






文本操作
python
读写、创建文件
python 读写、创建 文件
python中对文件、文件夹(文件操作函数)的操作需要涉及到os模块和shutil模块。
得到当前工作目录,即当前Python脚本工作的目录路径: os.getcwd()
返回指定目录下的所有文件和目录名:os.listdir()
函数用来删除一个文件:os.remove()
删除多个目录:os.removedirs(r“c:\python”)
检验给出的路径是否是一个文件:os.path.isfile()
检验给出的路径是否是一个目录:os.path.isdir()
判断是否是绝对路径:os.path.isabs()
检验给出的路径是否真地存:os.path.exists()
返回一个路径的目录名和文件名:os.path.split() eg os.path.split(‘/home/swaroop/byte/code/poem.txt’) 结果:(‘/home/swaroop/byte/code’, ‘poem.txt’)
分离扩展名:os.path.splitext()
获取路径名:os.path.dirname()
获取文件名:os.path.basename()
运行shell命令: os.system()
读取和设置环境变量:os.getenv() 与os.putenv()
给出当前平台使用的行终止符:os.linesep Windows使用’\r\n’,Linux使用’\n’而Mac使用’\r’
指示你正在使用的平台:os.name 对于Windows,它是’nt’,而对于Linux/Unix用户,它是’posix’
重命名:os.rename(old, new)
创建多级目录:os.makedirs(r“c:\python\test”)
创建单个目录:os.mkdir(“test”)
获取文件属性:os.stat(file)
修改文件权限与时间戳:os.chmod(file)
终止当前进程:os.exit()
获取文件大小:os.path.getsize(filename)
文件操作:
os.mknod(“test.txt”) 创建空文件
fp = open(“test.txt”,w) 直接打开一个文件,如果文件不存在则创建文件
- 关于open 模式:
w 以写方式打开,
a 以追加模式打开 (从 EOF 开始, 必要时创建新文件)
r+ 以读写模式打开
w+ 以读写模式打开 (参见 w )
a+ 以读写模式打开 (参见 a )
rb 以二进制读模式打开
wb 以二进制写模式打开 (参见 w )
ab 以二进制追加模式打开 (参见 a )
rb+ 以二进制读写模式打开 (参见 r+ )
wb+ 以二进制读写模式打开 (参见 w+ )
ab+ 以二进制读写模式打开 (参见 a+ )
fp.read([size]) #size为读取的长度,以byte为单位
fp.readline([size]) #读一行,如果定义了size,有可能返回的只是一行的一部分
fp.readlines([size]) #把文件每一行作为一个list的一个成员,并返回这个list。其实它的内部是通过循环调用readline()来实现的。如果提供size参数,size是表示读取内容的总长,也就是说可能只读到文件的一部分。
fp.write(str) #把str写到文件中,write()并不会在str后加上一个换行符
fp.writelines(seq) #把seq的内容全部写到文件中(多行一次性写入)。这个函数也只是忠实地写入,不会在每行后面加上任何东西。
fp.close() #关闭文件。python会在一个文件不用后自动关闭文件,不过这一功能没有保证,最好还是养成自己关闭的习惯。 如果一个文件在关闭后还对其进行操作会产生ValueError
fp.flush() #把缓冲区的内容写入硬盘
fp.fileno() #返回一个长整型的”文件标签“
fp.isatty() #文件是否是一个终端设备文件(unix系统中的)
fp.tell() #返回文件操作标记的当前位置,以文件的开头为原点
fp.next() #返回下一行,并将文件操作标记位移到下一行。把一个file用于for … in file这样的语句时,就是调用next()函数来实现遍历的。
fp.seek(offset[,whence]) #将文件打操作标记移到offset的位置。这个offset一般是相对于文件的开头来计算的,一般为正数。但如果提供了whence参数就不一定了,whence可以为0表示从头开始计算,1表示以当前位置为原点计算。2表示以文件末尾为原点进行计算。需要注意,如果文件以a或a+的模式打开,每次进行写操作时,文件操作标记会自动返回到文件末尾。
fp.truncate([size]) #把文件裁成规定的大小,默认的是裁到当前文件操作标记的位置。如果size比文件的大小还要大,依据系统的不同可能是不改变文件,也可能是用0把文件补到相应的大小,也可能是以一些随机的内容加上去。
目录操作:
os.mkdir(“file”) 创建目录
复制文件:
shutil.copyfile(“oldfile”,“newfile”) oldfile和newfile都只能是文件
shutil.copy(“oldfile”,“newfile”) oldfile只能是文件夹,newfile可以是文件,也可以是目标目录
复制文件夹:
shutil.copytree(“olddir”,“newdir”) olddir和newdir都只能是目录,且newdir必须不存在
重命名文件(目录)
os.rename(“oldname”,“newname”) 文件或目录都是使用这条命令
移动文件(目录)
shutil.move(“oldpos”,“newpos”)
删除文件
os.remove(“file”)
删除目录
os.rmdir(“dir”)只能删除空目录
shutil.rmtree(“dir”) 空目录、有内容的目录都可以删
转换目录
os.chdir(“path”) 换路径
- Python读写文件
1.open
使用open打开文件后一定要记得调用文件对象的close()方法。比如可以用try/finally语句来确保最后能关闭文件。
file_object = open(‘thefile.txt’)
try:
all_the_text = file_object.read( )
finally:
file_object.close( )
注:不能把open语句放在try块里,因为当打开文件出现异常时,文件对象file_object无法执行close()方法。
2.读文件
读文本文件
input = open(‘data’, ‘r’)
#第二个参数默认为r
input = open(‘data’)
读二进制文件
input = open(‘data’, ‘rb’)
读取所有内容
file_object = open(‘thefile.txt’)
try:
all_the_text = file_object.read( )
finally:
file_object.close( )
读固定字节
file_object = open(‘abinfile’, ‘rb’)
try:
while True:
chunk = file_object.read(100)
if not chunk:
break
do_something_with(chunk)
finally:
file_object.close( )
读每行
list_of_all_the_lines = file_object.readlines( )
如果文件是文本文件,还可以直接遍历文件对象获取每行:
for line in file_object:
process line
3.写文件
写文本文件
output = open(‘data’, ‘w’)
写二进制文件
output = open(‘data’, ‘wb’)
追加写文件
output = open(‘data’, ‘w+’)
写数据
file_object = open(‘thefile.txt’, ‘w’)
file_object.write(all_the_text)
file_object.close( )
写入多行
file_object.writelines(list_of_text_strings)
注意,调用writelines写入多行在性能上会比使用write一次性写入要高。
在处理日志文件的时候,常常会遇到这样的情况:日志文件巨大,不可能一次性把整个文件读入到内存中进行处理,例如需要在一台物理内存为 2GB 的机器上处理一个 2GB 的日志文件,我们可能希望每次只处理其中 200MB 的内容。
在 Python 中,内置的 File 对象直接提供了一个 readlines(sizehint) 函数来完成这样的事情。以下面的代码为例:
file = open(‘test.log’, ‘r’)sizehint = 209715200 # 200Mposition = 0lines = file.readlines(sizehint)while not file.tell() - position < 0: position = file.tell() lines = file.readlines(sizehint)
每次调用 readlines(sizehint) 函数,会返回大约 200MB 的数据,而且所返回的必然都是完整的行数据,大多数情况下,返回的数据的字节数会稍微比 sizehint 指定的值大一点(除最后一次调用 readlines(sizehint) 函数的时候)。通常情况下,Python 会自动将用户指定的 sizehint 的值调整成内部缓存大小的整数倍。
file在python是一个特殊的类型,它用于在python程序中对外部的文件进行操作。在python中一切都是对象,file也不例外,file有file的方法和属性。下面先来看如何创建一个file对象:
file(name[, mode[, buffering]])
file()函数用于创建一个file对象,它有一个别名叫open(),可能更形象一些,它们是内置函数。来看看它的参数。它参数都是以字符串的形式传递的。name是文件的名字。
mode是打开的模式,可选的值为r w a U,分别代表读(默认) 写 添加支持各种换行符的模式。用w或a模式打开文件的话,如果文件不存在,那么就自动创建。此外,用w模式打开一个已经存在的文件时,原有文件的内容会被清空,因为一开始文件的操作的标记是在文件的开头的,这时候进行写操作,无疑会把原有的内容给抹掉。由于历史的原因,换行符在不同的系统中有不同模式,比如在 unix中是一个\n,而在windows中是‘\r\n’,用U模式打开文件,就是支持所有的换行模式,也就说‘\r’ ‘\n’ '\r\n’都可表示换行,会有一个tuple用来存贮这个文件中用到过的换行符。不过,虽说换行有多种模式,读到python中统一用\n代替。在模式字符的后面,还可以加上+ b t这两种标识,分别表示可以对文件同时进行读写操作和用二进制模式、文本模式(默认)打开文件。
buffering如果为0表示不进行缓冲;如果为1表示进行“行缓冲“;如果是一个大于1的数表示缓冲区的大小,应该是以字节为单位的。
file对象有自己的属性和方法。先来看看file的属性。
closed #标记文件是否已经关闭,由close()改写
encoding #文件编码
mode #打开模式
name #文件名
newlines #文件中用到的换行模式,是一个tuple
softspace #boolean型,一般为0,据说用于print
- file的读写方法:
F.read([size]) #size为读取的长度,以byte为单位
F.readline([size])
#读一行,如果定义了size,有可能返回的只是一行的一部分
F.readlines([size])
#把文件每一行作为一个list的一个成员,并返回这个list。其实它的内部是通过循环调用readline()来实现的。如果提供size参数,size是表示读取内容的总长,也就是说可能只读到文件的一部分。
F.write(str)
#把str写到文件中,write()并不会在str后加上一个换行符
F.writelines(seq)
#把seq的内容全部写到文件中。这个函数也只是忠实地写入,不会在每行后面加上任何东西。
file的其他方法:
F.close()
#关闭文件。python会在一个文件不用后自动关闭文件,不过这一功能没有保证,最好还是养成自己关闭的习惯。如果一个文件在关闭后还对其进行操作会产生ValueError
F.flush()
