



本教程教你怎么使用工具训练数据集推理出你想要转换的声音音频,并且教你处理剪辑伴奏和训练后的音频合并一起,在文章的最后有用我自己声音处理的歌曲,有时间麻烦大家,可以给我点赞三连一下,嘿嘿
1.使用的工具(如何下载资源)
————搞懂ai训练的理念
从网络合法的获取歌曲视频,通过Adobe Audition把视频中音频剪辑出来。
再通过UVR5先将人声伴奏剥离开,然后进一步处理人声,让他干净。
再通过so-vits-svc的 webui将wav切分,切分完之后要进行分文件夹、写配置(config.json),搞出数据集
最后再使用数据集训练模型,模型训练完加载后,最后再把你想让ai唱的干声,放进去训练
最后再使用Adobe Audition把伴奏和人声合成就可以了。
要想训练ai声音,首先需要有各种工具,还需要我们提供你需要训练的声音,当然声音需要没有噪音存干声,如果要是歌曲就需要分离歌曲的背景和声音,然后将音频文件切分,切分的目的是为了保证训练不卡,否则音频文件太大,所以你知道我们需要什么工具了把!以下揭晓
Adobe Audition :我主要用这个提取mp4的音频文件,后期可以用这个剪辑将伴奏和音频合起来
UVR5:这个是专门背景与人声分离的软件,一键安装就可以
Audio Slicer(音频切分):这个可以不用专门下软件自己操作了,大神在webui里集成了,按一下自动切分。
so-vits-svc:最重要的工具,启动后是个webui界面,然后呢我们需要在里边训练自己的声音,转换声音等操作。
整合包使用优快云博主timberman666的:
提取码:g8n4
https://pan.baidu.com/share/init?surl=2u_LDyb5KSOfvjJ9LVwCIQ&pwd=g8n4
2.素材准备
2.1 AU提取音频
将mp4提取音频文件,用AU操作,操作如下:
我是要把我在bilibili录制的视频下载下来的,需要借助bilibili的一些工具才能下载下来视频,我用的是这个bilibili哔哩哔哩下载助手
bilibili哔哩哔哩下载助手:直接浏览器拓展搜这个名字,安装脚本就能使用,这个网上很多教程就不赘述了。
然后得到的视频可以拖到如下的位置,
然后点击这个文件右键将音频提取到文件,然后点击新出的音频文件再点击最上面的菜单文件保存或另存为然后就得到音频文件了。

2.2 UVR5提取干声
下面提取说明按需去取。
音频如果比较纯的声音无噪音则直接可以切分音频了,如果不纯的化可以处理下,打开url5,
这个是处理伴奏和人声分离的。

伴奏人声分离以后可以去听听纯声,发现其实会有一些和声和混响的,我们要去去掉这个和声混响,根据下面操作。

如果不是唱歌而是干声去噪也可以使用如下这种方式处理看看效果,我是纯的背景有点噪音,然后用了去和声混响处理的,也是有点效果的。

3.启动so-vits-svc
声音部分都处理完了,就可以启动webui了,进入so-vits-svc目录,双击启动启动WebUI,然后弹出来一个cmd弹框,

复制这个路径打开webui

上面这步不需要做,我的直接双击WebUI.bat就可以了。
webui的界面是这样的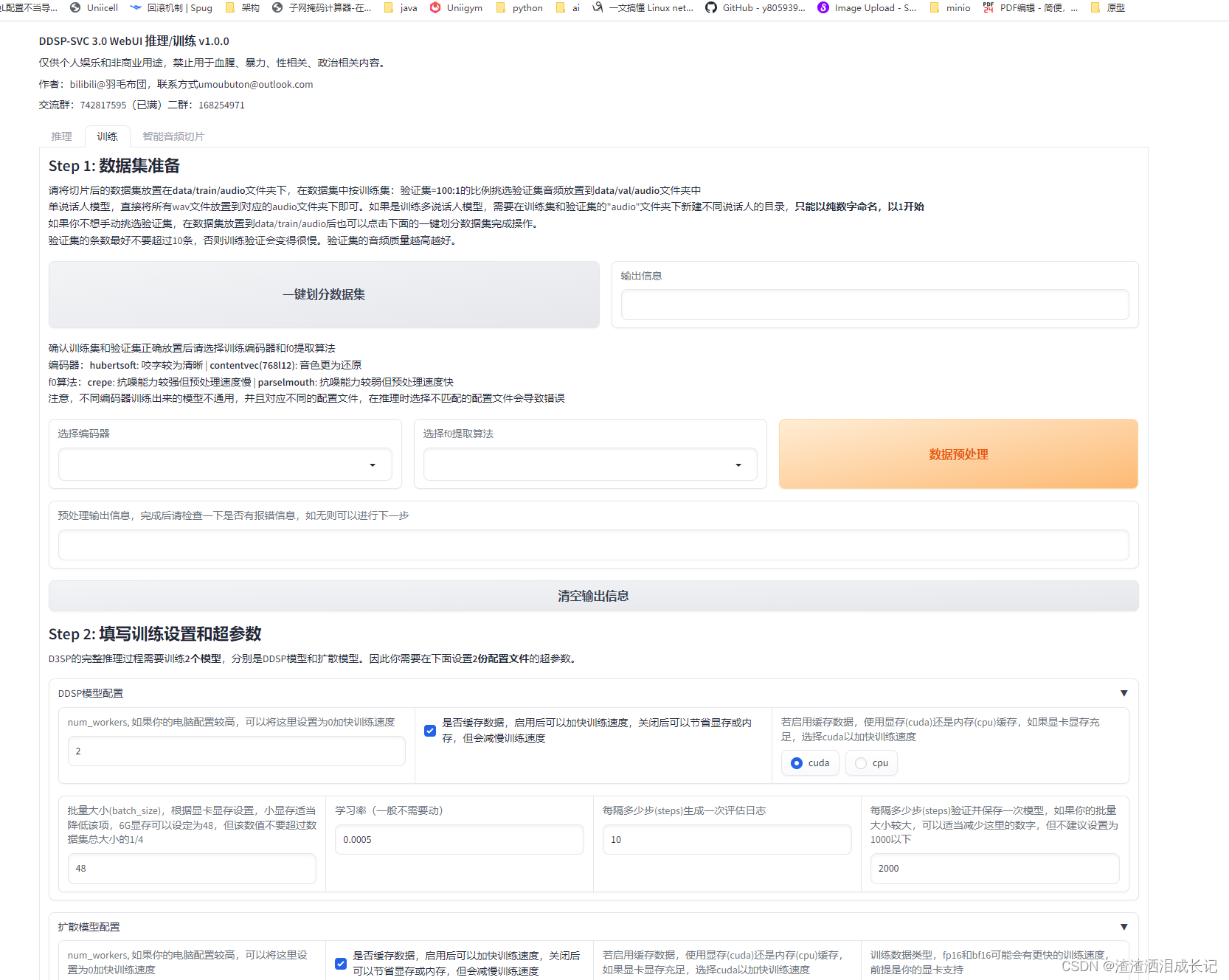
3.1 音频切分
这时就可以音频切分了,按照下面的说明去处理。切记,切分和识别数据集是一体的,你后面要追加,就重新切,然后重新分文件夹,记住

