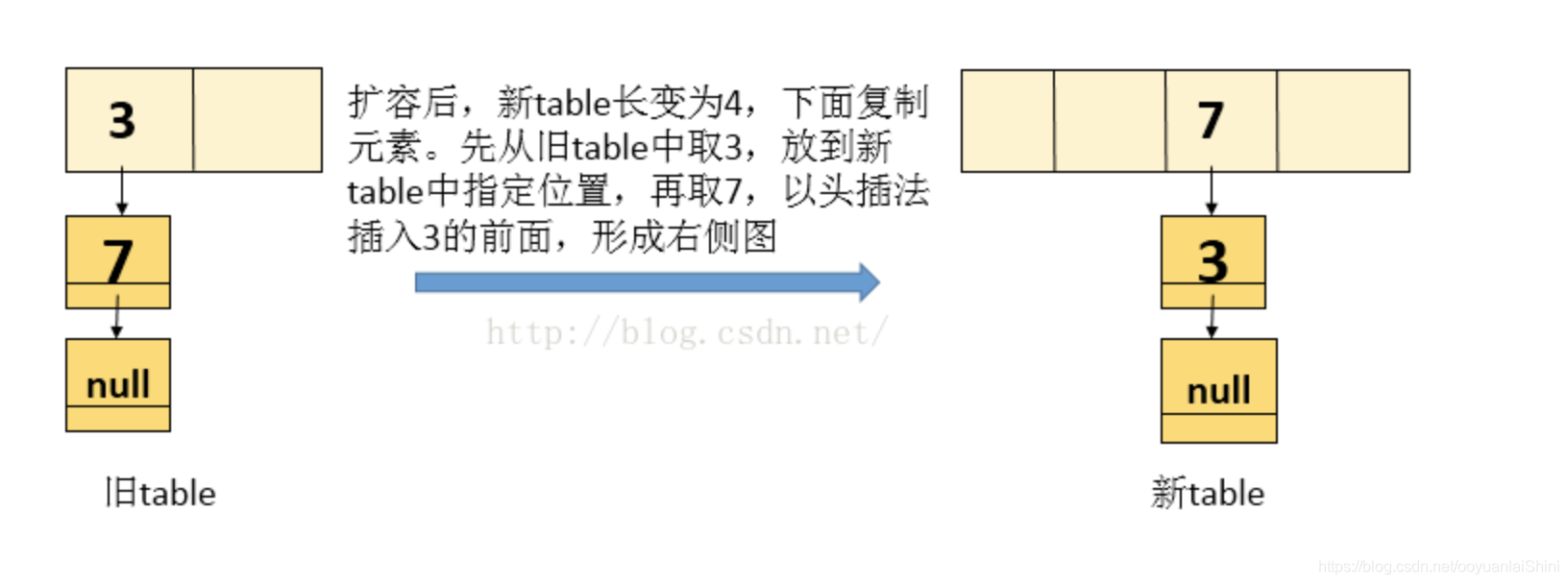
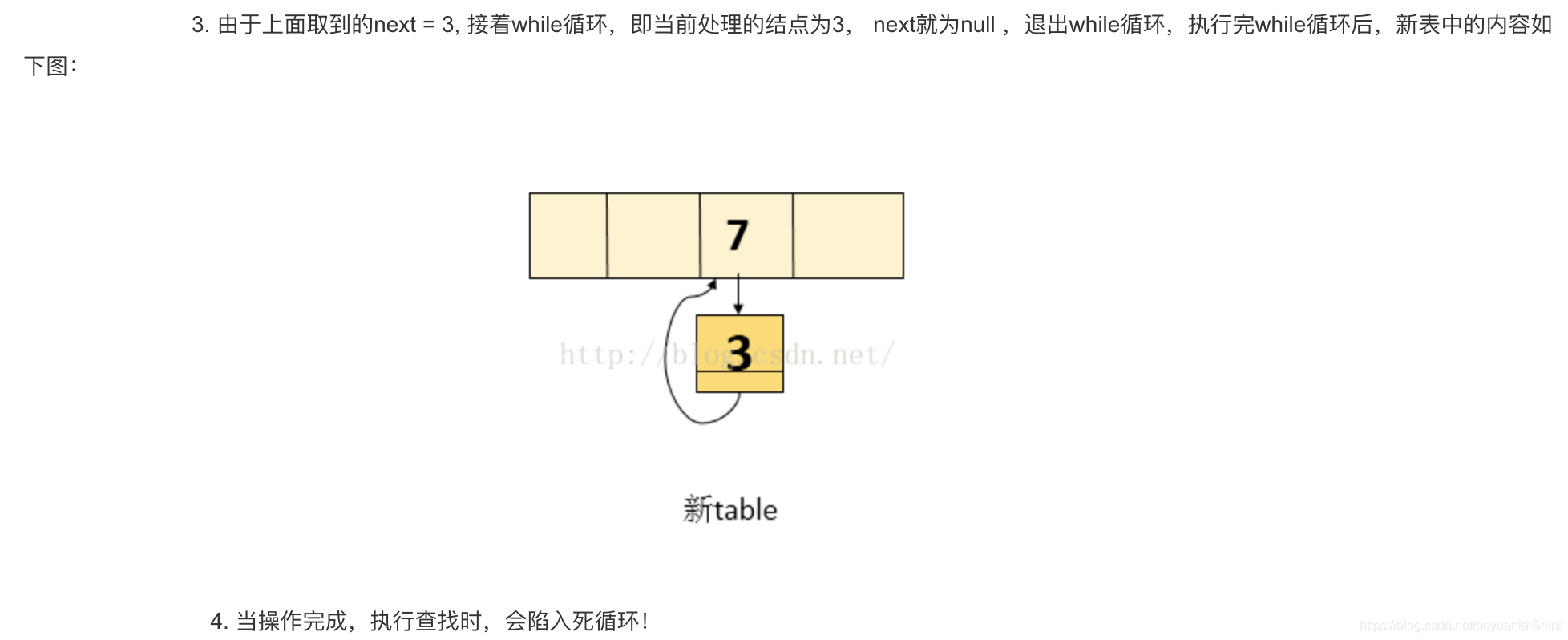
头插法和尾插法对比
- 头插法会导致链表逆序&死循环(引用网络图)


hash计算方法
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
可以看到,先计算key的hashcode,然后和计算的hashcode高16位异或;
为什么需要和高16位异或?
1、但由于绝大多数情况下length一般都小于2^16即小于65536。所以return h & (length-1);结果始终是h的低16位与(length-1)进行&运算。如下例子(hashcode为四字节)
由于和(length-1)运算,length 绝大多数情况小于2的16次方。所以始终是hashcode 的低16位(甚至更低)参与运算。要是高16位也参与运算,会让得到的下标更加散列。
所以这样高16位是用不到的,如何让高16也参与运算呢。所以才有hash(Object key)方法。让他的hashCode()和自己的高16位^运算。所以(h >>> 16)得到他的高16位与hashCode()进行^运算。
为什么用^而不用&和|
因为&和|都会使得结果偏向0或者1 ,并不是均匀的概念,所以用^。
这就是为什么有hash(Object key)的原因。

















 193
193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