#把缓冲区的内容写入硬盘
F.fileno()
#返回一个长整型的”文件标签“
F.isatty()
#文件是否是一个终端设备文件(unix系统中的)
F.tell()
#返回文件操作标记的当前位置,以文件的开头为原点
F.next()
#返回下一行,并将文件操作标记位移到下一行。把一个file用于for … in file这样的语句时,就是调用next()函数来实现遍历的。
F.seek(offset[,whence])
#将文件打操作标记移到offset的位置。这个offset一般是相对于文件的开头来计算的,一般为正数。但如果提供了whence参数就不一定了,whence可以为0表示从头开始计算,1表示以当前位置为原点计算。2表示以文件末尾为原点进行计算。需要注意,如果文件以a或a+的模式打开,每次进行写操作时,文件操作标记会自动返回到文件末尾。
F.truncate([size])
#把文件裁成规定的大小,默认的是裁到当前文件操作标记的位置。如果size比文件的大小还要大,依据系统的不同可能是不改变文件,也可能是用0把文件补到相应的大小,也可能是以一些随机的内容加上去。
迭代器
迭代是访问集合元素的一种方式。迭代器是一个可以记住遍历的位置的对象。迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退
1.可迭代对象
以直接作用于for循环的数据类型有以下几种:
一类是集合数据类型,如list、tuple、dict、set、str等;
一类是generator,包括生成器和带yield的generator function。
这些可以直接作用于for循环的对象统称为可迭代对象:Iterable。
2.判断是否可以迭代
可以使用isinstance()判断一个对象是否是Iterable对象:
运行结果:
而生成器不但可以作用于for循环,还可以被next()函数不断调用并返回下一个值,直到最后抛出StopIteration错误表示无法继续返回下一个值了。
相关推荐:《Python视频教程》
3.迭代器
可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator。
运行结果:
4.iter()函数
生成器都是Iterator对象,但list、dict、str虽然是Iterable,却不是Iterator。
把list、dict、str等Iterable变成Iterator可以使用iter()函数:
运行结果:
总结
·凡是可作用于for循环的对象都是Iterable类型;
·凡是可作用于next()函数的对象都是Iterator类型
·集合数据类型如list、dict、str等是Iterable但不是Iterator,不过可以通过iter()函数获得一个Iterator对象。
·目的是在使用集合的时候,减少占用的内容。
迭代器(Iterator):迭代器可以看作是一个特殊的对象,每次调用该对象时会返回自身的下一个元素,从实现上来看,一个迭代器对象必须是定义了__iter__()方法和next()方法的对象。
1.Python的Iterator对象表示的是一个数据流,可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,所以Iterator的计算是惰性的,只有在需要返回下一个数据时它才会计算;
2.Iterator对象可以被next()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误;
3.所有的Iterable可迭代对象均可以通过内置函数iter()来转变为迭代器Iterator。老猿认为__iter__( )方法是让对象可以用for … in循环遍历时找到数据对象的位置,next( )方法是让对象可以通过next(实例名)访问下一个元素。除了通过内置函数next调用可以判断是否为迭代器外,还可以通过collection中的Iterator类型判断。如: isinstance(’’, Iterator)可以判断字符串类型是否迭代器。注意: list、dict、str虽然是Iterable,却不是Iterator。
4.迭代器优点:节约内存(循环过程中,数据不用一次读入,在处理文件对象时特别有用,因为文件也是迭代器对象)、不依赖索引取值、实现惰性计算(需要时再取值计算);
举例:用迭代器的方式访问文件
for line in open(“test.txt”):print(line)
这样每次读取一行就输出一行,而不是一次性将整个文件读入,节约内存。
5.迭代器使用上存在限制:只能向前一个个地访问数据,已访问数据无法再次访问、遍历访问一次后再访问无数据
举例:
l = [1,2,3,4]
i=iter(l) #从list列表生成迭代器i
list(i) #将迭代器内容转换成列表,输出[1,2,3,4]
list(i) #将迭代器内容再次转换成列表,输出[]
用for循环访问:
i=iter(l)
for k in i:print(k) #输出1、2、3、4
for k in i:print(k) #再次循环没有输出
如果需要解决这个问题,可以分别定义一个可迭代对象,每次访问前从可迭代对象重新生成和迭代器对象;
6.迭代器当所有的元素全部取出后再次调用next就会抛出一个StopIteration异常,这并不是错误的发生,而是告诉外部调用者迭代完成了
提取两端字符串中间内容
python 读取txt文件
Python的文本处理是经常碰到的一个问题,Python的txt文件读取中,有三类方法:read()、readline()、readlines(),这三种方法各有利弊,下面逐一介绍其使用方法和利弊。
- read():
read()是最简单的一种方法,一次性读取文件的所有内容放在一个大字符串中,即存在内存中
try:
file_context = file_object.read() //file_context是一个string,读取完后,就失去了对test.txt的文件引用
# file_context = open(file).read().splitlines()
// file_context是一个list,每行文本内容是list中的一个元素
finally:
file_object.close()
//除了以上方法,也可用with、contextlib都可以打开文件,且自动关闭文件,
//以防止打开的文件对象未关闭而占用内存
read()的利端:
方便、简单
一次性独读出文件放在一个大字符串中,速度最快
read()的弊端:
文件过大的时候,占用内存会过大
- readline():
readline()逐行读取文本,结果是一个list
line = f.readline()
while line:
print line
line = f.readline()
readline()的利端:
占用内存小,逐行读取
readline()的弊端:
由于是逐行读取,速度比较慢
- readlines():
readlines()一次性读取文本的所有内容,结果是一个list
for line in f.readlines():
print line
这种方法读取的文本内容,每行文本末尾都会带一个’\n’换行符 (可以使用L.rstrip(‘\n’)去掉换行符)
readlines()的利端:
一次性读取文本内容,速度比较快
readlines()的弊端:
随着文本的增大,占用内存会越来越多
最简单、最快速的逐行处理文本的方法:直接for循环文件对象
file_object = open('test.txt','rU')
try:
for line in file_object:
do_somthing_with(line)//line带"\n"
finally:
file_object.close()
如果对于读取到的一行内容要进行分割,也很容易,可以使用split进行分割
print s.split()
#输出结果为['hello!', 'my', 'word']
如果是格式化的定长的字符,也可以使用下标进行读取,比如s=‘helloworld’,s[5:]读到的就是’world’
#得到新库的表结构 pattern = re.compile('Table structure for table.*--',re.S) #贪婪匹配表达式为: .* 非贪婪匹配:.*? Table_list_n = pattern.findall(new_log) for line in Table_list_n: Table_Structure_new = re.sub(r"/*.*? */;|DROP.*;|/.*?","",line) file_object = open('tablenew.sql','w',encoding ="utf8") file_object.write(Table_Structure_new) file_object.close()
原文链接:https://blog.youkuaiyun.com/m0_37876745/article/details/83036318
数据类型
Python有五个标准的数据类型:
- Numbers(数字)
- String(字符串)
- List(列表)
- Tuple(元组)
- Dictionary(字典)
Python支持四种不同的数字类型:
- int(有符号整型)
- long(长整型,也可以代表八进制和十六进制)
- float(浮点型)
- complex(复数)
脚本语言
- 脚本语言的第一行 (只对 Linux/Unix 用户适用) 用来指定本脚本用什么解释器来执行。
有这句的,加上执行权限后,可以直接用 ./ 执行,不然会出错,因为找不到 python 解释器。
#!/usr/bin/python 是告诉操作系统执行这个脚本的时候,调用 /usr/bin 下的 python 解释器。
#!/usr/bin/env python 这种用法是为了防止操作系统用户没有将 python 装在默认的 /usr/bin 路径里。当系统看到这一行的时候,首先会到 env 设置里查找 python 的安装路径,再调用对应路径下的解释器程序完成操作。
#!/usr/bin/python 相当于写死了 python 路径。
#!/usr/bin/env python 会去环境设置寻找 python 目录,可以增强代码的可移植性,推荐这种写法。
分成两种情况:
(1)如果调用 python 脚本时,使用:
python script.py
#!/usr/bin/python 被忽略,等同于注释
(2)如果调用python脚本时,使用:
./script.py
#!/usr/bin/python 指定解释器的路径
PS:shell 脚本中在第一行也有类似的声明。
#!/usr/bin/bash 指定 bash 解释器
原文链接:https://blog.youkuaiyun.com/misayaaaaa/article/details/102309624
python re去除标点符号
去除标点符号方式多种多样,这里介绍两种自己常用的。
1、python自带punctuation包,可以消除所有中文标点符号。
import re,string
from zhon.hanzi import punctuation
text = " Hello, world! 这,是:我;第!一个程序\?()()<>《》 "
print(re.sub(r"[%s]+" %punctuation, "",text))
Hello world 这是我第一个程序
2、自己定义标点符号集,即可以消除中文标点符号也可以消除英文标点符号。
import re,string
text = " Hello, world! 这,是:我;第!一个程序\?()()<>《》 "
punc = '~`!#$%^&*()_+-=|\';":/.,?><~·!@#¥%……&*()——+-=“:’;、。,?》《{}'
print(re.sub(r"[%s]+" %punc, "",text))
Hello world 这是我第一个程序
常见报错
python常见报错:
| 报错 | 解释 | 原因 | 解决 |
|---|---|---|---|
| IndexError: list index out of range | 对Python中有序序列进行按索引取值的时候,出现这个异常 | 对于有序序列: 字符串 str 、列表 list 、元组 tuple进行按索引取值的时候,默认范围为 0 ~ len(有序序列)-1,计数从0开始,而不是从1开始,最后一位索引则为总长度减去1。当然也可以使用 负数表示从倒数第几个,计数从-1开始,则对于有序序列,总体范围为 -len(有序序列) ~ len(有序序列)-1,如果输入的取值结果不在这个范围内,则报这个错 | 检查索引是否在-len(有序序列) ~ len(有序序列)-1 范围内 |