切分后的文件。
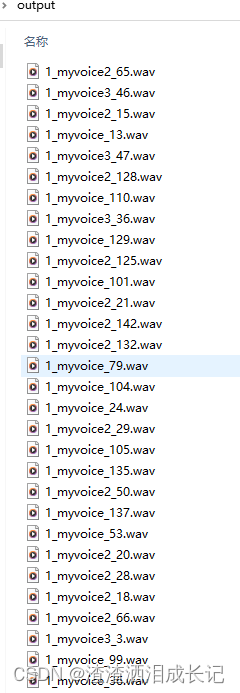
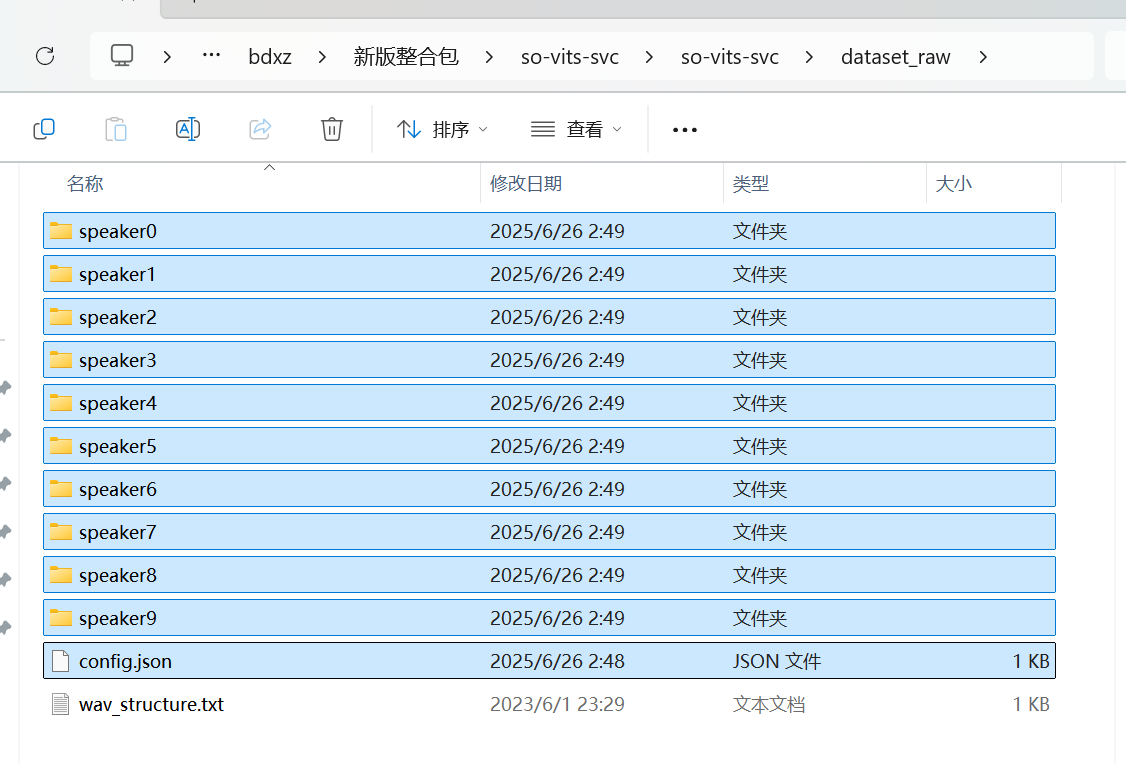
找到切分后的输出目录然后全部将块音频全部复制到此目录下:E:\bdxz\新版整合包\so-vits-svc\so-vits-svc\dataset_raw
反正就是so-vits-svc下面的dataset_raw
然后就需要编写配置文件了,可以参考我的
"n_speakers": 10,
"spk": {
"speaker0": 0,
"speaker1": 1,
"speaker2": 2,
"speaker3": 3,
