



 本文介绍了在Ambari中创建用户角色、配置HDFS ACL权限,以及解决Hiveserver2高可用问题的方法。包括检查端口监听、修改服务启动脚本和调整配置参数。此外,还详细讨论了Hive on Spark的设置,如编译Spark源码、配置Spark依赖和执行引擎,并提供了相关配置参数的示例。
本文介绍了在Ambari中创建用户角色、配置HDFS ACL权限,以及解决Hiveserver2高可用问题的方法。包括检查端口监听、修改服务启动脚本和调整配置参数。此外,还详细讨论了Hive on Spark的设置,如编译Spark源码、配置Spark依赖和执行引擎,并提供了相关配置参数的示例。
ambari创建用户: ambari角色分布.
hdfs赋权:
查看文件或者目录的访问控制列表(ACL)
hadoop fs -getfacl [-R] -m
设置文件或者目录的访问控制列表(ACL)
hadoop fs -setfacl [-R] -m
hadoop fs -setfacl -m user:aibddev:rwx /user ##设置用户aibddev对/user目录具有读、写、执行权限
hadoop fs -setfacl -m default:user:aibddev:rwx /user ##default表示设置默认的ACL权限,以后在该目录中新建文件或者子目录时,新建的文件/目录的ACL权限都继承设置的default ACLS
-R ##表示递归操作子目录
-m ##创建acl访问控制列表
-d ##
1、添加hiveserver2,配置高可用
—建议不要再主机中添加,在服务框添加(因为在这里面添加会提示你重启受影响服务)
可能遇到问题,服务启动后,没有监听10000端口,过几分钟之后,hiveserver2就挂了。
查看监听端口命令:
netstat -anp|grep 10000
可以在主机后台启动试一下:
hive --service hiveserver2 &
,如果还不行,把其他有可能有关的服务都重启一遍
如果jps能查到服务了,ambari显示服务挂,对一下进程号,
把/var/run/hive/hive-server.pid内容改成实际的进程号
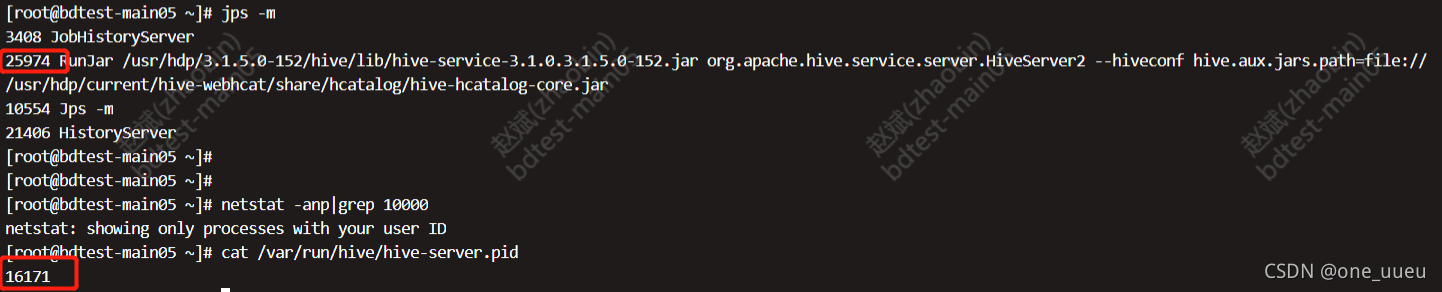
然后再ambari上重启
最后来来回回的折腾,ambari重启服务,后台可以查到监听端口,具体为啥不清楚。。。。

2、在ambari上重启hiveserver2服务 缓慢的问题
hiveserver主机上搜到”tries=60“关键字的py文件
find / -name *py|xargs grep “tries=60”
进入目录:
cd /var/lib/ambari-agent/cache/stacks/HDP/3.0/services/HIVE/package/scripts
find ./ -name *.py|xargs grep “tries”
备份文件,减少尝试次数(tries=60),改为2
cp hive_service.py hive_service.py_bak
3、hive on spark
参考文档:
https://cwiki.apache.org/confluence/display/Hive/Hive+on+Spark%3A+Getting+Started#space-menu-link-content
如果内置spark不支持hive on spark,需要引入外置spark
spark源码包下载地址:
链接: http://archive.apache.org/dist/spark/.
不同版本编译源码包的方式:
Spark 2.0.0前
./make-distribution.sh --name “hadoop2-without-hive” --tgz “-Pyarn,hadoop-provided,hadoop-2.4,parquet-provided”
从Spark 2.0.0开始
./dev/make-distribution.sh --name “hadoop2-without-hive” --tgz “-Pyarn,hadoop-provided,hadoop-2.7,parquet-provided”
从Spark 2.3.0开始
./dev/make-distribution.sh --name “hadoop2-without-hive” --tgz “-Pyarn,hadoop-provided,hadoop-2.7,parquet-provided”
编译完成后,在目录下会出现spark-1.5.1-bin-hadoop2-without-hive.gz。
将包解压即可。
需要公平的调度程序,而不是容量调度程序。这公平地为 YARN 群集中的作业分配了相等份额的资源。
yarn.resourcemanager.scheduler.class=org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler
–备注:网上很多说需要这步,但其实默认的容量调度器(org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler)也是可以的。
而且如果改成公平调度,在ambari页面无法配置yarn队列及资源
添加spark的依赖到hive
①Hive 2.2.0之前,将spark-assembly jar放到HIVE_HOME/lib下
②Hive 2.2.0之后,没有了spark-assembly jar。在Yarn模式运行时,需要将以下三个包放在HIVE_HOME/lib下 :scala-library、spark-core、spark-network-common。
③要以 LOCAL 模式运行(仅用于调试),请将除上述 jar 外的以下 jar 链接到 。$HIVE_HOME/lib下
chill-java chill jackson-module-paranamer jackson-module-scala jersey-container-servlet-core
jersey-server json4s-ast kryo-shaded minlog scala-xml spark-launcher
spark-network-shuffle spark-unsafe xbean-asm5-shaded
设置执行引擎:
set hive.execution.engine=spark;
为 Hive 配置 Spark 应用程序配置
请参见:
链接: http://spark.apache.org/docs/latest/configuration.html
这可以通过将这些属性的文件"spark-defaults.conf"添加到 Hive 类路径中,或者将它们设置在 Hive 配置 () 上来完成。例如:hive-site.xml
set spark.master=<Spark Master URL>
set spark.eventLog.enabled=true;
set spark.eventLog.dir=<Spark event log folder (must exist)>
set spark.executor.memory=512m;
set spark.serializer=org.apache.spark.serializer.KryoSerializer;
允许 Yarn 在节点上缓存必要的 spark 依赖项 jar
在 Hive 2.2.0 之前,将 spark-assembly jar 上传到 hdfs 文件(例如:hdfs://xxxx:8020/spark-assembly.jar),然后在 hive-site 中添加以下内容.xml
修改启动脚本:
vim spark-env.sh
插入如下代码:
export SPARK_DIST_CLASSPATH=$(hadoop classpath)


















 873
873

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