| ‘set’ object is not subscriptable | 表示把不具有下标操作的集合对象用成了可取下标对象,使用了[i]操作 | 在迭代操作的时候,创建成了集合对象,出现了这个BUG(在创建对象时,将()或[]写成了{}) | 检查创建()或[]是否船舰错误 |
正则表达式
| 元字符 | 描述 |
|---|---|
| \ | 将下一个字符标记符、或一个向后引用、或一个八进制转义符。例如,“\n"匹配\n。”\n"匹配换行符。序列"\“匹配”“而”(“则匹配”("。即相当于多种编程语言中都有的"转义字符"的概念。 |
| ^ | 匹配输入字行首。如果设置了RegExp对象的Multiline属性,^也匹配"\n"或"\r"之后的位置。 |
| $ | 匹配输入行尾。如果设置了RegExp对象的Multiline属性,$也匹配"\n"或"\r"之前的位置。 |
| * | 匹配前面的子表达式任意次。例如,zo*能匹配"z",也能匹配"zo"以及"zoo"。*等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次(大于等于1次)。例如,“zo+“能匹配"zo"以及"zoo”,但不能匹配"z”。+等价于{1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,"do(es)?“可以匹配"do"或"does”。?等价于{0,1}。 |
| {n} | n是一个非负整数。匹配确定的n次。例如,"o{2}“不能匹配"Bob"中的"o”,但是能匹配"food"中的两个o。 |
| {n,} | n是一个非负整数。至少匹配n次。例如,"o{2,}“不能匹配"Bob"中的"o”,但能匹配"foooood"中的所有o。"o{1,}“等价于"o+”。"o{0,}“则等价于"o*”。 |
| {n,m} | m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。例如,"o{1,3}"将匹配"fooooood"中的前三个o为一组,后三个o为一组。"o{0,1}“等价于"o?”。请注意在逗号和两个数之间不能有空格。 |
| ? | 当该字符紧跟在任何一个其他限制符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少地匹配所搜索的字符串,而默认的贪婪模式则尽可能多地匹配所搜索的字符串。例如,对于字符串"oooo","o+“将尽可能多地匹配"o”,得到结果[“oooo”],而"o+?“将尽可能少地匹配"o”,得到结果 [‘o’, ‘o’, ‘o’, ‘o’] |
| .点 | 匹配除"\n"和"\r"之外的任何单个字符。要匹配包括"\n"和"\r"在内的任何字符,请使用像"[\s\S]"的模式。 |
| (pattern) | 匹配pattern并获取这一匹配。所获取的匹配可以从产生的Matches集合得到,在VBScript中使用SubMatches集合,在JScript中则使用$0…$9属性。要匹配圆括号字符,请使用"(“或”)"。 |
| (?:pattern) | 非获取匹配,匹配pattern但不获取匹配结果,不进行存储供以后使用。这在使用或字符"(|)"来组合一个模式的各个部分时很有用。例如"industr(?:y|ies)"就是一个比"industry|industries"更简略的表达式。 |
| (?=pattern) | 非获取匹配,正向肯定预查,在任何匹配pattern的字符串开始处匹配查找字符串,该匹配不需要获取供以后使用。例如,“Windows(?=95|98|NT|2000)“能匹配"Windows2000"中的"Windows”,但不能匹配"Windows3.1"中的"Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
| (?!pattern) | 非获取匹配,正向否定预查,在任何不匹配pattern的字符串开始处匹配查找字符串,该匹配不需要获取供以后使用。例如"Windows(?!95|98|NT|2000)“能匹配"Windows3.1"中的"Windows”,但不能匹配"Windows2000"中的"Windows"。 |
| (?<=pattern) | 非获取匹配,反向肯定预查,与正向肯定预查类似,只是方向相反。例如,“(?<=95|98|NT|2000)Windows"能匹配"2000Windows"中的"Windows”,但不能匹配"3.1Windows"中的"Windows"。*python的正则表达式没有完全按照正则表达式规范实现,所以一些高级特性建议使用其他语言如java、scala等 |
| (?<!patte_n) | 非获取匹配,反向否定预查,与正向否定预查类似,只是方向相反。例如"(?<!95|98|NT|2000)Windows"能匹配"3.1Windows"中的"Windows",但不能匹配"2000Windows"中的"Windows"。*python的正则表达式没有完全按照正则表达式规范实现,所以一些高级特性建议使用其他语言如java、scala等 |
| x|y | 匹配x或y。例如,“z|food"能匹配"z"或"food”(此处请谨慎)。“[z|f]ood"则匹配"zood"或"food”。 |
| [xyz] | 字符集合。匹配所包含的任意一个字符。例如,"[abc]“可以匹配"plain"中的"a”。 |
| [^xyz] | 负值字符集合。匹配未包含的任意字符。例如,"[^abc]"可以匹配"plain"中的"plin"任一字符。 |
| [a-z] | 字符范围。匹配指定范围内的任意字符。例如,"[a-z]"可以匹配"a"到"z"范围内的任意小写字母字符。注意:只有连字符在字符组内部时,并且出现在两个字符之间时,才能表示字符的范围; 如果出字符组的开头,则只能表示连字符本身. |
| [^a-z] | 负值字符范围。匹配任何不在指定范围内的任意字符。例如,"[^a-z]"可以匹配任何不在"a"到"z"范围内的任意字符。 |
| \b | 匹配一个单词的边界,也就是指单词和空格间的位置(即正则表达式的"匹配"有两种概念,一种是匹配字符,一种是匹配位置,这里的\b就是匹配位置的)。例如,“er\b"可以匹配"never"中的"er”,但不能匹配"verb"中的"er";“\b1_“可以匹配"1_23"中的"1_”,但不能匹配"21_3"中的"1_”。 |
| \B | 匹配非单词边界。“er\B"能匹配"verb"中的"er”,但不能匹配"never"中的"er"。 |
| \cx | 匹配由x指明的控制字符。例如,\cM匹配一个Control-M或回车符。x的值必须为A-Z或a-z之一。否则,将c视为一个原义的"c"字符。 |
| \d | 匹配一个数字字符。等价于[0-9]。grep 要加上-P,perl正则支持 |
| \D | 匹配一个非数字字符。等价于[^0-9]。grep要加上-P,perl正则支持 |
| \f | 匹配一个换页符。等价于\x0c和\cL。 |
| \n | 匹配一个换行符。等价于\x0a和\cJ。 |
| \r | 匹配一个回车符。等价于\x0d和\cM。 |
| \s | 匹配任何不可见字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。 |
| \S | 匹配任何可见字符。等价于[^ \f\n\r\t\v]。 |
| \t | 匹配一个制表符。等价于\x09和\cI。 |
| \v | 匹配一个垂直制表符。等价于\x0b和\cK。 |
| \w | 匹配包括下划线的任何单词字符。类似但不等价于"[A-Za-z0-9_]",这里的"单词"字符使用Unicode字符集。 |
| \W | 匹配任何非单词字符。等价于"[^A-Za-z0-9_]"。 |
| \xn | 匹配n,其中n为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,“\x41"匹配"A”。“\x041"则等价于”\x04&1"。正则表达式中可以使用ASCII编码。 |
| *num* | 匹配num,其中num是一个正整数。对所获取的匹配的引用。例如,"(.)\1"匹配两个连续的相同字符。 |
| *n* | 标识一个八进制转义值或一个向后引用。如果*n之前至少n个获取的子表达式,则n为向后引用。否则,如果n为八进制数字(0-7),则n*为一个八进制转义值。 |
| *nm* | 标识一个八进制转义值或一个向后引用。如果*nm之前至少有nm个获得子表达式,则nm为向后引用。如果*nm之前至少有n个获取,则n为一个后跟文字m的向后引用。如果前面的条件都不满足,若n和m均为八进制数字(0-7),则*nm将匹配八进制转义值nm*。 |
| *nml* | 如果n为八进制数字(0-7),且m和l均为八进制数字(0-7),则匹配八进制转义值nml。 |
| \un | 匹配n,其中n是一个用四个十六进制数字表示的Unicode字符。例如,\u00A9匹配版权符号(©)。 |
| \p{P} | 小写 p 是 property 的意思,表示 Unicode 属性,用于 Unicode 正表达式的前缀。中括号内的"P"表示Unicode 字符集七个字符属性之一:标点字符。其他六个属性:L:字母;M:标记符号(一般不会单独出现);Z:分隔符(比如空格、换行等);S:符号(比如数学符号、货币符号等);N:数字(比如阿拉伯数字、罗马数字等);C:其他字符。*注:此语法部分语言不支持,例:javascript。 |
| <> | 匹配词(word)的开始(<)和结束(>)。例如正则表达式<the>能够匹配字符串"for the wise"中的"the",但是不能匹配字符串"otherwise"中的"the"。注意:这个元字符不是所有的软件都支持的。 |
| ( ) | 将( 和 ) 之间的表达式定义为"组"(group),并且将匹配这个表达式的字符保存到一个临时区域(一个正则表达式中最多可以保存9个),它们可以用 \1 到\9 的符号来引用。 |
| | | 将两个匹配条件进行逻辑"或"(or)运算。例如正则表达式(him|her) 匹配"it belongs to him"和"it belongs to her",但是不能匹配"it belongs to them."。注意:这个元字符不是所有的软件都支持的。 |
console.log方法
console.log方法用于在控制台输出信息。它可以接受一个或多个参数,将它们连接起来输出。
console.log('Hello World')
// Hello World
console.log('a', 'b', 'c')
// a b c
console.log方法会自动在每次输出的结尾,添加换行符。
console.log(2);
console.log(3);
// 1
// 2
// 3
如果第一个参数是格式字符串(使用了格式占位符),console.log方法将依次用后面的参数替换占位符,然后再进行输出。
console.log(' %s + %s = %s', 1, 1, 2)
// 1 + 1 = 2
上面代码中,console.log方法的第一个参数有三个占位符(%s),第二、三、四个参数会在显示时,依次替换掉这个三个占位符。
console.log方法支持以下占位符,不同类型的数据必须使用对应的占位符。
%s 字符串
%d 整数
%i 整数
%f 浮点数
%o 对象的链接
%c CSS 格式字符串
var number = 11 * 9;
var color = 'red';
console.log('%d %s balloons', number, color);
// 99 red balloons
上面代码中,第二个参数是数值,对应的占位符是%d,第三个参数是字符串,对应的占位符是%s。
使用%c占位符时,对应的参数必须是 CSS 代码,用来对输出内容进行 CSS 渲染。
console.log(
'%cThis text is styled!',
'color: red; background: yellow; font-size: 24px;'
)
上面代码运行后,输出的内容将显示为黄底红字。
console.log方法的两种参数格式,可以结合在一起使用。
console.log(' %s + %s ', 1, 1, '= 2')
