 深学习聊天机器人
深学习聊天机器人







 本文探讨了使用深度学习技术构建聊天机器人的多种方法,包括检索型和生成型模型,并讨论了短对话与长对话、开放域与封闭域的不同挑战。
本文探讨了使用深度学习技术构建聊天机器人的多种方法,包括检索型和生成型模型,并讨论了短对话与长对话、开放域与封闭域的不同挑战。
Chatbots, also called Conversational Agents or Dialog Systems, are a hot topic. Microsoft is making big bets on chatbots, and so are companies like Facebook (M), Apple (Siri), Google, WeChat, and Slack. There is a new wave of startups trying to change how consumers interact with services by building consumer apps like Operator or x.ai, bot platforms like Chatfuel, and bot libraries like Howdy’s Botkit. Microsoft recently released their own bot developer framework.
Many companies are hoping to develop bots to have natural conversations indistinguishable from human ones, and many are claiming to be using NLP and Deep Learning techniques to make this possible. But with all the hype around AI it’s sometimes difficult to tell fact from fiction.
In this series I want to go over some of the Deep Learning techniques that are used to build conversational agents, starting off by explaining where we are right now, what’s possible, and what will stay nearly impossible for at least a little while. This post will serve as an introduction, and we’ll get into the implementation details in upcoming posts.
A taxonomy of models
Retrieval-Based vs. Generative Models
Retrieval-based models (easier) use a repository of predefined responses and some kind of heuristic to pick an appropriate response based on the input and context. The heuristic could be as simple as a rule-based expression match, or as complex as an ensemble of Machine Learning classifiers. These systems don’t generate any new text, they just pick a response from a fixed set.
Generative models (harder) don’t rely on pre-defined responses. They generate new responses from scratch. Generative models are typically based on Machine Translation techniques, but instead of translating from one language to another, we “translate” from an input to an output (response).
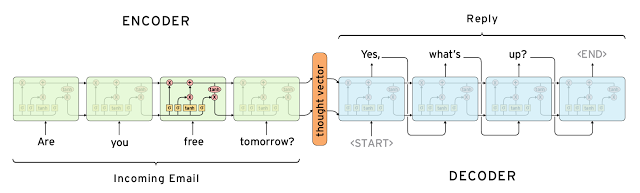
Both approaches have some obvious pros and cons. Due to the repository of handcrafted responses, retrieval-based methods don’t make grammatical mistakes. However, they may be unable to handle unseen cases for which no appropriate predefined response exists. For the same reasons, these models can’t refer back to contextual entity information like names mentioned earlier in the conversation. Generative models are “smarter”. They can refer back to entities in the input and give the impression that you’re talking to a human. However, these models are hard to train, are quite likely to make grammatical mistakes (especially on longer sentences), and typically require huge amounts of training data.
Deep Learning techniques can be used for both retrieval-based or generative models, but research seems to be moving into the generative direction. Deep Learning architectures like Sequence to Sequence are uniquely suited for generating text and researchers are hoping to make rapid progress in this area. However, we’re still at the early stages of building generative models that work reasonably well. Production systems are more likely to be retrieval-based for now.
Long vs. Short Conversations
The longer the conversation the more difficult to automate it. On one side of the spectrum are Short-Text Conversations (easier) where the goal is to create a single response to a single input. For example, you may receive a specific question from a user and reply with an appropriate answer. Then there are long conversations (harder) where you go through multiple turns and need to keep track of what has been said. Customer support conversations are typically long conversational threads with multiple questions.
Open Domain vs. Closed Domain
In an open domain (harder) setting the user can take the conversation anywhere. There isn’t necessarily have a well-defined goal or intention. Conversations on social media sites like Twitter and Reddit are typically open domain – they can go into all kinds of directions. The infinite number of topics and the fact that a certain amount of world knowledge is required to create reasonable responses makes this a hard problem.
In a closed domain (easier) setting the space of possible inputs and outputs is somewhat limited because the system is trying to achieve a very specific goal. Technical Customer Support or Shopping Assistants are examples of closed domain problems. These systems don’t need to be able to talk about politics, they just need to fulfill their specific task as efficiently as possible. Sure, users can still take the conversation anywhere they want, but the system isn’t required to handle all these cases – and the users don’t expect it to.
Common Challenges
There are some obvious and not-so-obvious challenges when building conversational agents most of which are active research areas.
Incorporating Context
To produce sensible responses systems may need to incorporate both linguistic context and physical context. In long dialogs people keep track of what has been said and what information has been exchanged. That’s an example of linguistic context. The most common approach is to embed the conversation into a vector, but doing that with long conversations is challenging. Experiments in Building End-To-End Dialogue Systems Using Generative Hierarchical Neural Network Models and Attention with Intention for a Neural Network Conversation Model both go into that direction. One may also need to incorporate other kinds of contextual data such as date/time, location, or information about a user.
Coherent Personality
When generating responses the agent should ideally produce consistent answers to semantically identical inputs. For example, you want to get the same reply to “How old are you?” and “What is your age?”. This may sound simple, but incorporating such fixed knowledge or “personality” into models is very much a research problem. Many systems learn to generate linguistic plausible responses, but they are not trained to generate semantically consistent ones. Usually that’s because they are trained on a lot of data from multiple different users. Models like that in A Persona-Based Neural Conversation Model are making first steps into the direction of explicitly modeling a personality.