"speaker4": 4,
"speaker5": 5,
"speaker6": 6,
"speaker7": 7,
"speaker8": 8,
"speaker9": 9
}
新建一个记事本,复制到记事本上,然后重命名为config.json。
我给你解释下什么意思,就是切分后的wav文件,你比切了10个音频文件,你就把名字一样归到一个文件夹里,然后重命名为speaker0,以此类推,"n_speakers": 后面就是10。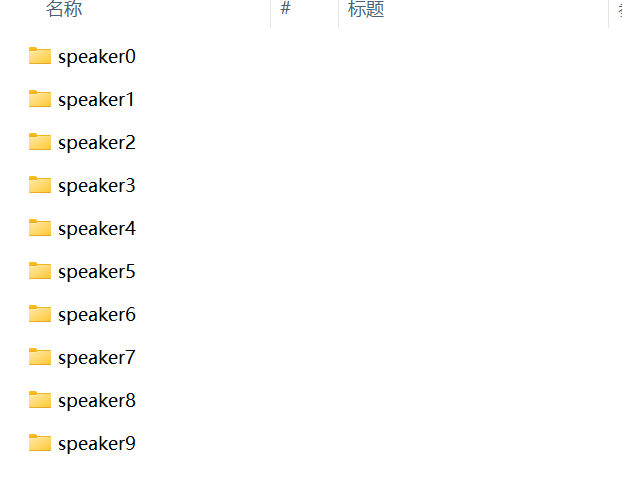
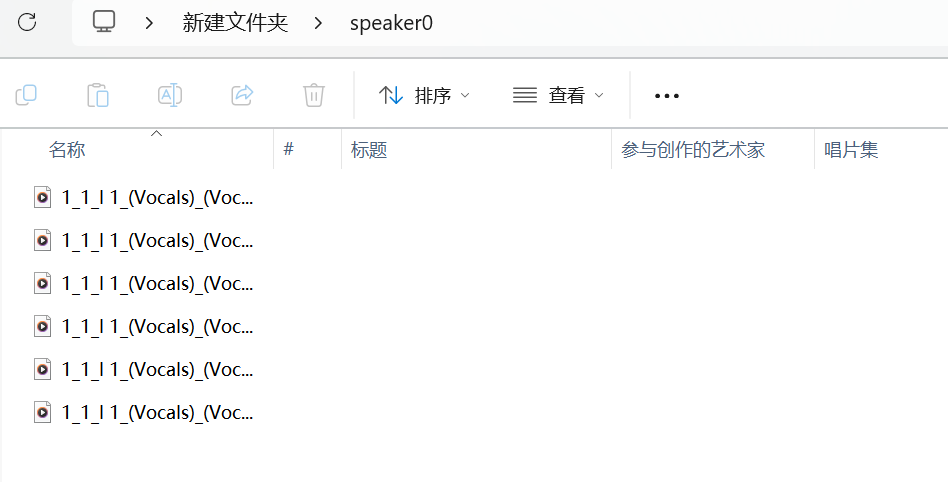