// 1 + 1 = 2
如果参数是一个对象,console.log会显示该对象的值。
console.log({foo: 'bar'})
// Object {foo: "bar"}
console.log(Date)
// function Date() { [native code] }
上面代码输出Date对象的值,结果为一个构造函数
原文链接:https://blog.youkuaiyun.com/qq_29007709/article/details/86238095
MYSQL
MySQL修改表结构
1、添加与删除字段
(1)、添加
Alter table 表名 add【column】字段名 列类型 列属性 【first|after 字段名】
ALTER TABLE 表名称
ADD 列名1 数据类型 [约束] [COMMENT 注释,
ADD 列名2 数据类型 [约束] [COMMENT 注释];
(2)、删除
Alter table 表名 drop【column】字段名;
ALTER TABLE 表名称
DROP 列名1,
DROP 列名2;
2.修改字段名
语句:alter table 表名 change 原字段名 新字段名 列类型 列属性;
说明:就算是仅修改字段名,那么字段的原始类型,原属性也要重新书写,不然就变为删除。
语句:alter table 表名 modify 字段名 列类型 列属性;
语句:alter table 表名 rename to 新表名;
ALTER TABLE 表名 CHANGE 列名 新列名 数据类型 [约束] [COMMENT 注释]
5.修改表选项
语句:alter table 表名 表选项;
说明:虽然MYSQL提供了修改表选项的命令,但是如果一个表中已经有数据,那么就不要执行修改字符集的命令。
6.修改列属性
列属性包含not null、default、unique、primary key、auto_increment
当一个表创建以后,对于列属性的操作,我们可以使用alter table 表名 modify 来操作。在操作的时候如果书写了列属性就
是添加列属性,如果没有书写就是删除列属性。
特殊的列属性:Primary key和unique。
增加列属性
普通属性的增加:
语句:alter table 表名 modify 字段名 列类型 列属性;
ALTER TABLE 表名 MODIFY 列名 数据类型 [约束] [COMMENT 注释]
说明:
A、auto_increment在添加时需要注意字段必须是整数,而且是unique或者primary key。
B、Unique与default不能一起连用。
主键属性的添加:
语句:alter table 表名 add primary key(字段名);
修改表结构的步骤:
# 步骤 1: 创建一个新表
# 步骤 2: 修改清空表. 这应该比较快,
# Step 3: 创建触发器来捕获原始表的改变 <–(锁定元数据)
# Step 4: 复制数据.
# Step 5: 重命名表: <–(锁定元数据
# Step 6: 更新外键 如果是子表.
# Step 7: 删除旧表.
列表约束、主键相关
PRIMARY KEY与identity(1,1)的含义
PRIMARY KEY 约束 表中经常有一个列或列的组合,其值能唯一地标识表中的每一行。这样的一列或多列称为表的主键,通过它可强制表的实体完整性。当创建或更改表时可通过定义 PRIMARY KEY 约束来创建主键。
一个表只能有一个 PRIMARY KEY 约束,而且 PRIMARY KEY 约束中的列不能接受空值。由于 PRIMARY KEY 约束确保唯一数据,所以经常用来定义标识列。
当为表指定 PRIMARY KEY 约束时,Microsoft® SQL Server? 2000 通过为主键列创建唯一索引强制数据的唯一性。当在查询中使用主键时,该索引还可用来对数据进行快速访问。
假如 PRIMARY KEY 约束定义在不止一列上,则一列中的值可以重复,但 PRIMARY KEY 约束定义中的所有列的组合的值必须唯一。
如下图所示,titleauthor 表中的 au_id 和 title_id 列组成该表的组合 PRIMARY KEY 约束,以确保 au_id 和 title_id 的组合唯一。
当进行联接时,PRIMARY KEY 约束将一个表与另一个表相联。例如,若要确定作者与书名的对应关系,可以使用 authors 表、titles 表和 titleauthor 表的三向联接。因为 titleauthor 包含 au_id 和 title_id 两列,对 titles 表的访问可由 titleauthor 和 titles 之间的关联进行。
请参见 创建和修改 PRIMARY KEY 约束
Transact-SQL 参考
IDENTITY(函数) 只用在带有 INTO table 子句的 SELECT 语句中,以将标识列插入到新表中。 尽管类似,但是 IDENTITY 函数不是与 CREATE TABLE 和 ALTER TABLE 一起使用的 IDENTITY 属性。
语法
IDENTITY ( data_type [ , seed , increment ] ) AS column_name
参数
data_type
标识列的数据类型。标识列的有效数据类型可以是任何整数数据类型分类的数据类型(bit 数据类型除外),也可以是 decimal 数据类型。
seed
要指派给表中第一行的值。给每一个后续行指派下一个标识值,该值等于上一个 IDENTITY 值加上 increment 值。假如既没有指定 seed,也没有指定 increment,那么它们都默认为 1。
increment
用来添加到 seed 值以获得表中连续行的增量。
column_name 将插入到新表中的列的名称。
返回类型 返回与 data_type 相同的类型。
注释 因为该函数在表中创建一个列,所以必须用下列方式中的一种在选择列表中指定该列的名称:
–(1)
SELECT IDENTITY(int, 1,1) AS ID_Num
INTO NewTable
FROM OldTable
–(2)
SELECT ID_Num = IDENTITY(int, 1, 1)
INTO NewTable
FROM OldTable
示例 下面的示例将来自 pubs 数据库中 employee 表的所有行都插入到名为 employees 的新表。使用 IDENTITY 函数在 employees 表中从 100 而不是 1 开始编标识号。
USE pubs
IF EXISTS(SELECT TABLE_NAME FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_NAME = ‘employees’)
DROP TABLE employees
GO
EXEC sp_dboption ‘pubs’, ‘select into/bulkcopy’, ‘true’
SELECT emp_id AS emp_num,
fname AS first,
minit AS middle,
lname AS last,
IDENTITY(smallint, 100, 1) AS job_num,
job_lvl AS job_level,
pub_id,
hire_date
INTO employees
FROM employee
GO
USE pubs
EXEC sp_dboption ‘pubs’, ‘select into/bulkcopy’, ‘false’
请参见
CREATE TABLE
@@IDENTITY
IDENTITY(属性)
SELECT @local_variable
使用系统函数
[code=SQL] 创建和维护数据库
PRIMARY KEY 约束
表中经常有一个列或列的组合,其值能唯一地标识表中的每一行。这样的一列或多列称为表的主键,通过它可强制表的实体完整性。当创建或更改表时可通过定义 PRIMARY KEY 约束来创建主键。
一个表只能有一个 PRIMARY KEY 约束,而且 PRIMARY KEY 约束中的列不能接受空值。由于 PRIMARY KEY 约束确保唯一数据,所以经常用来定义标识列。
当为表指定 PRIMARY KEY 约束时,Microsoft® SQL Server? 2000 通过为主键列创建唯一索引强制数据的唯一性。当在查询中使用主键时,该索引还可用来对数据进行快速访问。
假如 PRIMARY KEY 约束定义在不止一列上,则一列中的值可以重复,但 PRIMARY KEY 约束定义中的所有列的组合的值必须唯一。
如下图所示,titleauthor 表中的 au_id 和 title_id 列组成该表的组合 PRIMARY KEY 约束,以确保 au_id 和 title_id 的组合唯一。
当进行联接时,PRIMARY KEY 约束将一个表与另一个表相联。例如,若要确定作者与书名的对应关系,可以使用 authors 表、titles 表和 titleauthor 表的三向联接。因为 titleauthor 包含 au_id 和 title_id 两列,对 titles 表的访问可由 titleauthor 和 titles 之间的关联进行。
请参见
创建和修改 PRIMARY KEY 约束
Transact-SQL 参考
IDENTITY(函数)
只用在带有 INTO table 子句的 SELECT 语句中,以将标识列插入到新表中。
尽管类似,但是 IDENTITY 函数不是与 CREATE TABLE 和 ALTER TABLE 一起使用的 IDENTITY 属性。
语法
IDENTITY ( data_type [ , seed , increment ] ) AS column_name
参数
data_type
标识列的数据类型。标识列的有效数据类型可以是任何整数数据类型分类的数据类型(bit 数据类型除外),也可以是 decimal 数据类型。
seed
要指派给表中第一行的值。给每一个后续行指派下一个标识值,该值等于上一个 IDENTITY 值加上 increment 值。假如既没有指定 seed,也没有指定 increment,那么它们都默认为 1。
increment
用来添加到 seed 值以获得表中连续行的增量。
column_name
将插入到新表中的列的名称。
返回类型
返回与 data_type 相同的类型。
注释
因为该函数在表中创建一个列,所以必须用下列方式中的一种在选择列表中指定该列的名称:
–(1)
SELECT IDENTITY(int, 1,1) AS ID_Num
INTO NewTable
FROM OldTable
–(2)
SELECT ID_Num = IDENTITY(int, 1, 1)
INTO NewTable
FROM OldTable
示例
下面的示例将来自 pubs 数据库中 employee 表的所有行都插入到名为 employees 的新表。使用 IDENTITY 函数在 employees 表中从 100 而不是 1 开始编标识号。
USE pubs
IF EXISTS(SELECT TABLE_NAME FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_NAME = ‘employees’)
DROP TABLE employees
GO
EXEC sp_dboption ‘pubs’, ‘select into/bulkcopy’, ‘true’
SELECT emp_id AS emp_num,
fname AS first,
minit AS middle,
lname AS last,
IDENTITY(smallint, 100, 1) AS job_num,
job_lvl AS job_level,
pub_id,
hire_date
INTO employees
FROM employee
GO
USE pubs
EXEC sp_dboption ‘pubs’, ‘select into/bulkcopy’, ‘false’
请参见
CREATE TABLE
@@IDENTITY
IDENTITY(属性)
SELECT @local_variable
使用系统函数
mysql中unsigned的用法理解
-
unsigned 是MYSQL自定义的类型,非标准SQL。用途1是起到约束数值的作用,2是可以增加数值范围(相当于把负数那部分加到正数上)。不过少用,不方便移植。
-
unsigned 为“无符号”的意思
unsigned 既为非负数,用此类型可以增加数据长度!
