 加速梯度下降:特征缩放与学习率
加速梯度下降:特征缩放与学习率





 本文探讨了在梯度下降算法中如何通过特征缩放和均值归一化提升优化效率,解释了学习率在迭代过程中的关键作用。了解不同变量尺度对算法的影响,并掌握调整学习率的方法。
本文探讨了在梯度下降算法中如何通过特征缩放和均值归一化提升优化效率,解释了学习率在迭代过程中的关键作用。了解不同变量尺度对算法的影响,并掌握调整学习率的方法。
1. Feature Normalization(Feature Scaling)
在梯度下降算法中,当θ在一个较小的范围内时会快速下降,而在较大的范围内则下降的较为缓慢,所以当变量的取值范围非常不均匀时,算法会低效率地振动到最优解。
所以说,我们可以将每个变量固定在一个大致相同的范围内来加快梯度下降的速率。例如将变量控制在:
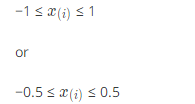
这不是一个绝对的区间,只要我们大致将变量控制在相似的取值范围内,就能够make sense。
特征缩放(feature scaling):
特征缩放涉及将输入值除以输入变量的范围(即最大值减去最小值),从而产生仅1的新范围。
均值归一化(mean normalization):

下面是一个例子:

2. Learnning Rate
简单来说,学习速率就是迭代函数中的α。

有一个结论:当学习速率α足够小时,J(θ)在每次迭代中一定会减小

















 4169
4169

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









