






 本文介绍了一种新颖的MOSformer模型,通过结合动量编码器和切片间融合Transformer,改善了医学图像分割的性能。在Synapse、ACDC和AMOS数据集上,MOSformer达到了85.63%、92.19%和85.43%的DSC,展示了其在该领域的竞争优势。
本文介绍了一种新颖的MOSformer模型,通过结合动量编码器和切片间融合Transformer,改善了医学图像分割的性能。在Synapse、ACDC和AMOS数据集上,MOSformer达到了85.63%、92.19%和85.43%的DSC,展示了其在该领域的竞争优势。
Huang, D.-X., Zhou, X.-H., Xie, X.-L., Liu, S.-Q., Feng, Z.-Q., Gui, M.-J., Li, H., Xiang, T.-Y., Liu, X.-L., & Hou, Z.-G. (2024). MOSformer: Momentum encoder-based inter-slice fusion transformer for medical image segmentation. In arXiv [eess.IV]. arXiv. http://arxiv.org/abs/2401.11856
医学图像分割在各种临床应用中占据重要地位。深度学习已经成为处理体积医学图像自动分割的主要解决方案。基于2.5D的分割模型弥合了基于2D模型的计算效率和基于3D模型的空间感知能力。然而,目前的2.5D模型通常将每个切片平等对待,未能有效学习和利用切片间的信息,导致分割性能次优。在本文中,提出了一种新颖的基于动量编码器的切片间融合变压器(MOSformer),通过利用由不同编码器提取的多尺度特征图上的切片间信息来解决这个问题。具体而言,采用了双编码器来增强不同切片之间的特征可辨识性。其中一个编码器是移动平均的,以保持切片表示的一致性。此外,开发了一个IF-Swin变压器模块,用于融合切片间的多尺度特征。MOSformer在三个基准数据集(Synapse、ACDC和AMOS)上进行了评估,分别取得了85.63%、92.19%和85.43%的DSC,确立了新的最先进水平。这些有希望的结果表明了它在医学图像分割中的竞争力。一旦被接受,MOSformer的代码和模型将公开提供。
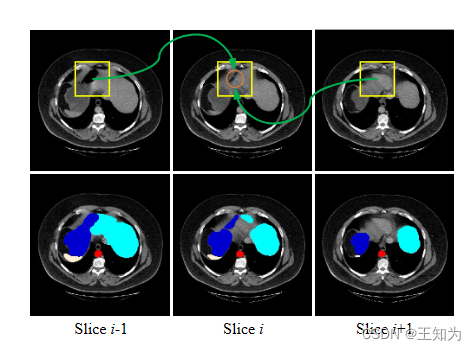
图1 这个图解释了切片间融合的原理。由于胃的内部类别方差很大(在深蓝色中标记),模型很难准确分类切片i上橙色的像素。通过引入切片间的信息,像素可以获得更丰富的上下文。
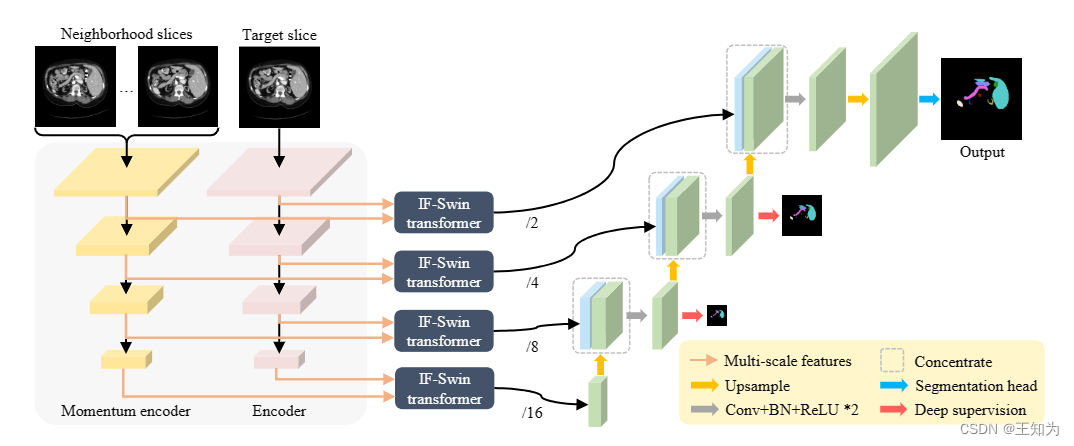
图2. MOSformer的架构。它由双编码器组成:动量编码器用于提取相邻切片信息,而编码器用于提取目标切片信息。IF-Swin transformer被设计用于在多尺度特征上实现切片间的融合。之后,融合后的特征被馈送到CNN解码器,生成目标切片的分割地图。
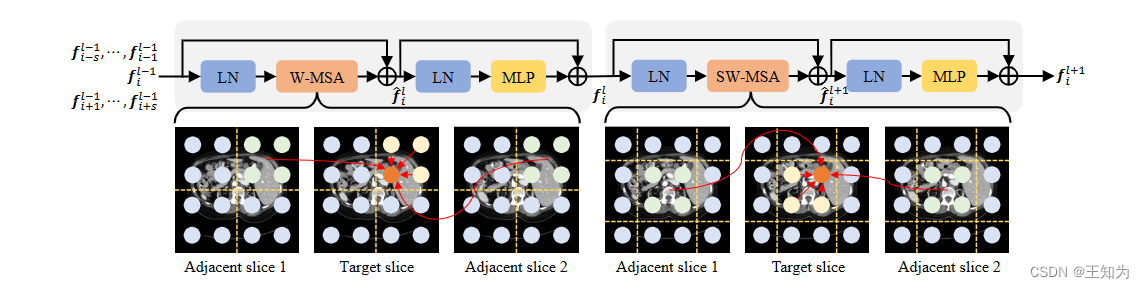
图3. IF-Swin transformer模块的示意图。它包含两个连续的IF-Swin transformer,具有不同的窗口划分配置。基于窗口的自注意力扩展到切片间的维度,促使目标切片像素学习切片内和切片间的上下文。
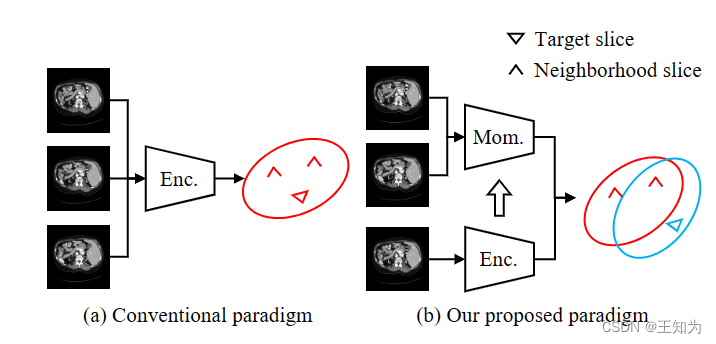
图4. 2.5D基分割模型的传统特征提取范式与我们提出的范式之间的比较。 (a) 传统方法使用一个编码器对所有输入切片进行编码。因此,目标切片和邻近切片的分布是相同的。 (b) 我们提出的范式采用两个编码器分别处理目标和邻近切片。在邻近切片编码器中使用了动量更新。因此,目标和邻近切片的分布是可区分的并且一致的。 (Enc.: 编码器; Mom.: 动量编码器)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