例如如果 tinyint最大是127,那 tinyint unsigned 最大 就可以到 127 * 2
unsigned 属性只针对整型,而binary属性只用于char 和varchar。
UNSIGNED 可用来约束数据的范围,例如有些年龄这种值一般能是负数,那么就可以设置一个 UNSIGNED ,这样可以不允许负数插入
看起来这是一个不错的属性选项,特别是对于主键是自增长的类型,因为一般来说,用户都希望主键是非负数。然而在实际使用中,UNSIGNED可能会带来一些负面的影响:计算可能会出现非预期结果:
select a-b from table1;
但预期结果是负数时,则实际结果可能是个很大的值,甚至sql执行报错
当(a-b)在where子句后时也会出现相同的情况
AUTO_INCREMENT
是随着你数据库里面数据项的增加而自动增加值的一个属性,一般在像MYSQL这种数据库里,主键一般都是用ID号,比如学生的学号,公民的身份证号等,这种ID号是唯一的,是可以唯一标识数据库里面的一项数据的,而这种ID号并不需要自己动手去一个个输入,直接通过设置AUTO_INCREMENT就可以从小到大自动生成了。
ENGINE=InnoDB 表示将数据库的引擎设置为InnoDB,从MySQL 5.6开始默认使用该引擎。
DEFAULT CHARSET=utf8 表示设置数据库的默认字符集为utf8
AUTO_INCREMENT=1 表示自动增长的起始值为1
AUTO_INCREMENT会在新记录插入表中时生成一个唯一的数字。希望在每次插入新记录时,自动地创建主键字段的值,可以在表中创建一个 auto-increment 字段
扩展资料:
如果希望在每次插入新记录时,自动地创建主键字段的值。可以在表中创建一个 auto-increment 字段。MySQL 使用 AUTO_INCREMENT 关键字来执行 auto-increment 任务。默认地AUTO_INCREMENT 的开始值是 1,每条新记录递增 1。
主键又称主关键字,主关键字(primary key)是表中的一个或多个字段,它的值用于唯一地标识表中的某一条记录。在两个表的关系中,主关键字用来在一个表中引用来自于另一个表中的特定记录。主关键字是一种唯一关键字,表定义的一部分。一个表的主键可以由多个关键字共同组成,并且主关键字的列不能包含空值。主关键字是可选的,并且可在 CREATE TABLE 或 ALTER TABLE 语句中定义。
SQL 将两个结构相同的表合并到成一个表
select *
into 新表名
from (select * from T1 union all select * from T2)
这个语句可以实现将合并的数据追加到一个新表中。
不合并重复数据
select * from T1 union all select * from T2
合并重复数据
select * from T1 union select * from T2
两个表,表1 表2
如果要将 表1的数据并入表2用以下语句即可
insert into 表2(字段1,字段2) select 字段1,字段2 from b1
注意,必须把字段名全部写清楚,而且不允许把自动编号进去写进去,要合并自动编号字段必须重写一个算法一条一条记录地加进去
1 insert into b1 select * from b2
2 select * into newtable from (select * from b1 union all select * from b2)
对已存在的表进行插入列
alter table 表名 add column 列名 数据类型 default 默认值 ;
修改插入标题
–A.添加新列
ALTER TABLE 表名 ADD 列名 VARCHAR(20)
–B.修改列名
EXEC sp_rename ‘dbo.表名.列名’, ‘新列名’, ‘COLUMN’
知识点衍生
- 1.删除列
ALTER TABLE 表名 DROP COLUMN column_b - 2.更改列的数据类型
ALTER TABLE 表名 ALTER COLUMN 列 DECIMAL (5, 2) - 3.添加包含约束的列(唯一约束)
ALTER TABLE 表 ADD 列 VARCHAR(20) NULL
CONSTRAINT 约束名 UNIQUE - 4.添加一个未验证的check约束
ALTER TABLE 表 WITH NOCHECK
ADD CONSTRAINT 约束名 CHECK (列 > 1) - 5.在现有列中添加一个DEFAULT约束
ALTER TABLE 表
ADD CONSTRAINT 约束名
DEFAULT 50 FOR 列名 - 6.删除约束
ALTER TABLE 表 DROP CONSTRAINT 约束名 - 7.更改排序规则
ALTER TABLE 表
ALTER COLUMN 列 varchar(50) COLLATE Latin1_General_BIN - 8.修改表名
EXEC sp_rename ‘dbo.表名’, ‘新表名’ - 9.重命名索引
EXEC sp_rename N’dbo.表名.索引名’, N’新索引名’, N’INDEX’
1.1Python 文件读写查找、替换的相关操作,
参考:https://blog.youkuaiyun.com/liangrui1988/article/details/49539137
1.2Python 插入内容到指定文件的位置
if pos != -1:
content = content[:pos] + content_add + content[pos:]
参考:https://blog.youkuaiyun.com/jusulysunbeamy/article/details/51290129
1.3Python 的正则表达
Findall
注意:返回的是匹配的字符串,若没有匹配,返回[],而不是什么也不返回
1.4 Python replace的应用
参考:http://www.runoob.com/python/python-reg-expressions.html
1.5 Python 两个list 组合成字典
keys = [‘a’, ‘b’, ‘c’]
values = [1, 2, 3]
dictionary = dict(zip(keys, values))
print(dictionary)
1.6 根据字典的对应关系,对文本进行替换
a_dict = {‘apple’:‘1’,‘tree’:‘2’,‘123456’:‘3’}
input_file = open(r’d:\test_body.txt’,“r”).read();
for key,value in a_dict.items():
input_file=input_file.replace(key,value);
1.7 seek的用法:
seek()方法: 用它设置当前文件读/写指针的偏移。
seek()方法的语法如下:fileObject.seek(offset[, whence])。offset参数指明偏移量,第二个参数指出第一个参数偏移基准是哪里:
offset的取值可为:0,1,2; 0 表示移动到一个绝对位置 (从文件开始算起),1 表示移到一个相对位置 (从当前位置算起), 2 表示对于文件尾的一个相对位置。”
参考:https://blog.youkuaiyun.com/liuchunming033/article/details/39376147
1.8 整体代码:
import re
import os
class myMethod(object):
def __init__(self, file1):
self.file1 = file1
self._count = None
def count_main(self, main_str):
'''
搜索文件中指定字符串的个数
:param file_name: 文件名称 type=str
:param main_str: 要搜索的目标字段 type=str
:return:
'''
fo = open(self.file1, "r+")
# 打开文件,r+:打开一个文件用于读写。文件指针将会放在文件的开头。
# 参考:http://www.runoob.com/python3/python3-inputoutput.html
li_list = []
fo.seek(0, 0)
for s in fo.readlines():
li = re.findall(main_str, s)
if li != []:
li_list.append(li)
else:
continue
fo.close()
return len(li_list)
def add_str(self, file2, main_str):
'''
:param file_name: 原始的文件名 type = str
:param file_new_name: 新生成的文件名 type = str
:param main_str: 搜索的字符串
:return:
'''
self._count = self.count_main(main_str)
fo = open(self.file1, "r+")
fo.seek(0, 0)
content = fo.read()
for i in range(1, self._count // 3 + 1):
add_list = [' id="apname' + str(i) + '" class="ap"', ' class="outer"', ' class="wifi"']
for j in range(3):
pos = content.find("<g>")
if pos != -1:
content = content[:pos + 2] + add_list[j] + content[pos + 2:]
fo_new = open(file2, "w")
# w 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被
# 删除。如果该文件不存在,创建新文件。
fo_new.write(content)
fo_new.close()
fo.close()
return file2
def excelColToList1(excel_file):
# data = xlrd.open_workbook(path + '/' + file_r)
data = xlrd.open_workbook(excel_file)
sheet1 = data.sheets()[0]
nrows = sheet1.nrows
ncols = sheet1.ncols
apnames = []
apInPictureNums= []
for i in range(2, nrows):
apname = sheet1.cell(i, 9).value
apname = apname.strip()
apnames.append(apname)
apInPictureNum = sheet1.cell(i, 15).value
apInPictureNum = apInPictureNum.strip()
apInPictureNums.append(apInPictureNum)
new_str = [apnames[i] + '" name="' + apInPictureNums[i] for i in range(len(apnames))]
dictionary = dict(zip(apInPictureNums, new_str))
return dictionary
def replace_str(self, file2, old_str, new_str, new_list_strs):
'''
:param file2: 需要替换某些字符串的文本 type=“str”
:param old_str: 需要被替换的字符串 type = "str" 比如apname
:param new_str: 将old_str 替换成new_str tupe='str' 比如 h2-1f-ap
:param new_list_strs: 在AI打点时 的顺序