config.json配置写好,文件夹装好,你就把他们放到dataset_raw里面,如图
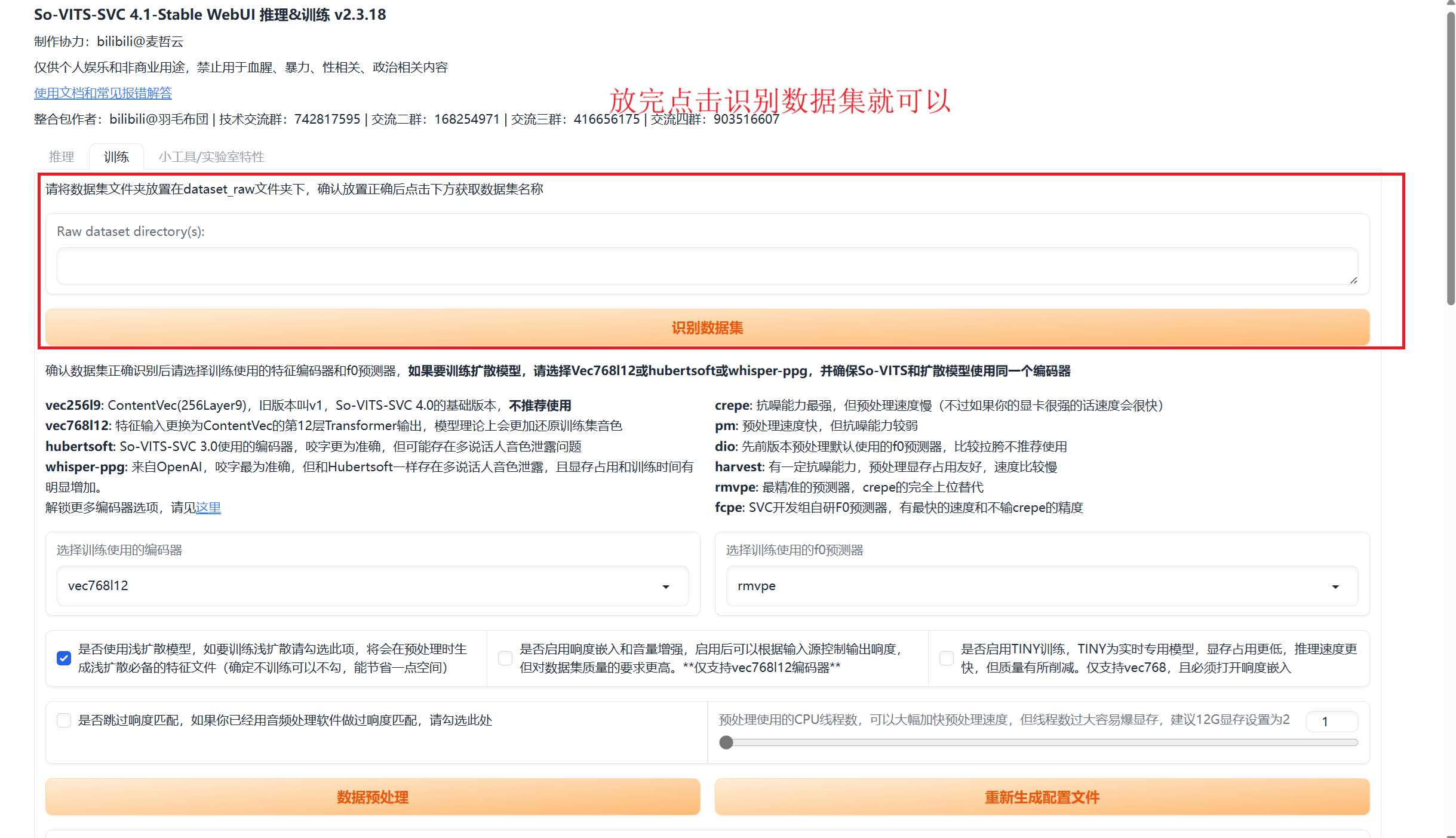
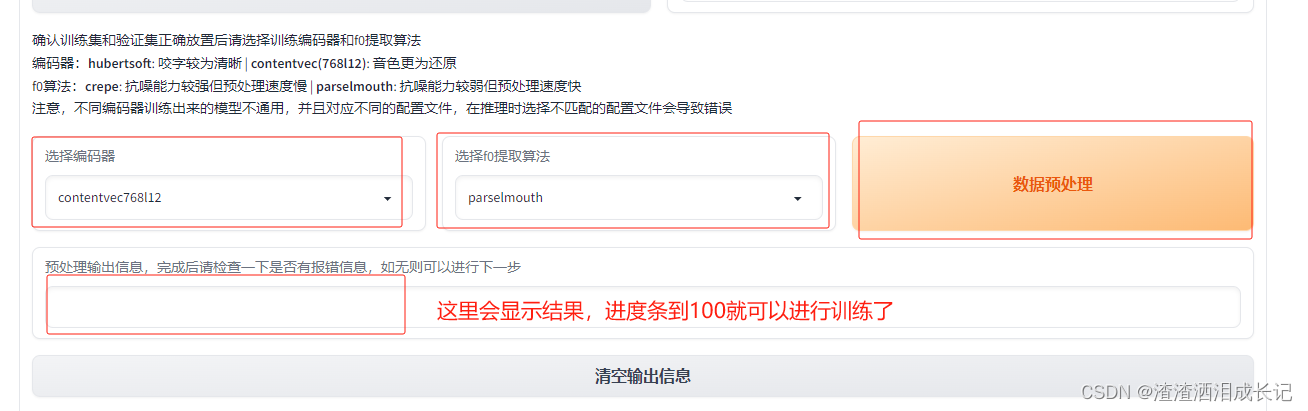
3.2 数据预处理
数据预处理,这里也很快,按下面的说明进行填写,填写哪些都有注释,不懂就默认,没影响,点击数据预处理就可以了。
3,3 训练前的参数设置
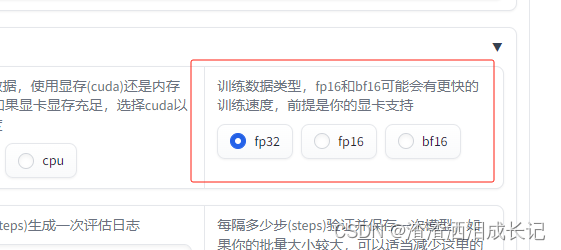
设置要训练的参数,其实都默认就行,但是配置低的要进行相应的更改,否则训练过程中会失败。然后点击写入配置文件就可以了,此时输出信息说写入配置完成就OK了。

