







SPI是什么
SPI全称Service Provider Interface。是Java提供的一套用来被第三方实现或者扩展的API,它可以用于框架扩展和替换组件。是一种 “基于接口的编程+策略模式+配置文件” 组合实现的动态加载机制。换句话说,就是框架提供接口,具体实现交给组件提供方。整体机制如下(来源 高级开发必须理解的Java中SPI机制):
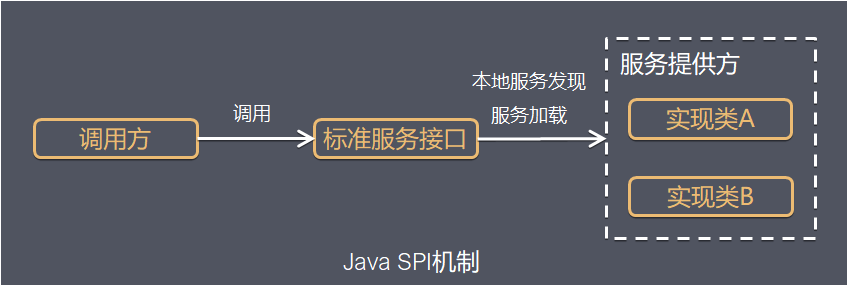
使用场景
正如前边所说,SPI适用于:调用者根据业务需求,启用、扩展、或者替换框架的实现策略。
比较常见的例子:
- 数据库驱动加载接口实现类的加载,比如:JDBC加载不同类型数据库的驱动
- 日志门面接口实现类加载,比如:Slf4j加载不同提供商的日志实现类
- Dubbo,Dubbo中也大量使用SPI的方式实现框架的扩展, 不过它对Java提供的原生SPI做了封装,更方便更强大。
使用方法
要使用Java SPI,需要遵循如下约定:
1、当服务提供者提供了接口的一种具体实现后,在jar包的
META-INF/services目录下创建一个以“接口全限定名”为命名的文件,内容为实现类的全限定名;
2、接口实现类所在的jar包放在主程序的classpath中;
3、主程序通过java.util.ServiceLoder动态装载实现模块,它通过扫描META-INF/services目录下的配置文件找到实现类的全限定名,把类加载到JVM;
4、SPI的实现类必须携带一个不带参数的构造方法;
为什么要有这些约定呢,可以看看关键类 ServiceLoader 的源码:
public final class ServiceLoader<S>
implements Iterable<S>
{
// 遍历的目录路径
private static final String PREFIX = "META-INF/services/";
public static <S> ServiceLoader<S> load(Class<S> service,
ClassLoader loader)
{
return new ServiceLoader<>(service, loader);
}
public static <S> ServiceLoader<S> load(Class<S> service) {
ClassLoader cl = Thread.currentThread().getContextClassLoader();
return ServiceLoader.load(service, cl);
}
}
首先ServiceLoader实现了Iterable接口,说明它可迭代的,当我们通过load方法加载一个接口类时,会返回一个ServiceLoader对象,遍历其就可以得到不同的实现类。那么再来看看ServiceLoader是如何实现Iterable接口中的方法的:
private class LazyIterator
implements Iterator<S>
{
Class<S> service;
ClassLoader loader;
Enumeration<URL> configs = null;
Iterator<String> pending = null;
String nextName = null;
private LazyIterator(Class<S> service, ClassLoader loader) {
this.service = service;
this.loader = loader;
}
private boolean hasNextService() {
if (nextName != null) {
return true;
}
if (configs == null) {
try {
String fullName = PREFIX + service.getName(); // 1.
if (loader == null)
configs = ClassLoader.getSystemResources(fullName);
else
configs = loader.getResources(fullName);
} catch (IOException x) {}
}
while ((pending == null) || !pending.hasNext()) {
if (!configs.hasMoreElements()) {
return false;
}
pending = parse(service, configs.nextElement()); // 2.
}
nextName = pending.next(); // 3.
return true;
}
private S nextService() {
if (!hasNextService())
throw new NoSuchElementException();
String cn = nextName; // 4.
nextName = null;
Class<?> c = null;
try {
c = Class.forName(cn, false, loader); // 5.
} catch (ClassNotFoundException x) {}
try {
S p = service.cast(c.newInstance()); // 6.
providers.put(cn, p); // 7.
return p;
} catch (Throwable x) {}
}
// public boolean hasNext() {}
// public S next() {}
}
熟悉的操作,依然是借助一个内部类实现的,hasNext()和next()方法省略,内部主要是调用了hasNextService()和nextService(),对于标注释处:
- 通过
PREFIX + service.getName()组装文件名,正如前边所示,PREFIX是一个字符串,内容为META-INF/services/,所以这也就对应了前边说的约定第1点:”在jar包的META-INF/services目录下创建一个以“接口全限定名”为命名的文件”。 - 找到1所对应的文件后,会加载并解析它,这里就是解析的操作,具体
parse方法其实就是基本的文件操作,将文件内容按行解析组成一个Iterator<String>返回给pending。对应约定第1点后半句:“内容为实现类的全限定名”。 - 这里是每次取出
pending中的一个元素,即每个具体的实现类全限定名,赋值给nextName,这里是延迟加载的思想,即在调用hasNextService()时,并不加载具体的类,仅将类名保存在nextName。 - 当调用
nextService()时,就得返回具体的实现类了。在4处取得nextName,并将nextName置空,这样在下次调用时可以从pending中重新获取下一个类名;并在5处通过Class.forName来加载这个实现类;6处转型为对应的接口类型;7处做缓存,然后返回。这里其实也对应的上述约定的第4点:“SPI的实现类必须携带一个不带参数的构造方法”,因为在6处是通过c.newInstance()来获得实现类的。
数据库连接中的应用
了解了SPI的原理后,看看它在实际中的应用,比如对于MySQL的数据库连接驱动包里,就有对应的文件:

内容为:
com.mysql.cj.jdbc.Driver
表示 com.mysql.cj.jdbc.Driver 这个类实现了 java.sql.Driver 这个接口。而这个类是如何被扫描到的呢?查看负责加载驱动的DriverManager类:
public class DriverManager {
// List of registered JDBC drivers
private final static CopyOnWriteArrayList<DriverInfo> registeredDrivers = new CopyOnWriteArrayList<>();
static {
loadInitialDrivers();
}
private static void loadInitialDrivers() {
// ...
AccessController.doPrivileged(new PrivilegedAction<Void>() {
public Void run() {
ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(Driver.class);
Iterator<Driver> driversIterator = loadedDrivers.iterator();
try{
while(driversIterator.hasNext()) {
driversIterator.next();
}
} catch(Throwable t) {
// Do nothing
}
return null;
}
});
// ...
}
}
这里省略了其它代码,仅保留了通过SPI加载的代码,可以看到,DriverMananger通过一个static代码块加载数据库驱动。SPI加载方式就是简单地通过调用 ServiceLoader.load(Driver.class);来获得一个可迭代对象,然后遍历其就可以加载所需驱动了。
至于为什么没有“注册”的操作,这是因为具体的数据库驱动类都会在自己被加载的时候主动把自己注册到DriverManager,比如对于 com.mysql.cj.jdbc.Driver 类,源码如下:
public class Driver extends NonRegisteringDriver implements java.sql.Driver {
public Driver() throws SQLException {
}
static {
try {
DriverManager.registerDriver(new Driver());
} catch (SQLException var1) {
throw new RuntimeException("Can't register driver!");
}
}
}
所以 DriverManager 只需要将驱动类加载进JVM即可。
Java SPI的不足
虽然使用Java SPI机制实现了解耦,使得第三方服务模块的装配控制的逻辑与调用者的业务代码分离。应用程序可以根据实际业务情况启用框架扩展或替换框架组件。第三方服务模块实现接口后,在第三方项目代码的META-INF/services目录下按要求配置一个文件,源码框架即可找到对应实现类。
不过Java 原生的SPI仍存在不足,比如:
- 虽然ServiceLoader号称是延迟加载,但是它是通过迭代器来获取的,这也就意味着,如果你仅需要某个指定的实现类,那也必须从头遍历去找,直到找到所需的那个,造成资源浪费。
- ServiceLoader类的实例是不是线程安全的。
Dubbo在Java SPI的基础上,实现了一套自己的SPI机制,功能更强大,感兴趣可以了解下。

















 1191
1191

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









