




 本文介绍了一种使用Python的requests和BeautifulSoup库从指定网站爬取美女图片的方法,并实现了图片的自动下载与保存。
本文介绍了一种使用Python的requests和BeautifulSoup库从指定网站爬取美女图片的方法,并实现了图片的自动下载与保存。
一 事件背景
本篇主要是生活分享。
公司研究了一个比较好玩的人工智能狗,我就想偷懒让它帮我写个代码,得到的漂亮小姐姐的照片,然后它还真的给我把代码弄出来了。
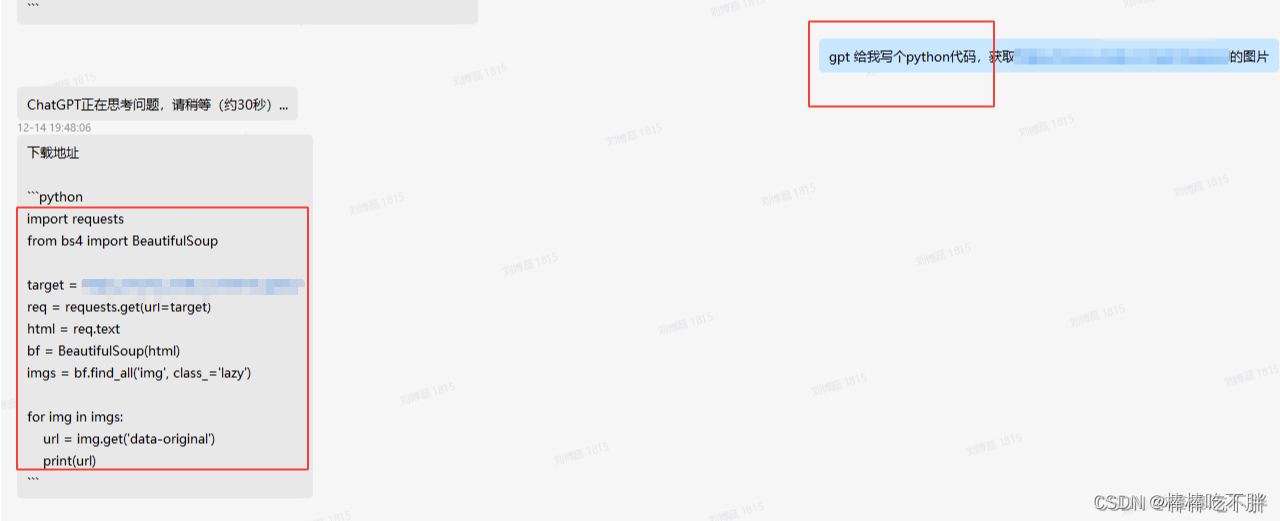
二 系统给的代码
代码的原文如下:
import requests
from bs4 import BeautifulSoup
target = 'https://www.umei.cc/meinvtupian/'
req = requests.get(url=target)
html = req.text
bf = BeautifulSoup(html)
imgs = bf.find_all('img', class_='lazy')
for img in imgs:
url = img.get('data-original')
print(url)
然后我试着跑了一下,执行结果如下图:
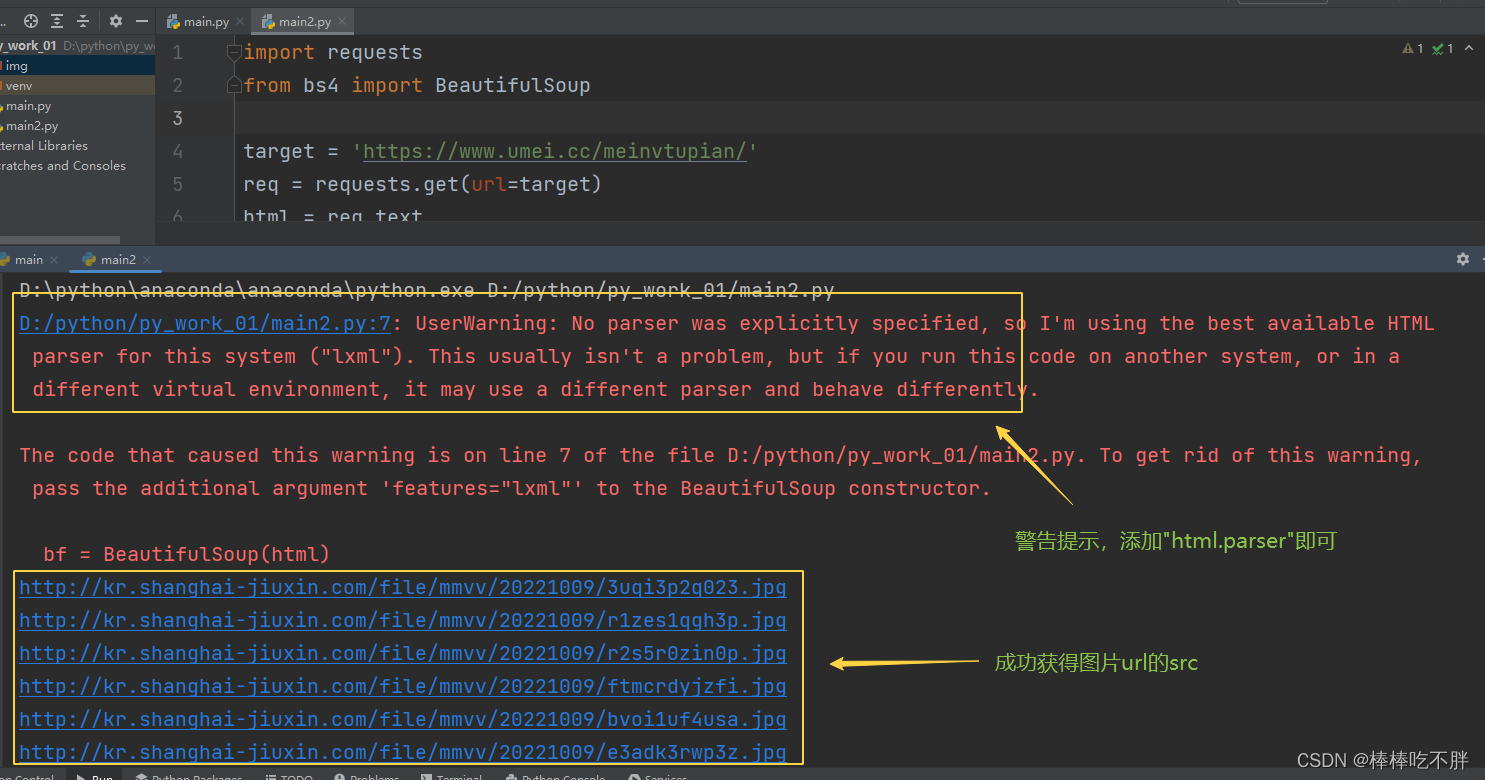
代码成功运行,而且也获取了我想要的那些图片的src地址。
虽然有一个警告提示信息,但是很容易解决。
将第七行括号后面加一个html.parser即可。
bf = BeautifulSoup(html,"html.parser")
也就是说,这段代码之前的步骤都是没有问题的。
三 改进措施
我们想要增加的功能,无非就是利用图片的src,然后直接下载保存到本地即可。
首先找到这些所有图片的src下载地址也就是变量imgs。在代码的最后,我们看到了将其遍历得到的每一个img,这些img就是每一张图片的下载地址。
接着找到每一张图片,下载后必然要为其命名,为了简单我们以/作为分隔符,将src最后面的字母数字编码作为每一张图片的名字。
然后,通过with open()函数,将文件下载到本地。
最后,记得关闭访问网站的请求连接。
四 改进后的代码
import requests
from bs4 import BeautifulSoup
target = 'https://www.umei.cc/meinvtupian/'
req = requests.get(url=target)
html = req.text
bf = BeautifulSoup(html,"html.parser")
imgs = bf.find_all('img', class_='lazy')
for img in imgs:
url = img.get('data-original')
# 得到每一张图片的名字
name = url.split("/")[-1]
# 得到每一张图片的下载地址
resp = requests.get(url)
# 将图片内容写入文件并保存至当前目录下的img/目录下
with open("img/"+name,mode="wb") as f:
f.write(resp.content)
# 每张图片下载完成后,输出结果
print(name,"is over!!!")
# 关闭访问请求的连接
req.close()

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