3.4 开始训练
3.4.1 so-vits-svc模型训练
然后就开始训练了, 一般是先训so-vits-svc这个是比较重要的,第一次训练的化需要选择从头开始训练,如果训练过程中取消了,那么想要继续训练就选择继续上一次的训练进度,然后取消模型训练时一定要按照这个倍数取消**“每隔多少步(steps)验证并保存一次模型(2000步)”,**否则可能没保存上,
然后弹出cmd,一直在迭代步数中,代表训练中

观察loss值,无明显趋势觉得不需要训练就可以按取消了,ctrl+c就会取消训练

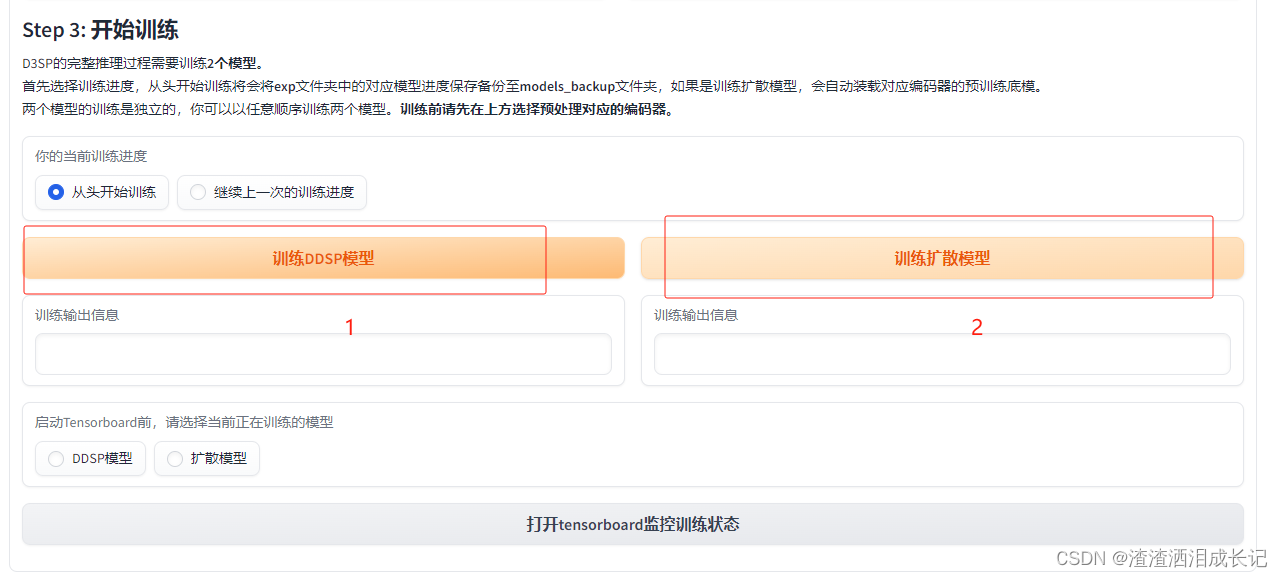
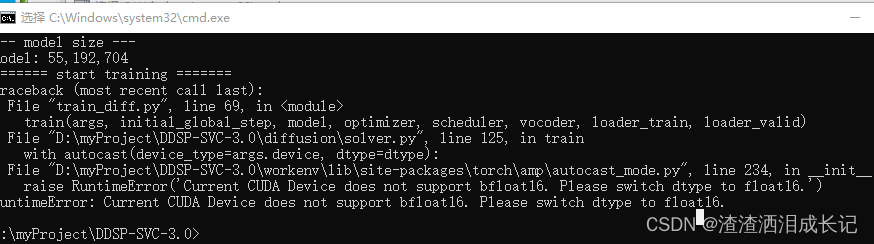
训练完了就可以训练扩散模型了,报如下错需要修改fp16需要改成fp32了。
可以看训练趋势图,启动Tensorboard,按下面这个操作就可以了,到时会告诉你地址。
so-vits-svc的需要在webui下面启动,在文件夹
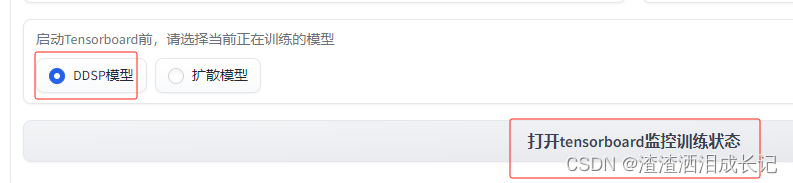
就会出现这样的界面

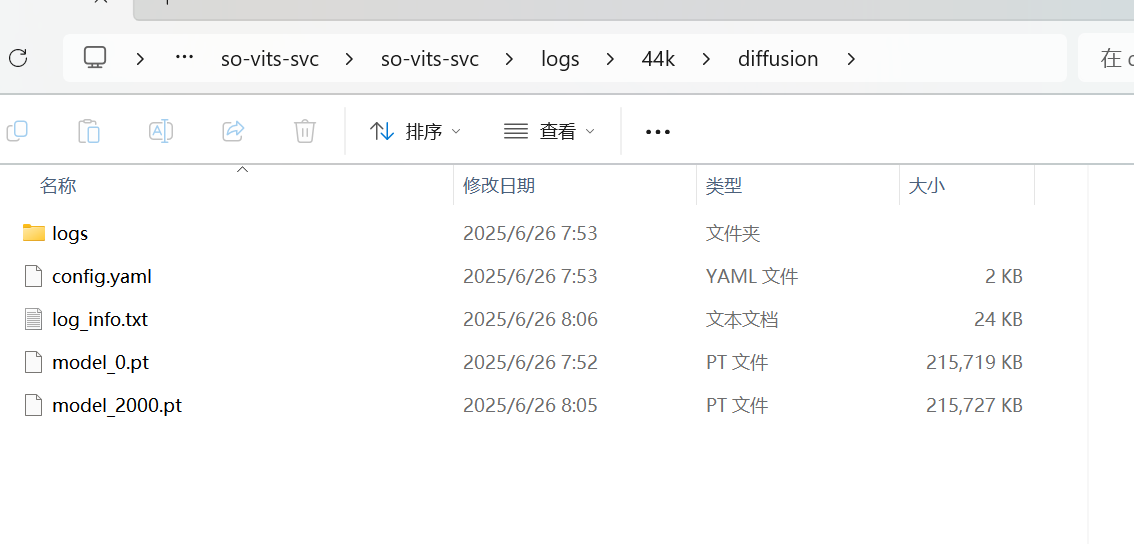
3.4.2 扩展模型训练
DDSP训练完毕,我们开始训练扩散模型。如下方式这样就可以了,cmd和上面的ddsp是一样的,感觉差不多了就取消训练。都训练完毕了就到推理环节了。

