







 本文详细介绍了Linux中的find命令,包括基本用法、忽略大小写、指定文件类型、排除目录、忽略错误、按用户查找、按大小搜索、组合条件、使用or搜索以及exec和xargs参数的区别。还提到了locate命令的使用,如创建数据库索引、配置文件及常用参数,并给出了多个实用示例。
本文详细介绍了Linux中的find命令,包括基本用法、忽略大小写、指定文件类型、排除目录、忽略错误、按用户查找、按大小搜索、组合条件、使用or搜索以及exec和xargs参数的区别。还提到了locate命令的使用,如创建数据库索引、配置文件及常用参数,并给出了多个实用示例。
find命令常用
find命令格式
参考 :
https://wangchujiang.com/linux-command/c/find.html
https://www.linuxcool.com/find
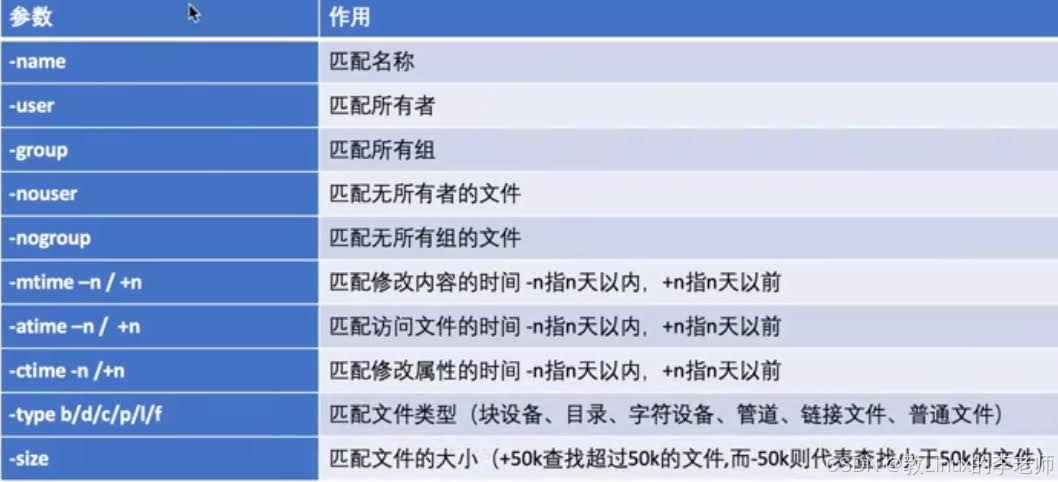
通过文件名搜索
# find 查找范围 查找参数
find / -name 文件名
-i 忽略文件名大小写
# -i 忽略文件名大小写
find / -iname Abc
-type指定文件类型
# -type d 只列出所有目录
# -type f 文件
# -type l 符号链接
find . -type d -print
排除搜索目录
参考:https://blog.51cto.com/u_2225052/5917805
排除一个目录
# 使用prune开关,例如,如果要排除misc目录
## -path "要排除的目录名" -prune -o
find . -path ./misc -prune -o -name '*.txt' -print
排除多个目录
## \( -path dir1 -o -path dir2 \) -prune -o
find . -type d \( -path dir1 -o -path dir2 -o -path dir3 \) -prune -o -print
忽略错误结果
# 忽略错误结果
find / -iname Abc 2>>/dev/null
-user按照文件的用户(文件所有人)查找
# 查找root的文件
find -user root
-size根据文件大小搜索
# 搜索大于100M的文件
find / -size +100M
# 搜索大于100M的文件并以列表形式展示
find / -size +100M | xargs ls -lh
-size组合条件
# 搜索大于30G小于3T的文件,并列出详情
find / -size +30G -size -3000G 2>>/dev/null | xargs ls -lh