Evaluation of Models
The ideal way to evaluate a conversational agent is to measure whether or not it is fulfilling its task, e.g. solve a customer support problem, in a given conversation. But such labels are expensive to obtain because they require human judgment and evaluation. Sometimes there is no well-defined goal, as is the case with open-domain models. Common metrics such as BLEU that are used for Machine Translation and are based on text matching aren’t well suited because sensible responses can contain completely different words or phrases. In fact, in How NOT To Evaluate Your Dialogue System: An Empirical Study of Unsupervised Evaluation Metrics for Dialogue Response Generation researchers find that none of the commonly used metrics really correlate with human judgment.
Intention and Diversity
A common problem with generative systems is that they tend to produce generic responses like “That’s great!” or “I don’t know” that work for a lot of input cases. Early versions of Google’s Smart Reply tended to respond with “I love you” to almost anything. That’s partly a result of how these systems are trained, both in terms of data and in terms of actual training objective/algorithm. Some researchers have tried to artificially promote diversity through various objective functions. However, humans typically produce responses that are specific to the input and carry an intention. Because generative systems (and particularly open-domain systems) aren’t trained to have specific intentions they lack this kind of diversity.
How well does it actually work?
Given all the cutting edge research right now, where are we and how well do these systems actually work? Let’s consider our taxonomy again. A retrieval-based open domain system is obviously impossible because you can never handcraft enough responses to cover all cases. A generative open-domain system is almost Artificial General Intelligence (AGI) because it needs to handle all possible scenarios. We’re very far away from that as well (but a lot of research is going on in that area).
This leaves us with problems in restricted domains where both generative and retrieval based methods are appropriate. The longer the conversations and the more important the context, the more difficult the problem becomes.
In a recent interview, Andrew Ng, now chief scientist of Baidu, puts it well:
Many companies start off by outsourcing their conversations to human workers and promise that they can “automate” it once they’ve collected enough data. That’s likely to happen only if they are operating in a pretty narrow domain – like a chat interface to call an Uber for example. Anything that’s a bit more open domain (like sales emails) is beyond what we can currently do. However, we can also use these systems to assist human workers by proposing and correcting responses. That’s much more feasible.
Grammatical mistakes in production systems are very costly and may drive away users. That’s why most systems are probably best off using retrieval-based methods that are free of grammatical errors and offensive responses. If companies can somehow get their hands on huge amounts of data then generative models become feasible – but they must be assisted by other techniques to prevent them from going off the rails like Microsoft’s Tay did.
Upcoming & Reading List
We’ll get into the technical details of how to implement retrieval-based and generative conversational models using Deep Learning in the next post, but if you’re interested in looking at some of the research then the following papers are a good starting point:
- Neural Responding Machine for Short-Text Conversation (2015-03)
- A Neural Conversational Model (2015-06)
- A Neural Network Approach to Context-Sensitive Generation of Conversational Responses (2015-06)
- The Ubuntu Dialogue Corpus: A Large Dataset for Research in Unstructured Multi-Turn Dialogue Systems (2015-06)
- Building End-To-End Dialogue Systems Using Generative Hierarchical Neural Network Models (2015-07)
- A Diversity-Promoting Objective Function for Neural Conversation Models (2015-10)
- Attention with Intention for a Neural Network Conversation Model (2015-10)
- Improved Deep Learning Baselines for Ubuntu Corpus Dialogs (2015-10)
- A Survey of Available Corpora for Building Data-Driven Dialogue Systems (2015-12)
- Incorporating Copying Mechanism in Sequence-to-Sequence Learning (2016-03)
- A Persona-Based Neural Conversation Model (2016-03)
- How NOT To Evaluate Your Dialogue System: An Empirical Study of Unsupervised Evaluation Metrics for Dialogue Response Generation (2016-03)
Source: http://www.wildml.com/2016/04/deep-learning-for-chatbots-part-1-introduction/

















 448
448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