训练好的模型在这里会出现,此目录:E:\bdxz\新版整合包\so-vits-svc\so-vits-svc\logs\44k
so-vits-svc的在这个目录下,可以看到模型训练的步数
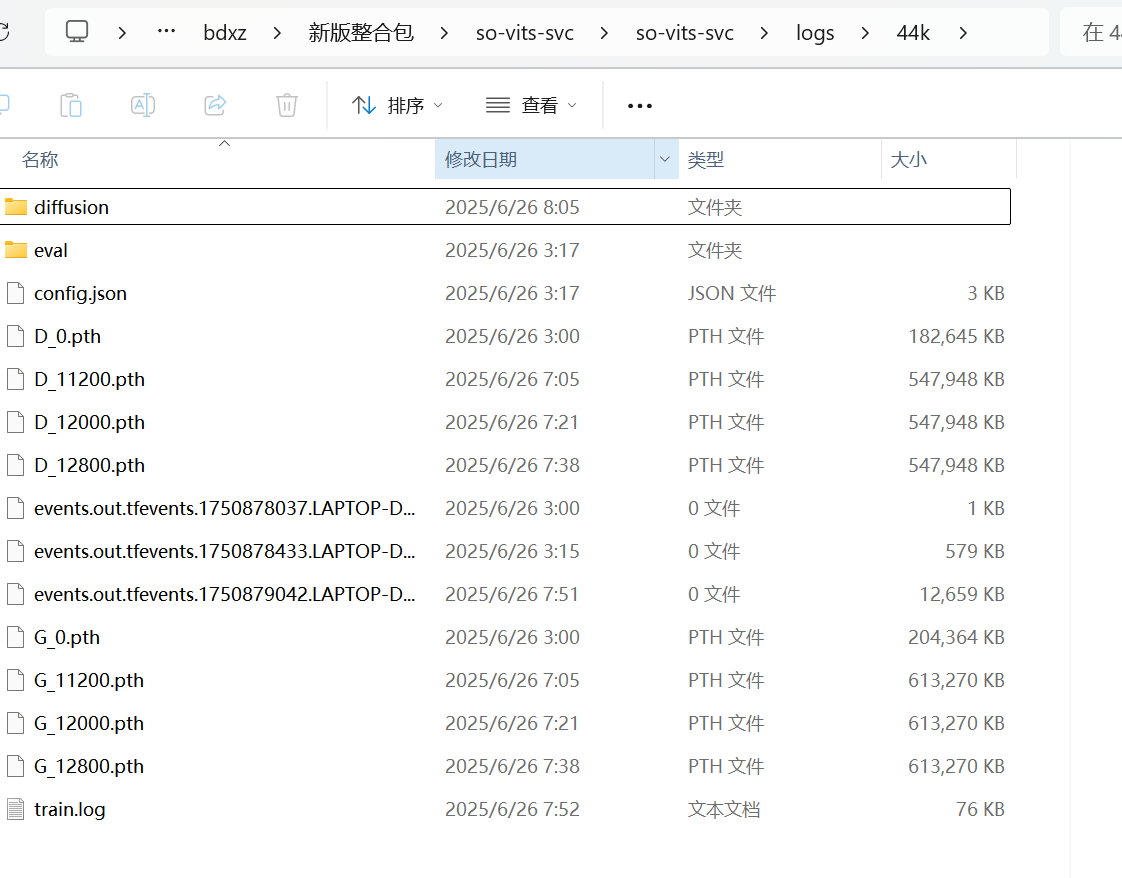
扩散训练的在这个地方
4.模型推理
兄弟们最后一步了,坚持住啊!
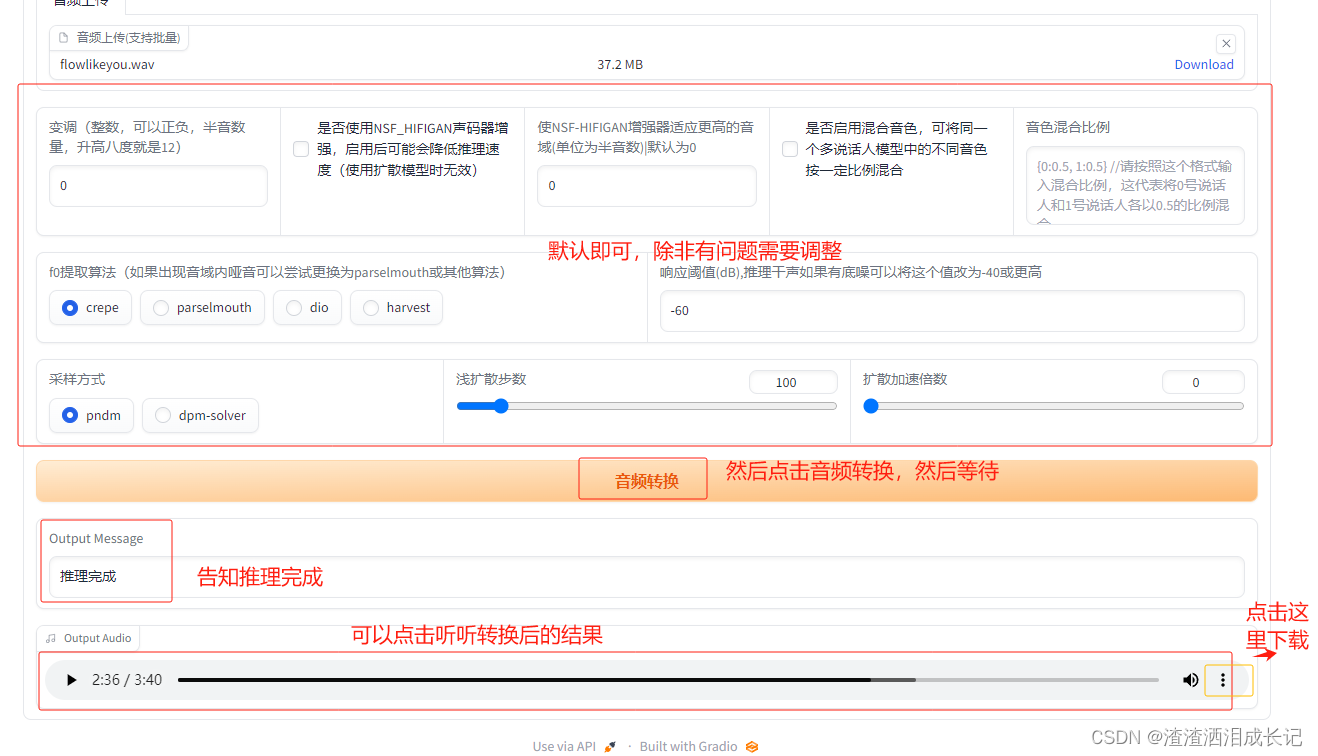
推理就选择我们自己训练的模型,选择音频,按下面的图片的步骤走,按顺序来就行。按他选选没有的就默认,选完要加载模型才能音频转换