:return:
'''
fo = open(file2, "r")
mykeys = []
myvalues = []
for i in range(0, self._count // 3):
mykeys.append(old_str+str(i+1))
myvalues.append(new_str+str(new_list_strs[i]))
mydict = dict(zip(mykeys, myvalues))
content = fo.read()
for key, value in mydict.items():
content = content.replace(key, value)
fo_new = open(self.file1, "w")
fo_new.write(content)
fo_new.close()
fo.close()
os.remove(file2)
return self.file1
file1 = "testCopy.txt"
file2 = "testCopy2.txt"
main_str = "<g>"
mytest = myMethod(file1)
file = mytest.add_str(file2, main_str)
old_str = "apname"
new_str = "h2-1f-ap"
new_list_strs = [1,2,3]
mytest.replace_str(file, old_str, new_str, new_list_strs)
MySQL远程授权navicat
>grant all on *.* to root@'%'; #给所有用户授权
>FLUSH PRIVILEGES; #刷新
LINUX、SHELL
sed
Linux sed 命令是利用脚本来处理文本文件。
sed 可依照脚本的指令来处理、编辑文本文件。
Sed 主要用来自动编辑一个或多个文件、简化对文件的反复操作、编写转换程序等。
语法
sed [-hnV][-e<script>][-f<script文件>][文本文件]参数说明:
- -e
例一:
sed ‘s/A/B/g‘ xxx 中g的含义 表示全局替换
sed的替换命令格式:s/A/B/g 或者 s#A#B#g 或者 s_A_B_g#。
替换 s/A/B/ 就是A替换成B
例如:sed ‘s//\t/g’ xxx:将所有空格替换为制表符\t,g表示全局替换,有多少次替换多少次。
s 是替代命令. s/表达式/replacement/
空白用t替代。如果你的unix中 \t表示tab键,则用tab键替代。
g(GLOBAL)的作用从下例可以看出
** g – 全部替代**
** 无g – 只替代每行第一个**
例二:
sed 's/.*\(\..*$\)/\1/'
s///表示将12两个斜杠中的内容替换为23两个斜杠间的内容
.表示任意字符。
*表示重复任意次。
所以.*表示任意长度的字符串。
取(的分组的功能,单单写(不加饭斜杠\,那么sed就到字符串中匹配(了,同。
\.刚好相反,由于.表示任意字符,如果要表示.本身,就要加反斜杠\
$表示字符串结尾。
\1表示前面中匹配到的内容。
例三:
#sed ':a;N;$!ba;s/\n/ /g' :a;N;$!ba;是把内容合并为一行,因为sed默认是逐行处理的, s/\n/ /g 是把换行符替换为空格
#sed s/[[:space:]]//g 把空格替换为空,即删除空格
xxxx|sed ':a;N;$!ba;s/\n/ /g'|sed s/[[:space:]]//g
难点解读:
sed ‘:a;N;$!ba;s/\n/ /g’ 这将在一个循环里读取整个文件,然后将换行符替换成一个空格。
当然:也可以直接删除换行符,只需要把替换的目标内容由空格替换为空(注意:不是空格) //之间没有空格
sed ‘:a;N;$!ba;s/\n//g’
语法说明:
通过 :a创建一个标记
通过N追加当前行和下一行到模式区域
如果处于最后一行前,跳转到之前的标记处。 ! b a ( !ba (!ba(! 意思是不在最后一行做这操作 (最后一行就被当成最后的一行)).
最后置换操作把模式区域(就是整个文件)的每一个换行符换成一个空格。
示例追加:
$ echo -e "1\n2" | sed ':a;N;$!ba;s/\n/ /g'
1 2
s#\(.*\),\(.*\)#\1\2#
- tr ‘a-z’ 'A-Z’相当于uc,字符由小写转换成大写
awk
AWK 是一种处理文本文件的语言
awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。简单来说awk就是把文件逐行的读入,默认以空格为分隔符将每行切片,切开的部分再进行各种分析处理。awk是行处理器,相比较屏幕处理的优点,在处理庞大文件时不会出现内存溢出或是处理缓慢的问题,通常用来格式化文本信息
awk处理过程 : 依次对每一行进行处理,然后输出
awk的用法
awk 参数 ’ BEGIN{} // {action1;action2} ’ END{} 文件名
参数:
- -F 指定分隔符
- -f 调用脚本
- -v 定义变量
Begin{} 初始化代码块,在对每一行进行处理之前,初始化代码,主要是引用全局变量,设置FS分隔符
// 匹配代码块,可以是字符串或正则表达式
{} 命令代码块,包含一条或多条命令,多条命令用 ; 隔开
END{} 结尾代码块,在对每一行进行处理之后再执行的代码块,主要是进行最终计算或输出结尾摘要信息
例:awk ‘BEGIN{X=0}/root/{X+=1}END{print “I find”,X,“root lines”}’ /etc/passwd 统计 /etc/passwd 文件中包含root行的总数
awk中字符的含义
- $0 表示整个当前行
- $1 每行第一个字段
- NF 字段数量变量
- NR 每行的记录号,多文件记录递增
- FNR 与NR类似,不过多文件记录不递增,每个文件都从1开始
- \t 制表符
- \n 换行符
- FS BEGIN时定义分隔符
- RS 输入的记录分隔符, 默认为换行符(即文本是按一行一行输入)
- ~ 包含
- !~ 不包含
- == 等于,必须全部相等,精确比较
- != 不等于,精确比较
- && 逻辑与
- || 逻辑或
- + 匹配时表示1个或1个以上
- /0-9+/ 两个或两个以上数字
- /0-9*/ 一个或一个以上数字
- OFS 输出字段分隔符, 默认也是空格,可以改为其他的
- ORS 输出的记录分隔符,默认为换行符,即处理结果也是一行一行输出到屏幕
- -F [:#/] 定义了三个分隔符
print 打印
- print 是 awk打印指定内容的主要命令,也可以用 printf
- awk ‘{print}’ /etc/passwd == awk ‘{print $0}’ /etc/passwd
- awk ‘{print " "}’ /etc/passwd 不输出passwd的内容,而是输出相同个数的空行,进一步解释了awk是一行一行处理文本
- awk ‘{print “a”}’ /etc/passwd 输出相同个数的a行,一行只有一个a字母
- awk -F: ‘{print Extra close brace or missing open brace1}’ /etc/passwd
- awk -F: ‘{print 2}’ 输入字段1,2,中间不分隔
- awk -F: ‘{print 3,$6}’ OFS=“\t” /etc/passwd 输出字段1,3,6, 以制表符作为分隔符
- awk -F: ‘{print 2}’ /etc/passwd 输入字段1,2,分行输出
- awk -F: ‘{print 2}’ /etc/passwd 输入字段1,2,中间以**分隔
- awk -F: ‘{print "name:"3}’ /etc/passwd 自定义格式输出字段1,2
- awk -F: ‘{print NF}’ /etc/passwd 显示每行有多少字段
- awk -F: ‘NF>2{print }’ /etc/passwd 将每行字段数大于2的打印出来
- awk -F: ‘NR==5{print}’ /etc/passwd 打印出/etc/passwd文件中的第5行
- awk -F: ‘NR5|NR6{print}’ /etc/passwd 打印出/etc/passwd文件中的第5行和第6行
- awk -F: ‘NR!=1{print}’ /etc/passwd 不显示第一行
- awk -F: ‘{print > “1.txt”}’ /etc/passwd 输出到文件中
- awk -F: ‘{print}’ /etc/passwd > 2.txt 使用重定向输出到文件中
字符匹配
- awk -F: ‘/root/{print }’ /etc/passwd 打印出文件中含有root的行
- awk -F: '/'打印出文件中含有变量A的行
- awk -F: ‘!/root/{print}’ /etc/passwd 打印出文件中不含有root的行
- awk -F: ‘/root|tom/{print}’ /etc/passwd 打印出文件中含有root或者tom的行
- awk -F: ‘/mail/,mysql/{print}’ test 打印出文件中含有 mail*mysql 的行,*代表有0个或任意多个字符
- awk -F: ‘/^2[7]*/{print}’ test 打印出文件中以27开头的行,如27,277,27gff 等等
- awk -F: ‘$1~/root/{print}’ /etc/passwd 打印出文件中第一个字段是root的行
- awk -F: ‘($1==“root”){print}’ /etc/passwd 打印出文件中第一个字段是root的行,与上面的等效
- awk -F: ‘$1!~/root/{print}’ /etc/passwd 打印出文件中第一个字段不是root的行
- awk -F: ‘($1!=“root”){print}’ /etc/passwd 打印出文件中第一个字段不是root的行,与上面的等效
- awk -F: ‘$1~/root|ftp/{print}’ /etc/passwd 打印出文件中第一个字段是root或ftp的行
- awk -F: ‘(1==“ftp”){print}’ /etc/passwd 打印出文件中第一个字段是root或ftp的行,与上面的等效
- awk -F: ‘$1!~/root|ftp/{print}’ /etc/passwd 打印出文件中第一个字段不是root或不是ftp的行
- awk -F: ‘(1!=“ftp”){print}’ /etc/passwd 打印出文件中第一个字段不是root或不是ftp的行,与上面等效
- awk -F: ‘{if($1~/mail/) {print $1} else {print $2}}’ /etc/passwd 如果第一个字段是mail,则打印第一个字段,否则打印第2个字段
格式化输出
awk ‘{printf “%-5s %.2d”,2}’ test
- printf 表示格式输出
- %格式化输出分隔符
- -8表示长度为8个字符
- s表示字符串类型,d表示小数
举例
1、显示 /etc/passwd 中含有 root 的行
awk ‘/root/’ /etc/passwd
2、以 : 为分隔,显示/etc/passwd中每行的第1和第7个字段
awk -F “:” ‘{print 1,7}’ /etc/passwd
3、以 : 为分隔,显示/etc/passwd中含有 root 的行的第1和第7个字段
awk -F “:” '/root/{print
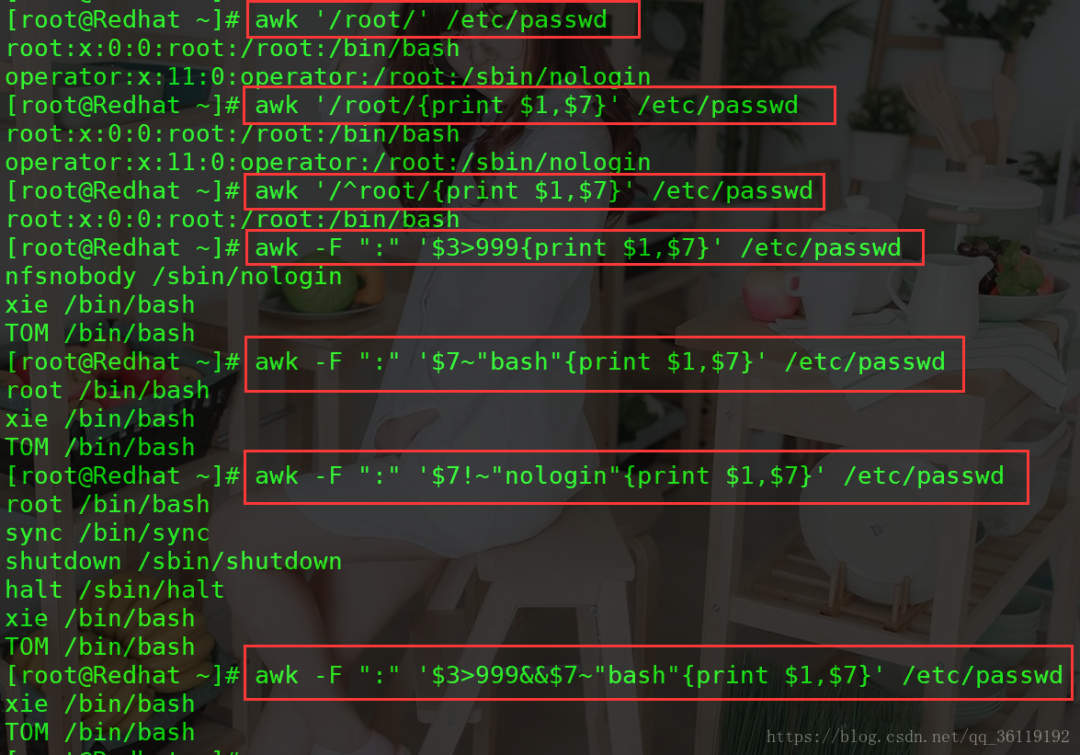
4、以 : 为分隔,显示/etc/passwd中以 root 开头行的第1和第7个字段
awk -F “:” '/^root/{print
5、以 : 为分隔,显示/etc/passwd中第3个字段大于999的行的第1和第7个字段
awk -F “:” ’
6、以 : 为分隔,显示/etc/passwd中第7个字段包含bash的行的第1和第7个字段
