




 AffordanceNet是一种从RGB图像中检测物体及其功能的网络,包含对象检测和功能检测两个分支。网络利用RoIAlign、deconvolutional层和multi-task loss实现端到端训练。该方法特别关注高分辨率的功能掩模生成,适用于多类别的功能检测任务。
AffordanceNet是一种从RGB图像中检测物体及其功能的网络,包含对象检测和功能检测两个分支。网络利用RoIAlign、deconvolutional层和multi-task loss实现端到端训练。该方法特别关注高分辨率的功能掩模生成,适用于多类别的功能检测任务。
AffordanceNet - Object Affordance Detection
摘要:
AffordanceNet, 主要用于从 RGB 图片中同时检测多种 objects 以及其 affordance.
网络主要有两个分支:object 检测分支来对 object 进行定位和分类;affordance 检测分支来对 object 的每个像素归类到其最可能的 affordance label.
针对 affordance 任务的多分类问题,其主要特点:
- deconvolutional layers
- 鲁棒的 resizing 策略
- multi-task loss 函数
由于其网络结构类似于 Mask R-CNN,关注了下.
1. 问题阐述
目标:
同时学习图片中的 object 位置、类别及 affordance. 理想情况下,能检测到图片内所有相关的 objects,并将 object 的每一个像素划分到最可能的 affordance 标签.
object 位置:
相对于图片左上角的方框位置;
object 类别:
方框内 object 类别;
object affordance:
方框内每一个像素的 object 类别. 具有相同功能的 object 像素区域被作为一个 affordance.

2. AffordanceNet 网络结构
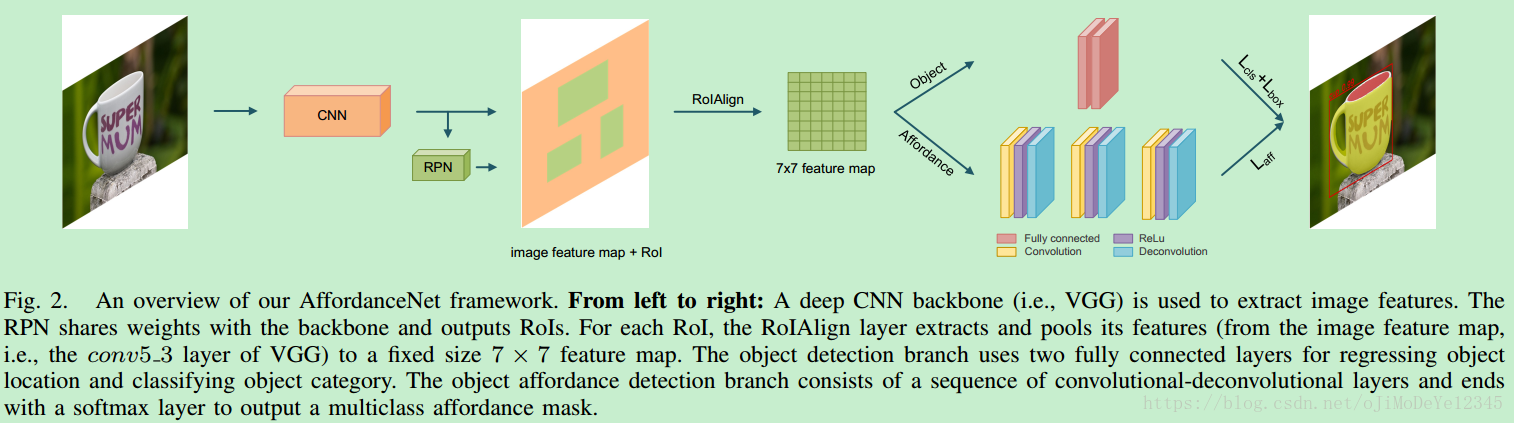
主要包括:
- CNN backbone - 如VGG,用于提取图片特征;
RPN - 与 CNN backbone 共享权重参数,并输出 RoIs;
RoI alignment(RoIAlign) 层- Mask R-CNN中的 RoI 对齐层,对于每个 RoI,RoIAlign 从图片 feature map(如,VGG 的 conv5_3 层的输出) 中提取和池化特征,得到固定尺寸 7×7 7 × 7 的 feature map.
- object 检测网络分支 - 采用两个全连接层来回归 object 位置,并分类;
- object affordance 检测分支 - 包括一序列的 conv-deconv 层,以得到平滑精确的 affordance map;其最后一层接 softmax 层以输出 multiclass affordance mask.