4.1 音频转换
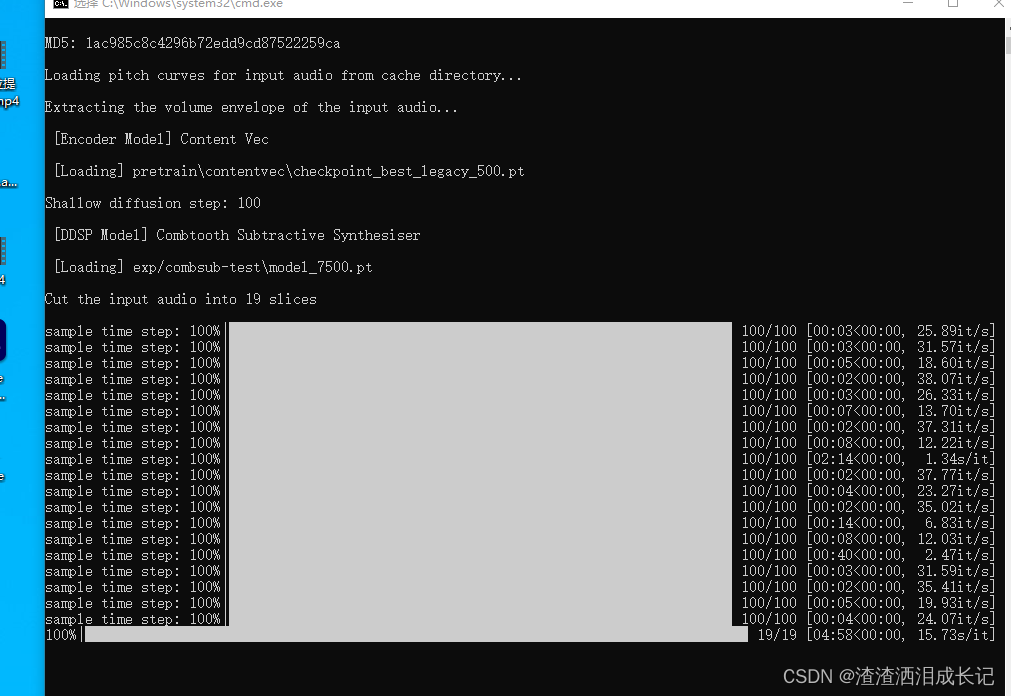
重点来了,开始声音替换 ,我第一次处理时间巨长,也看不到日志后来关掉重启,重试关掉重启几次,突然出现了日志,以及处理过程,然后很快就推理完成了,听了下,效果还行,我的数据集还行,40分钟差不多,训练步数7500步也不多,然后我的声音全部是说话,没有唱歌声音,最后出现的这个效果还行,有一点点感觉到ai的感觉,不知道是不是这个哥以及歌手唱腔的原因。
推理过程。
5.让AI唱歌
我的音频是《慢慢喜欢你》这首歌的干声,然后把我的声音替换上去,转换了以后《慢慢喜欢你》就是我的声音了,接下来就需要把伴奏和我处理后的声音合在一起,打开AU这个软件就可以了
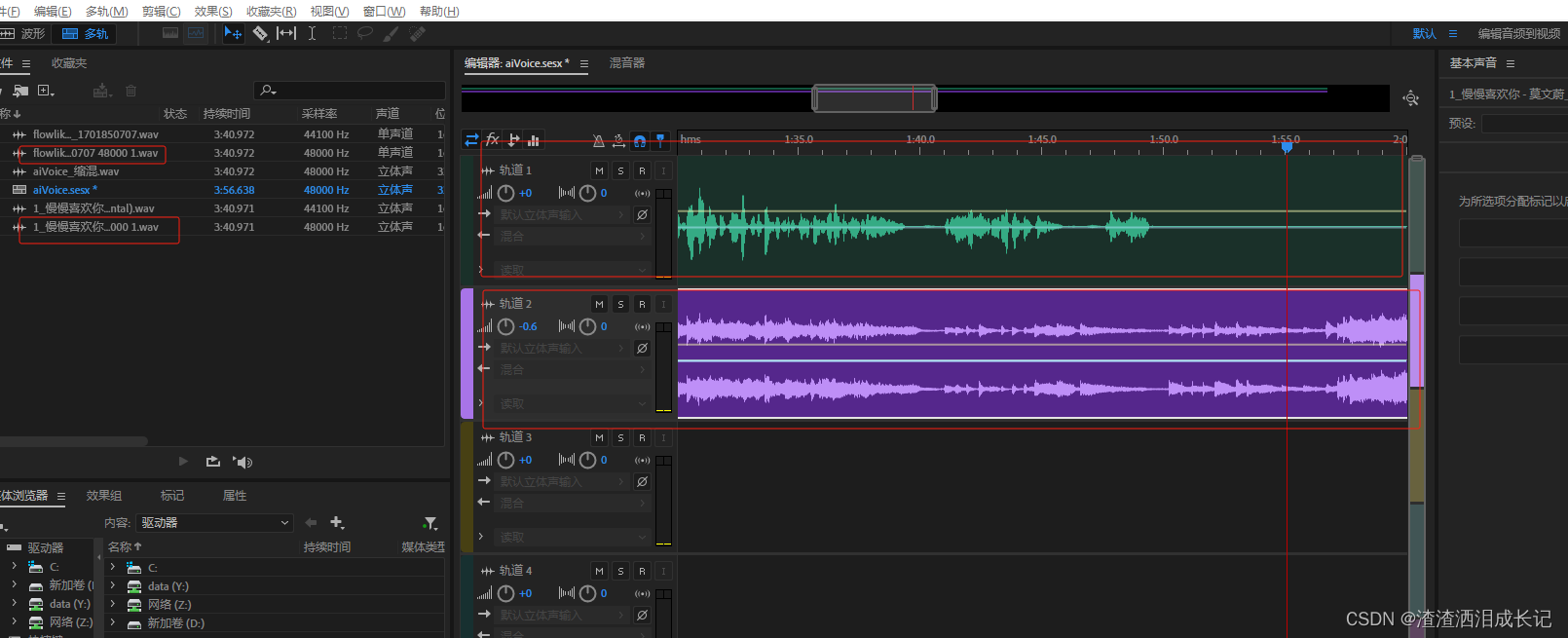