awk -F “:” ’
7、以 : 为分隔,显示/etc/passwd中第7个字段不包含bash的行的第1和第7个字段
awk -F “:” ’
8、以 : 为分隔,显示$3>999并且第7个字段包含bash的行的第1和第7个字段
awk -F “:” ‘1,7}’ /etc/passwd
9、以 : 为分隔,显示$3>999或第7个字段包含bash的行的第1和第7个字段
awk -F “:” ‘1,7}’ /etc/passwd
语法
awk [选项参数] 'script' var=value file(s) 或 awk [选项参数] -f scriptfile var=value file(s)选项参数说明:
- -F fs or --field-separator fs
指定输入文件折分隔符,fs是一个字符串或者是一个正则表达式,如-F:。- -v var=value or --asign var=value
赋值一个用户定义变量。- -f scripfile or --file scriptfile
从脚本文件中读取awk命令。- -mf nnn and -mr nnn
对nnn值设置内在限制,-mf选项限制分配给nnn的最大块数目;-mr选项限制记录的最大数目。这两个功能是Bell实验室版awk的扩展功能,在标准awk中不适用。- -W compact or --compat, -W traditional or --traditional
在兼容模式下运行awk。所以gawk的行为和标准的awk完全一样,所有的awk扩展都被忽略。- -W copyleft or --copyleft, -W copyright or --copyright
打印简短的版权信息。- -W help or --help, -W usage or --usage
打印全部awk选项和每个选项的简短说明。- -W lint or --lint
打印不能向传统unix平台移植的结构的警告。- -W lint-old or --lint-old
打印关于不能向传统unix平台移植的结构的警告。- -W posix
打开兼容模式。但有以下限制,不识别:/x、函数关键字、func、换码序列以及当fs是一个空格时,将新行作为一个域分隔符;操作符和=不能代替和=;fflush无效。- -W re-interval or --re-inerval
允许间隔正则表达式的使用,参考(grep中的Posix字符类),如括号表达式[[:alpha:]]。- -W source program-text or --source program-text
使用program-text作为源代码,可与-f命令混用。- -W version or --version
打印bug报告信息的版本。
基本用法
log.txt文本内容如下:
2 this is a test 3 Do you like awk This's a test 10 There are orange,apple,mongo用法一:
awk '{[pattern] action}' {filenames} # 行匹配语句 awk '' 只能用单引号实例:
# 每行按空格或TAB分割,输出文本中的1、4项 $ awk '{print $1,$4}' log.txt --------------------------------------------- 2 a 3 like This's 10 orange,apple,mongo # 格式化输出 $ awk '{printf "%-8s %-10s\n",$1,$4}' log.txt --------------------------------------------- 2 a 3 like This's 10 orange,apple,mongo用法二:
awk -F #-F相当于内置变量FS, 指定分割字符实例:
# 使用","分割 $ awk -F, '{print $1,$2}' log.txt --------------------------------------------- 2 this is a test 3 Do you like awk This's a test 10 There are orange apple # 或者使用内建变量 $ awk 'BEGIN{FS=","} {print $1,$2}' log.txt --------------------------------------------- 2 this is a test 3 Do you like awk This's a test 10 There are orange apple # 使用多个分隔符.先使用空格分割,然后对分割结果再使用","分割 $ awk -F '[ ,]' '{print $1,$2,$5}' log.txt --------------------------------------------- 2 this test 3 Are awk This's a 10 There apple用法三:
awk -v # 设置变量实例:
$ awk -va=1 '{print $1,$1+a}' log.txt --------------------------------------------- 2 3 3 4 This's 1 10 11 $ awk -va=1 -vb=s '{print $1,$1+a,$1b}' log.txt --------------------------------------------- 2 3 2s 3 4 3s This's 1 This'ss 10 11 10s用法四:
awk -f {awk脚本} {文件名}实例:
$ awk -f cal.awk log.txt
运算符
运算符 描述 = += -= *= /= %= ^= **= 赋值 ?: C条件表达式 || 逻辑或 && 逻辑与 ~ 和 !~ 匹配正则表达式和不匹配正则表达式 < <= > >= != == 关系运算符 空格 连接 + - 加,减 * / % 乘,除与求余 + - ! 一元加,减和逻辑非 ^ *** 求幂 ++ – 增加或减少,作为前缀或后缀 $ 字段引用 in 数组成员 过滤第一列大于2的行
$ awk '$1>2' log.txt #命令 #输出 3 Do you like awk This's a test 10 There are orange,apple,mongo过滤第一列等于2的行
$ awk '$1==2 {print $1,$3}' log.txt #命令 #输出 2 is过滤第一列大于2并且第二列等于’Are’的行
$ awk '$1>2 && $2=="Are" {print $1,$2,$3}' log.txt #命令 #输出 3 Are you
内建变量
变量 描述 $n 当前记录的第n个字段,字段间由FS分隔 $0 完整的输入记录 ARGC 命令行参数的数目 ARGIND 命令行中当前文件的位置(从0开始算) ARGV 包含命令行参数的数组 CONVFMT 数字转换格式(默认值为%.6g)ENVIRON环境变量关联数组 ERRNO 最后一个系统错误的描述 FIELDWIDTHS 字段宽度列表(用空格键分隔) FILENAME 当前文件名 FNR 各文件分别计数的行号 FS 字段分隔符(默认是任何空格) IGNORECASE 如果为真,则进行忽略大小写的匹配 NF 一条记录的字段的数目 NR 已经读出的记录数,就是行号,从1开始 OFMT 数字的输出格式(默认值是%.6g) OFS 输出字段分隔符,默认值与输入字段分隔符一致。 ORS 输出记录分隔符(默认值是一个换行符) RLENGTH 由match函数所匹配的字符串的长度 RS 记录分隔符(默认是一个换行符) RSTART 由match函数所匹配的字符串的第一个位置 SUBSEP 数组下标分隔符(默认值是/034) $ awk 'BEGIN{printf "%4s %4s %4s %4s %4s %4s %4s %4s %4s\n","FILENAME","ARGC","FNR","FS","NF","NR","OFS","ORS","RS";printf "---------------------------------------------\n"} {printf "%4s %4s %4s %4s %4s %4s %4s %4s %4s\n",FILENAME,ARGC,FNR,FS,NF,NR,OFS,ORS,RS}' log.txt FILENAME ARGC FNR FS NF NR OFS ORS RS --------------------------------------------- log.txt 2 1 5 1 log.txt 2 2 5 2 log.txt 2 3 3 3 log.txt 2 4 4 4 $ awk -F\' 'BEGIN{printf "%4s %4s %4s %4s %4s %4s %4s %4s %4s\n","FILENAME","ARGC","FNR","FS","NF","NR","OFS","ORS","RS";printf "---------------------------------------------\n"} {printf "%4s %4s %4s %4s %4s %4s %4s %4s %4s\n",FILENAME,ARGC,FNR,FS,NF,NR,OFS,ORS,RS}' log.txt FILENAME ARGC FNR FS NF NR OFS ORS RS --------------------------------------------- log.txt 2 1 ' 1 1 log.txt 2 2 ' 1 2 log.txt 2 3 ' 2 3 log.txt 2 4 ' 1 4 # 输出顺序号 NR, 匹配文本行号 $ awk '{print NR,FNR,$1,$2,$3}' log.txt --------------------------------------------- 1 1 2 this is 2 2 3 Are you 3 3 This's a test 4 4 10 There are # 指定输出分割符 $ awk '{print $1,$2,$5}' OFS=" $ " log.txt --------------------------------------------- 2 $ this $ test 3 $ Are $ awk This's $ a $ 10 $ There $
使用正则,字符串匹配
# 输出第二列包含 "th",并打印第二列与第四列 $ awk '$2 ~ /th/ {print $2,$4}' log.txt --------------------------------------------- this a~ 表示模式开始。// 中是模式。
# 输出包含 "re" 的行 $ awk '/re/ ' log.txt --------------------------------------------- 3 Do you like awk 10 There are orange,apple,mongo
忽略大小写
$ awk 'BEGIN{IGNORECASE=1} /this/' log.txt --------------------------------------------- 2 this is a test This's a test
模式取反
$ awk '$2 !~ /th/ {print $2,$4}' log.txt --------------------------------------------- Are like a There orange,apple,mongo $ awk '!/th/ {print $2,$4}' log.txt --------------------------------------------- Are like a There orange,apple,mongo
awk脚本
关于 awk 脚本,我们需要注意两个关键词 BEGIN 和 END。