2.1 RoIAlign
基于 Mask R-CNN.
Faster R-CNN-RPN,RPN 与 backbone 网络共享权重,并输出在不同 size 的 bounding boxes(RoI/object proposal);
对于每个 RoI,采用 RoI Pool 层得到 image feature map 的小的固定尺度(7×7) 的feature map;
RoI Pool 层通过将每个 RoI 划分为规则网格,再采用 max-pooling 对每个网格单元的 feature map values 进行处理.
由于将 RoI 坐标从输入图像空间映射到图像 feature map 空间,以及将 RoI 划分规则单元格时,存在严格的舍入操作(harsh rounding operations),导致 RoI 和提取的特征间的不对齐.[ This quantization, however, causes misalignments between the RoI and the extracted features due to the harsh rounding operations when mapping the RoI coordinates from the input image space to the image feature map space and when dividing the RoI into grid cells.]
对此,Mask R-CNN 提出 RoIAlign 层来准确对齐 RoI 提取的特征.
与 RoI Pool 的不同在于, RoIAlign 不是采用 rounding 操作,而是采用双线性插值(bilinear interpolation),对于每个 RoI 单元格,采样其四个规则化的位置,计算输入特征的插入值,再采用 max 处理.
RoIAlign 对于像素级任务,如图像分割,十分重要.
2.2 高分辨率 Affordance Mask 的 Deconvolution
Mask R-CNN 和 FCIS 等实例分割方法,采用固定尺寸 mask (如, 14×14 14 × 14 , 28×28 28 × 28 ) 来表示 object 的 segmentation mask. 对每个 RoI 预测的 mask 的像素值都是二值,前景或背景,是可行的.
但是,对于 affordance 检测问题,小尺寸的 mask 可能效果不理想,因为每个 object 有多种 affordance 类别.
因此,这里采用一序列的 deconvolutional 层来处理高分辨率的 affordance mask.
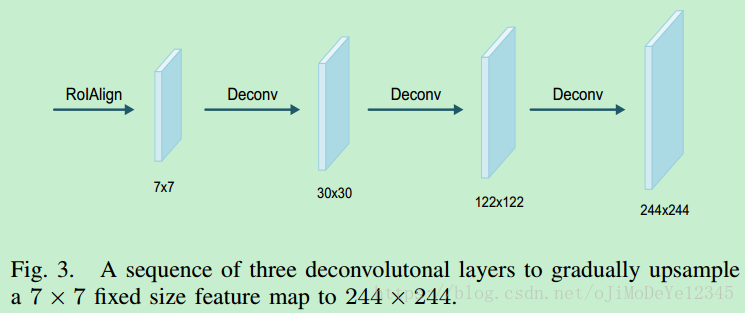
假设输入 feature map 尺寸为 Si S i ,deconv 层输出一个更大尺寸 So S o 的 map,其关系是:
So=s∗(Si−1)+Sf−2∗d S o = s ∗ ( S i − 1 ) + S f − 2 ∗ d
其中, Sf S f 是 fliter 尺寸, s s 和 分别是步长 stride 和 补零 padding 参数.
RoIAlign 层输出的 feature map 尺寸是 7×7 7 × 7 . 如图 Fig 3,采用三个 deconv 层可以上采样到更高的分辨率 244×244 244 × 244 .
- deconv1 - d=1,s=4,Sf=8 d = 1 , s = 4 , S f = 8
- deconv2 - d=1,s=4,Sf=8 d = 1 , s = 4 , S f = 8
- deconv3 - d=1,s=2,Sf=4 d = 1 , s = 2 , S f = 4
2.3 Robust Resizing Affordance Mask
类似于 Mask R-CNN 和 FCIS,AffordanceNet affordance 检测分支也输出固定尺寸 244×244 244 × 244 的 affordance mask.
前两者,训练时,是将每个 RoI 的原始 groundtruth mask resized 到预定义的 mask 尺寸,以计算 loss. resized 处理后输出的 mask 的值范围是 [0, 1],然后设定阈值(如 0.4)来判断像素是前景还是背景.
由于每个 object 存在多种 affordance 类别,单一阈值的方法对于 affordance 检测任务不适用.
对此,提出一种 multi-thresholding 的方法.
给定原始 groundtruth mask,记 P={ c0,c1,...,cn−1} P = { c 0 , c 1 , . . . , c n − 1 }
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 272
272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