-or搜索多个文件名
-or也可以简写为-o
# 使用-or来选择多个文件名
find . -name "Test.class" -or -name "Test$"*
# 当前目录及子目录下查找所有以.txt和.pdf结尾的文件
## \是防止转义符
find . \( -name "*.txt" -o -name "*.pdf" \)
exec和xargs参数的区别
参考: https://www.linuxprobe.com/shell-xargs-exec.html
xargs参数—推荐
从标准输入流中获取参数,并基于它们执行命令
将前面的结果作为输出给后面去用
搜索包含某字符串的文件
# 搜索包含某字符串的文件
## grep -r 递归搜索
## grep -i 忽略大小写
find .|xargs grep -ri "要查找的字符串"
exec参数—不推荐
适用于执行带源带目的的动作
搜索所有的rpm包并将rpm包移动到某个目录
# 搜索所有的rpm包并将rpm包移动到某个目录
find ./ -name *rpm -exec mv {} . \;
查找用户 ID 不存在的文件-nouser
# 查找用户 ID 不存在的文件
find / -nouser
查找群组 ID 不存在的文件-nogroup
# 查找群组 ID 不存在的文件
find / -nogroup
找出无主的文件或目录,并确定这些文件是否为空
# 找出无主的文件或目录,并确定这些文件是否为空
find / -nouser | xargs -i test -s {} && echo $?
查找系统中的空链接文件
# 查找系统中的空链接文件
## -type l:表示查找符号链接文件
## -follow:表示跟随符号链接
## 2>/dev/null:将标准错误输出重定向到/dev/null
find dirname -type l -follow 2>/dev/null
练习

答案:
# 创建目录
mkdir /root/dfiles
# 查找文件并放入目录
find / -type f -user user3 -exec cp -a {} /root/dfiles \;
脚本
#!/bin/bash
find /usr -type f -perm /g=s -size +3M -size -5M -exec cp -a {} /root/dfiles \;
find /usr -type f -perm /u+s -size +30k -size -50k -exec cp -a {} /root/dfiles \;
locate搜索
locate是find的加强版,需要先在本地创建索引,搜索速度非常快.
- 缺点是依赖索引数据库,非实时查找,数据库每天更新一遍.所以可能找不到最新的文件;
- 优点是查找速度非常快,秒查。
安装locate
# Centos7安装mlocate
yum install mlocate -y
# Ubuntu安装mlocate
apt install mlocate -y
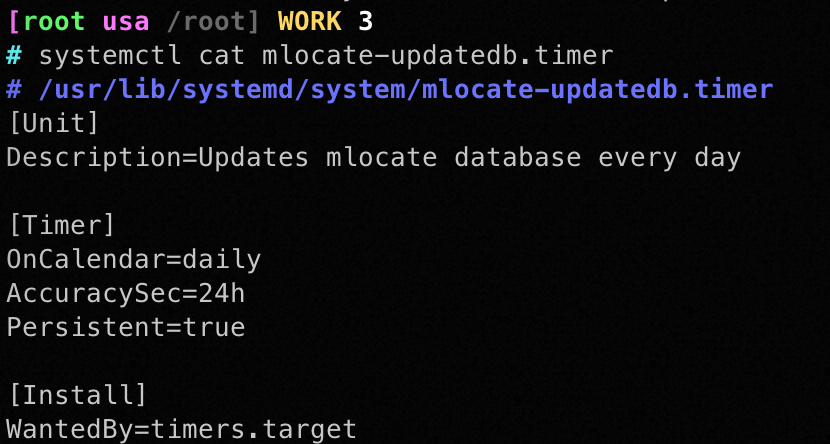
mlocate-updatedb.timer定时器
# 查看mlocate-updatedb.timer定时器是否自启动
systemctl is-enabled mlocate-updatedb.timer

