







 本文深入探讨降维技术,解析PCA与SVD算法原理,对比特征选择与特征创造,阐述重要参数n_components与svd_solver的作用及选择策略,揭示降维在数据科学中的关键应用。
本文深入探讨降维技术,解析PCA与SVD算法原理,对比特征选择与特征创造,阐述重要参数n_components与svd_solver的作用及选择策略,揭示降维在数据科学中的关键应用。
在降维的过程中既减少特征的数量,又保留大部分有效信息,即通过将带有重复信息的特征合并,并删除那些带无效信息的特征等等逐渐创造出能够代表原特征矩阵大部分信息的特征更少的,新特征矩阵。
有一种重要的特征选择方法:方差过滤。如果一个特征的方差很小,则意味着这个特征上很可能有大量取值都相同(比如90%都是1,只有10%是0,甚至100%是1),那这一个特征的取值对样本而言就没有区分度,这种特征就不带有有效信息。因此,在降维中,PCA使用的信息量衡量指标,就是样本方差,又称可解释性方差,方差越大,特征所带的信息量越多
找出n个新特征向量让数据能够被压缩到少数特征上并且总信息量不损失太多的技术就是矩阵分解。PCA和SVD是两种不同的降维算法,但他们都遵从上面的过程来实现降维,只是两种算法中矩阵分解的方法不同,信息量的衡量指标不同罢了。PCA使用方差作为信息量的衡量指标,并且特征值分解来找出空间V。而SVD使用奇异值分解来找出空间V。
特征工程中有三种方式:特征提取,特征创造和特征选择。
特征选择是从已存在的特征中选取携带信息最多的,选完之后的特征依然具有可解释性,依然知道这个特征在原数据的哪个位置,代表着原数据上的什么含义。而PCA,是将已存在的特征进行压缩,降维完毕后的特征不是原本的特征矩阵中的任何一个特征,而是通过某些方式组合起来的新特征。通常来说,在新的特征矩阵生成之前,无法知晓PCA都建立了怎样的新特征向量,新特征矩阵生成之后也不具有可读性,无法判断新特征矩阵的特征是从原数据中的什么特征组合而来,新特征虽然带有原始数据的信息,却已经不是原数据上代表着的含义了。以PCA为代表的降维算法因此是特征创造(feature creation,或feature construction)的一种。
可以想见,PCA一般不适用于探索特征和标签之间的关系的模型(如线性回归),因为无法解释的新特征和标签之间的关系不具有意义。在线性回归模型中,我们使用特征选择。
奇异值分解SVD可以不计算协方差矩阵等等结构复杂计算冗长的矩阵,就直接求出新特征空间和降维后的特征矩阵。但SVD可以作弊耍赖直接算出V。但是遗憾的是,SVD的信息量衡量指标比较复杂,要理解”奇异值“远不如理解”方差“来得容易,因此,sklearn将降维流程拆成了两部分:一部分是计算特征空间V,由奇异值分解完成,另一部分是映射数据和求解新特征矩阵,由主成分分析完成,实现了用SVD的性质减少计算量,却让信息量的评估指标是方差。
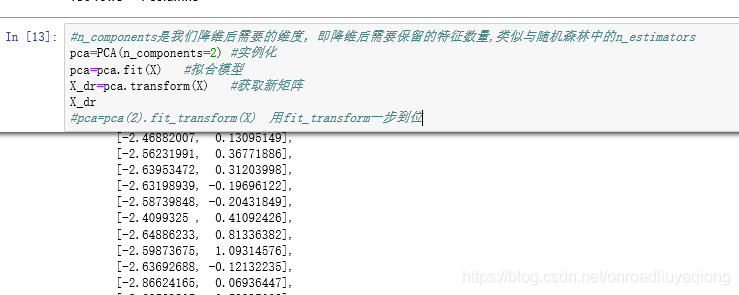
1、重要参数n_components:是降维后需要的维度,即降维后需要保留的特征数量,降维流程中第二步里需要确认的k值,一般输入[0, min(X.shape)]范围中的整数
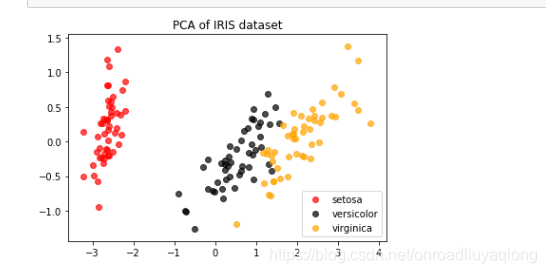
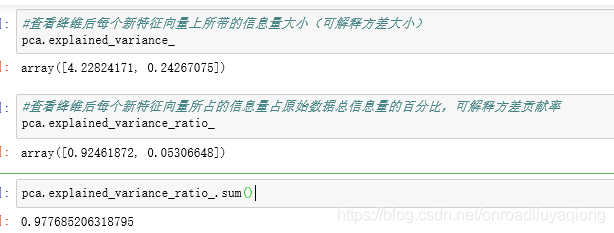
选择n_components的方法:
1)、累计可解释方差贡献率
累积可解释方差贡献率曲线是一条以降维后保留的特征个数为横坐标,降维后新特征矩阵捕捉到的可解释方差贡献率为纵坐标的曲线,能够帮助我们决定n_components最好的取值。
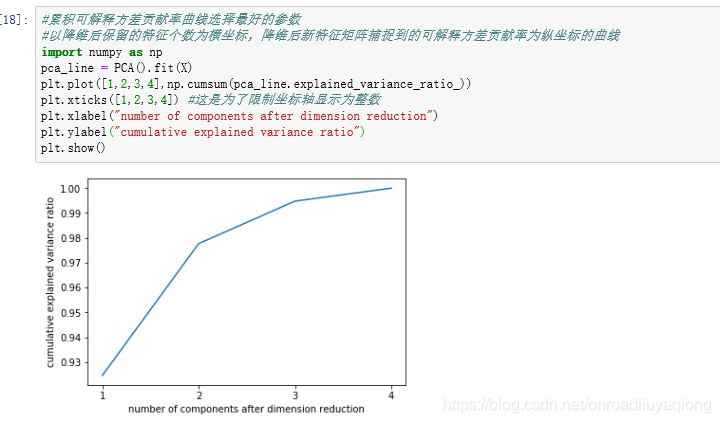
2)、最大似然估计,输入“mle”作为n_components的参数输入,就可以调用
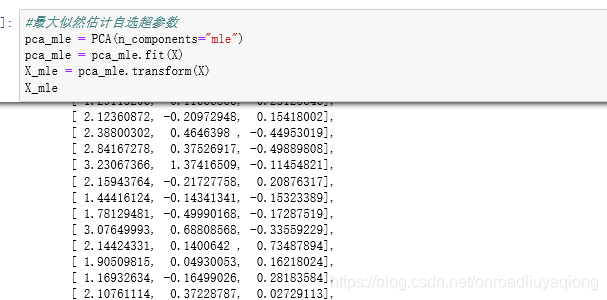

