




Abstract
我们提出了UniDetector,一个通用的对象检测器,它有能力在开放世界中识别巨大的类别。UniDetector通用性的关键点是:
1)通过图像和文本空间的对齐,利用多源图像和异构标签空间进行训练,保证了足够的信息用于通用表示。
2)由于视觉和语言两种形态的丰富信息,它很容易泛化到开放世界,同时保持了可见和不可见类别之间的平衡。
3)通过我们提出的解耦训练方式和概率校准,进一步提升了对新类别的泛化能力。
这些贡献使UniDetector能够检测超过7k个类别,这是迄今为止最大的可测量类别大小,只有大约500个类参与培训。我们的UniDetector在大型词汇数据集上表现出强大的零概率泛化能力——在没有看到任何相应图像的情况下,它比传统的监督基线平均高出4%以上。在13个具有各种场景的公共检测数据集上,UniDetector仅使用3%的训练数据就达到了最先进的性能。
网络架构图
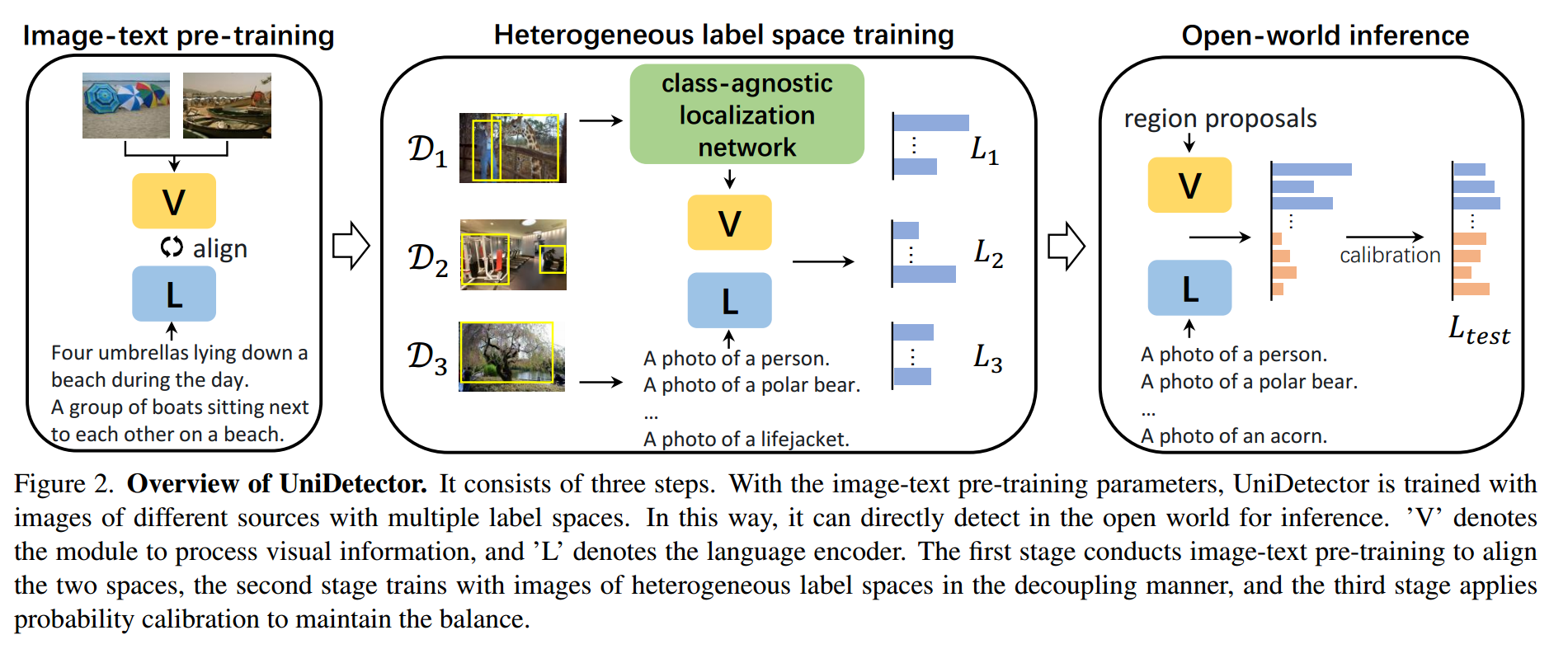
图2。UniDetector概述。它包括三个步骤。通过图像-文本预训练参数,UniDetector可以使用具有多个标签空间的不同来源的图像进行训练。这样,它可以直接在开放世界中进行检测进行推理。“V”表示处理视觉信息的模块,“L”表示语言编码器。第一阶段通过图像-文本预训练对齐两个空间,第二阶段通过解耦方式对异构标签空间的图像进行训练,第三阶段通过概率校准保持平衡。
</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 582
582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