# 查看mlocate-updatedb.timer定时器的配置
systemctl cat mlocate-updatedb.timer
# 如下图所示,每24小事运行一次
创建数据库索引(必须执行)
第一次使用前必须创建数据库索引。
https://blog.youkuaiyun.com/xiexieya233/article/details/121430628
-o <文件>:忽略默认的数据库文件,使用指定的slocate数据库文件;
-U <目录>:更新指定目录的slocate数据库;
-v:显示执行的详细过程;
# 本地数据变化后需要先更新数据库--默认会每天更新数据库
updatedb
# 更新指定目录的slocate数据库
## -o<文件>:忽略默认的数据库文件,使用指定的slocate数据库文件;
## -U<目录>:更新指定目录的slocate数据库;
## -v:显示执行的详细过程;
updatedb -U <目录>
updatedb的配置文件/etc/updatedb.conf
参考: https://blog.youkuaiyun.com/weixin_37335761/article/details/122168037
https://rumenz.com/rumenbiji/linux-locate.html
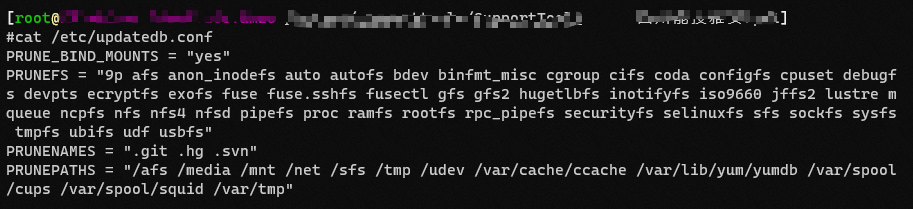
cat /etc/updatedb.conf
# 打印
#开启搜索限制
PRUNE_BIND_MOUNTS = “yes”
#搜索时不搜索的文件系统
PRUNEFS =
#搜索时不搜索的文件类型
PRUNENAMES =
# 搜索时不搜索的路径
PRUNEPATHS =
locate常用参数
| 参数 | 解释 |
|---|---|
| -A | –all 只打印匹配所有模式的条目 |
| -b | –basename 仅匹配路径名的基本名称 |
| -c | –count 仅打印找到的条目数量 |
| -d | –database DBPATH 使用DBPATH而不是默认数据库(默认为/var/lib/mlocate/mlocate.db) |
| -e | –existing 仅打印当前存在文件的条目 |
| -L | –follow 在检查文件存在性时跟踪符号链接(默认) |
| -h | –help 打印此帮助信息 |
| -i | –ignore-case 匹配模式时忽略大小写区分 |
| -l | –limit, -n LIMIT 将输出(或计数)限制为LIMIT条目 |
| -m | –mmap 忽略,为了向后兼容性 |
| -P | –nofollow, -H 在检查文件存在性时不跟踪符号链接 |
| -0 | –null 在输出时使用NUL分隔条目 |
| -S | –statistics 不搜索条目,打印每个使用数据库的统计信息 |
| -q | –quiet 关于读取数据库的错误信息不报告 |
| -r | –regexp REGEXP 用基本的正则表达式REGEXP搜索而不是模式 –regex 模式是扩展正则表达式 |
| -s | –stdio 忽略,为了向后兼容性 |
| -V | –version 打印版本信息 |
| -w | –wholename 匹配整个路径名(默认) |
查看locate版本
# 查看locate版本
locate -V
查看数据库位置
# 查看数据库位置及索引数量
locate -S

示例
查找和pwd相关的所有文件(文件名中包含pwd)
# 搜索文件名
locate 文件名
# 忽略大小写
locate -i 关键字
搜索指定路径下的文件
# 搜索etc目录下所有以sh开头的文件
locate /etc/sh
## -b –-basename 仅匹配路径名的基本名称
locate -b 路径/*/关键字
使用正则表达式匹配
# 查找/var目录下,以reason结尾的文件
locate -r '^/var.*reason$'(其中.表示一个字符,*表示任务多个;.*表示任意多个字符)


















 3384
3384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