3)、按信息量占比
输入【0,1】之间的浮点数,并且另svd_solver=‘full’,表示希望绛维后的总解释性方差占比大于n_component指定的百分比,即希望保留多少的信息量
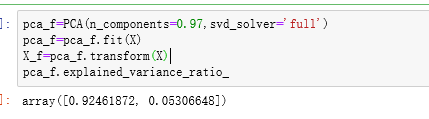
2、重要参数svd_solver
参数svd_solver是在降维过程中,用来控制矩阵分解的一些细节的参数。有四种模式可选:“auto”, “full”, “arpack”,“randomized”,默认”auto"。
“auto”:基于X.shape和n_components的默认策略来选择分解器:如果输入数据的尺寸大于500x500且要提取的特征数小于数据最小维度min(X.shape)的80%,就启用效率更高的”randomized“方法。否则,精确完整的SVD将被计算,截断将会在矩阵被分解完成后有选择地发生
“full”:从scipy.linalg.svd中调用标准的LAPACK分解器来生成精确完整的SVD,适合数据量比较适中,计算时间充足的情况,生成的精确完整的SVD的结构为:
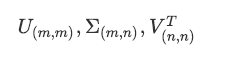
“arpack”:从scipy.sparse.linalg.svds调用ARPACK分解器来运行截断奇异值分解(SVD truncated),分解时就将特征数量降到n_components中输入的数值k,可以加快运算速度,适合特征矩阵很大的时候,但一般用于特征矩阵为稀疏矩阵的情况,此过程包含一定的随机性。截断后的SVD分解出的结构为:
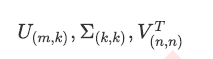
“randomized”,通过Halko等人的随机方法进行随机SVD。在"full"方法中,分解器会根据原始数据和输入的n_components值去计算和寻找符合需求的新特征向量,但是在"randomized"方法中,分解器会先生成多个随机向量,然后一一去检测这些随机向量中是否有任何一个符合我们的分解需求,如果符合,就保留这个随机向量,并基于这个随机向量来构建后续的向量空间。这个方法已经被Halko等人证明,比"full"模式下计算快
很多,并且还能够保证模型运行效果。适合特征矩阵巨大,计算量庞大的情况。
而参数random_state在参数svd_solver的值为"arpack" or "randomized"的时候生效,可以控制这两种SVD模式中的随机模式。通常我们就选用”auto“,不必对这个参数纠结太多。
3、重要属性components_
在矩阵分解时,PCA是有目标的:在原有特征的基础上,找出能够让信息尽量聚集的新特征向量。
4、重要接口inverse_transform
inverse_transform,可以将我们归一化,标准化,甚至做过哑变量的特征矩阵还原回原始数据中的特征矩阵,但PCA不是完全可逆。
Inverse_transform的功能,是基于X_dr中的数据进行升维,将数据重新映射到原数据所在的特征空间中,而并非恢复所有原有的数据。

















 1989
1989

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