先把人声和干声打开,然后点多轨,保存后
然后将伴奏文件和处理好的音频拖入进来,干声放入第一轨道,伴奏放入第二轨道,对齐就好
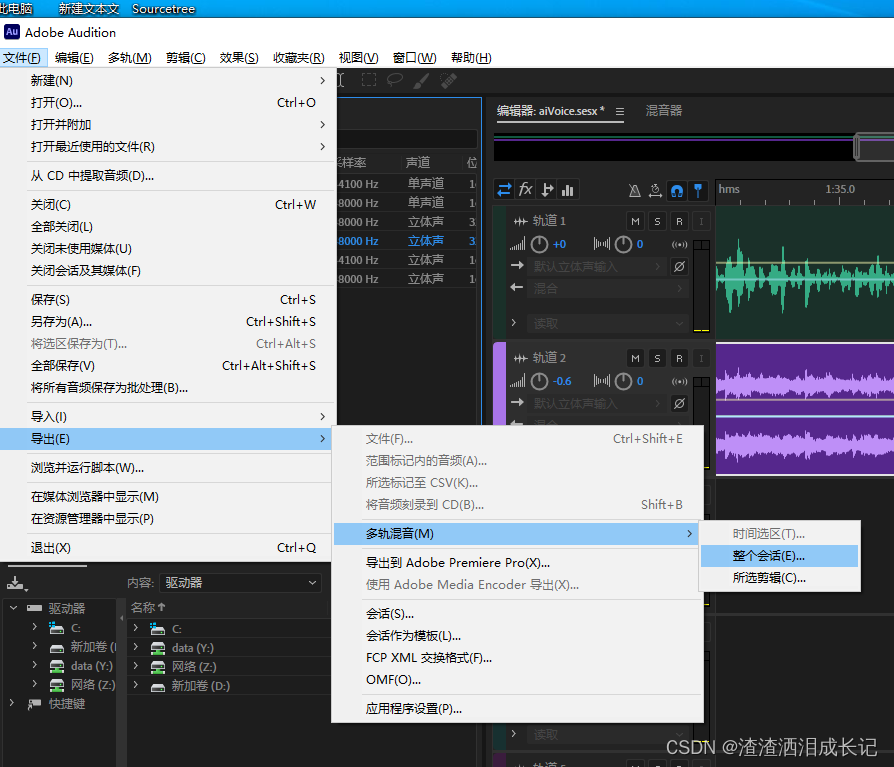
然后点击文件导出-多轨混音-整个会话就可以了。记得自己指定输出目录哦!
能给个赞吗嘿嘿!!!

本文引用
DDSP-SVC-3.0完全指南:一步步教你用AI声音开启音乐之旅 - overfit.cn
AI孙燕姿 ?AI东雪莲 !—— 本地部署DDSP-SVC一键包,智能音频切片,本地训练,模型推理,为你喜欢的角色训练AI语音模型小教程-优快云博客
感谢两位大神!!!!!!!!


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









