




 本文深入解析了MHA(Master High Availability)的故障切换和数据恢复过程,包括选主策略、日志补偿及故障转移步骤。在主库宕机时,MHA会选择最近同步的从库作为新主,保存旧主的binlog,通过差异日志修复其他从库,确保数据一致性。此外,还介绍了当主库SSH无法连接时的日志补偿方法和自动故障转移机制,确保系统的高可用性。
本文深入解析了MHA(Master High Availability)的故障切换和数据恢复过程,包括选主策略、日志补偿及故障转移步骤。在主库宕机时,MHA会选择最近同步的从库作为新主,保存旧主的binlog,通过差异日志修复其他从库,确保数据一致性。此外,还介绍了当主库SSH无法连接时的日志补偿方法和自动故障转移机制,确保系统的高可用性。
[深入浅出]MHA FailOver 原理
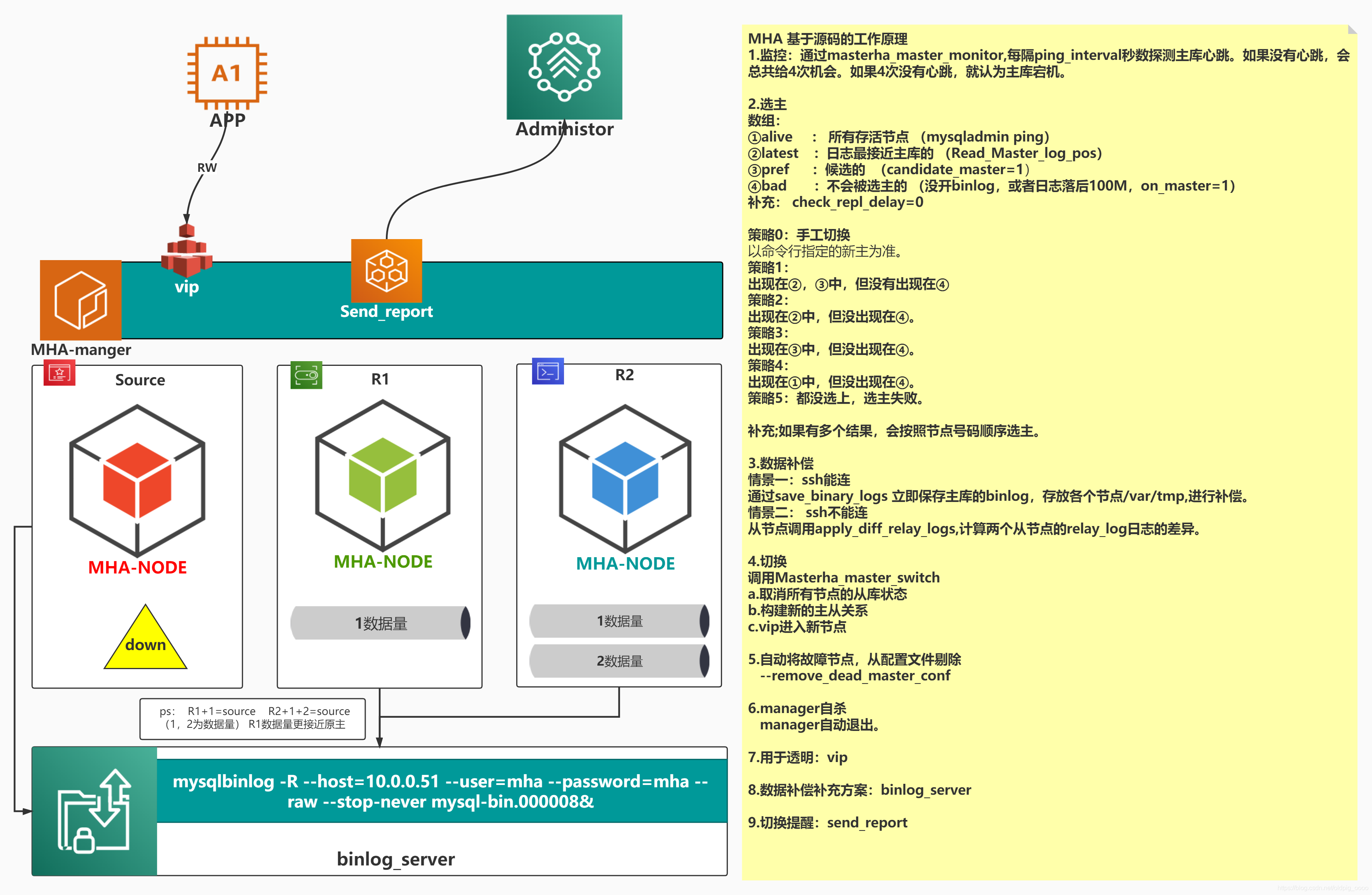
1、通过 masterha_master_monitor ,每隔ping_interval秒探测一次Master状态,如果状态异常,探测四次失败后,进行选主。
1)把宕机的master二进制日志保存下来。
2)找到binlog位置点最新的slave。
3)在binlog位置点最新的slave上用relay log(差异日志)修复其它slave。
4)将宕机的master上保存下来的二进制日志恢复到含有最新位置点的slave上。
5)将含有最新位置点binlog所在的slave提升为master。
6)将其它slave重新指向新提升的master,并开启主从复制。
监控所有node节点MHA功能说明:
2、自动故障切换(failover)
前提是必须有三个节点存在,并且有两个从库
(1)选主前提,按照配置文件的顺序进行,但是如果此节点后主库100M以上relay-log就不会选
(2)如果你设置了权重,总会切换带此节点;一般在多地多中心的情况下,一般会把权重设置在本地
节点。
(3)选择R1为新主
(4)保存主库binlog日志
3、重新构建主从
(1)将有问题的节点剔除MHA
进行第一阶段数据补偿,R2缺失部分补全90
(2)R1切换角色为新主,将R2指向新主R1
s2 change master to R1
(3) 第二阶段数据补偿
将保存过来的新主和原有主缺失部分的binlog,应用到新主。
(4)虚拟IP漂移到新主,对应用透明无感知
(5)通知管理员故障切换
选主策略
通过其他节点Master_Log_File的bin日志和Read_Master_Log_Pos号对比,选择最接近主库数据的节
点。
无GTID:
[root@db02 ~] mysql -e "show slave status\G" |grep "Master_Log"
Master_Log_File: mysql-bin.000003
Read_Master_Log_Pos: 194
有GTID:
[root@db02 ~] mysql -e "show slave status\G" |grep "Executed_Gtid_Set"
Executed_Gtid_Set: 1c35b73a-7321-11ea-8974-000c29248f69:1-6
如果没有权重,从库日志量一样
根据配置文件的先后顺序选择新主
[server1]
hostname=10.0.0.88
port=3306
[server2]
hostname=10.0.0.89
port=3306
[server3]
hostname=10.0.0.90
port=3306
从库日志量和主库延时100M以上会被直接弃用
日志补偿
if 主库ssh能连接
各个从节点,通过save_binary_logs 立即保存缺失部分的binlog到/var/tmp/xxxxx
[root@db01 ~] mysql -e "show master status;"
[root@db02 ~] mysql -e "show slave status\G" |grep "Retrieved_Gtid_Set"
eles 主库ssh不能连接
从节点调用apply_diff_relay_logs,计算两个从节点的relay-log日志差异。
故障转移
1. 取消所有节点的从库状态
2. 构建新的主从关系
自动将故障节点,从配置文件剔除
--remove_dead_master_conf
自杀
manager自动退出
---------------------------------------------
纸上得来终觉浅,绝知此事要躬行。

















 761
761

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