- BEGIN{ 这里面放的是执行前的语句 }
- END {这里面放的是处理完所有的行后要执行的语句 }
- {这里面放的是处理每一行时要执行的语句}
假设有这么一个文件(学生成绩表):
$ cat score.txt Marry 2143 78 84 77 Jack 2321 66 78 45 Tom 2122 48 77 71 Mike 2537 87 97 95 Bob 2415 40 57 62我们的 awk 脚本如下:
$ cat cal.awk #!/bin/awk -f #运行前 BEGIN { math = 0 english = 0 computer = 0 printf "NAME NO. MATH ENGLISH COMPUTER TOTAL\n" printf "---------------------------------------------\n" } #运行中 { math+=$3 english+=$4 computer+=$5 printf "%-6s %-6s %4d %8d %8d %8d\n", $1, $2, $3,$4,$5, $3+$4+$5 } #运行后 END { printf "---------------------------------------------\n" printf " TOTAL:%10d %8d %8d \n", math, english, computer printf "AVERAGE:%10.2f %8.2f %8.2f\n", math/NR, english/NR, computer/NR }我们来看一下执行结果:
$ awk -f cal.awk score.txt NAME NO. MATH ENGLISH COMPUTER TOTAL --------------------------------------------- Marry 2143 78 84 77 239 Jack 2321 66 78 45 189 Tom 2122 48 77 71 196 Mike 2537 87 97 95 279 Bob 2415 40 57 62 159 --------------------------------------------- TOTAL: 319 393 350 AVERAGE: 63.80 78.60 70.00
另外一些实例
AWK 的 hello world 程序为:
BEGIN { print "Hello, world!" }计算文件大小
$ ls -l *.txt | awk '{sum+=$5} END {print sum}' -------------------------------------------------- 666581从文件中找出长度大于 80 的行:
awk 'length>80' log.txt打印九九乘法表
seq 9 | sed 'H;g' | awk -v RS='' '{for(i=1;i<=NF;i++)printf("%dx%d=%d%s", i, NR, i*NR, i==NR?"\n":"\t")}'

grep
Linux grep 命令用于查找文件里符合条件的字符串。
grep 指令用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设 grep 指令会把含有范本样式的那一列显示出来。若不指定任何文件名称,或是所给予的文件名为 -,则 grep 指令会从标准输入设备读取数据。
语法
grep [-abcEFGhHilLnqrsvVwxy][-A<显示行数>][-B<显示列数>][-C<显示列数>][-d<进行动作>][-e<范本样式>][-f<范本文件>][--help][范本样式][文件或目录...]参数:
- -a 或 --text : 不要忽略二进制的数据。
- -A<显示行数> 或 --after-context=<显示行数> : 除了显示符合范本样式的那一列之外,并显示该行之后的内容。
- -b 或 --byte-offset : 在显示符合样式的那一行之前,标示出该行第一个字符的编号。
- -B<显示行数> 或 --before-context=<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前的内容。
- -c 或 --count : 计算符合样式的列数。
- -C<显示行数> 或 --context=<显示行数>或-<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前后的内容。
- -d <动作> 或 --directories=<动作> : 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。
- -e<范本样式> 或 --regexp=<范本样式> : 指定字符串做为查找文件内容的样式。
- -E 或 --extended-regexp : 将样式为延伸的正则表达式来使用。
- -f<规则文件> 或 --file=<规则文件> : 指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。
- -F 或 --fixed-regexp : 将样式视为固定字符串的列表。
- -G 或 --basic-regexp : 将样式视为普通的表示法来使用。
- -h 或 --no-filename : 在显示符合样式的那一行之前,不标示该行所属的文件名称。
- -H 或 --with-filename : 在显示符合样式的那一行之前,表示该行所属的文件名称。
- -i 或 --ignore-case : 忽略字符大小写的差别。
- -l 或 --file-with-matches : 列出文件内容符合指定的样式的文件名称。
- -L 或 --files-without-match : 列出文件内容不符合指定的样式的文件名称。
- -n 或 --line-number : 在显示符合样式的那一行之前,标示出该行的列数编号。
- -o 或 --only-matching : 只显示匹配PATTERN 部分。
- -q 或 --quiet或–silent : 不显示任何信息。
- -r 或 --recursive : 此参数的效果和指定"-d recurse"参数相同。
- -s 或 --no-messages : 不显示错误信息。
- -v 或 --invert-match : 显示不包含匹配文本的所有行。
- -V 或 --version : 显示版本信息。
- -w 或 --word-regexp : 只显示全字符合的列。
- -x --line-regexp : 只显示全列符合的列。
- -y : 此参数的效果和指定"-i"参数相同。
实例
1、在当前目录中,查找后缀有 file 字样的文件中包含 test 字符串的文件,并打印出该字符串的行。此时,可以使用如下命令:
grep test *file结果如下所示:
$ grep test test* #查找前缀有“test”的文件包含“test”字符串的文件 testfile1:This a Linux testfile! #列出testfile1 文件中包含test字符的行 testfile_2:This is a linux testfile! #列出testfile_2 文件中包含test字符的行 testfile_2:Linux test #列出testfile_2 文件中包含test字符的行2、以递归的方式查找符合条件的文件。例如,查找指定目录/etc/acpi 及其子目录(如果存在子目录的话)下所有文件中包含字符串"update"的文件,并打印出该字符串所在行的内容,使用的命令为:
grep -r update /etc/acpi输出结果如下:
$ grep -r update /etc/acpi #以递归的方式查找“etc/acpi” #下包含“update”的文件 /etc/acpi/ac.d/85-anacron.sh:# (Things like the slocate updatedb cause a lot of IO.) Rather than /etc/acpi/resume.d/85-anacron.sh:# (Things like the slocate updatedb cause a lot of IO.) Rather than /etc/acpi/events/thinkpad-cmos:action=/usr/sbin/thinkpad-keys--update3、反向查找。前面各个例子是查找并打印出符合条件的行,通过"-v"参数可以打印出不符合条件行的内容。
查找文件名中包含 test 的文件中不包含test 的行,此时,使用的命令为:
grep -v test *test*结果如下所示:
$ grep-v test* #查找文件名中包含test 的文件中不包含test 的行 testfile1:helLinux! testfile1:Linis a free Unix-type operating system. testfile1:Lin testfile_1:HELLO LINUX! testfile_1:LINUX IS A FREE UNIX-TYPE OPTERATING SYSTEM. testfile_1:THIS IS A LINUX TESTFILE! testfile_2:HELLO LINUX! testfile_2:Linux is a free unix-type opterating system.2 篇笔记 写笔记
场景: 系统报警显示了时间,但是日志文件太大无法直接 cat 查看。(查询含有特定文本的文件,并拿到这些文本所在的行)
解决:
grep -n '2019-10-24 00:01:11' *.logLinux 里利用 grep 和 find 命令查找文件内容
从文件内容查找匹配指定字符串的行:
$ grep "被查找的字符串" 文件名例子:在当前目录里第一级文件夹中寻找包含指定字符串的 .in 文件
grep "thermcontact" /.in从文件内容查找与正则表达式匹配的行:
$ grep –e "正则表达式" 文件名查找时不区分大小写:
$ grep –i "被查找的字符串" 文件名查找匹配的行数:
$ grep -c “被查找的字符串” 文件名
从文件内容查找不匹配指定字符串的行:
$ grep –v "被查找的字符串" 文件名从根目录开始查找所有扩展名为 .log 的文本文件,并找出包含 “ERROR” 的行:
$ find / -type f -name "*.log" | xargs grep "ERROR"例子:从当前目录开始查找所有扩展名为 .in 的文本文件,并找出包含 “thermcontact” 的行:
find . -name "*.in" | xargs grep "thermcontact"
 Linux 命令大全
Linux 命令大全 Linux 命令大全
Linux 命令大全awk、sed、grep更适合的方向:
- grep 更适合单纯的查找或匹配文本
- sed 更适合编辑匹配到的文本
- awk 更适合格式化文本,对文本进行较复杂格式处理
关于awk内建变量个人见解,简单易懂
解释一下变量:
变量:分为内置变量和自定义变量;输入分隔符FS和输出分隔符OFS都属于内置变量。
内置变量就是awk预定义好的、内置在awk内部的变量,而自定义变量就是用户定义的变量。
- FS(Field Separator):输入字段分隔符, 默认为空白字符
- OFS(Out of Field Separator):输出字段分隔符, 默认为空白字符
- RS(Record Separator):输入记录分隔符(输入换行符), 指定输入时的换行符
- ORS(Output Record Separate):输出记录分隔符(输出换行符),输出时用指定符号代替换行符
- NF(Number for Field):当前行的字段的个数(即当前行被分割成了几列)
- NR(Number of Record):行号,当前处理的文本行的行号。
- FNR:各文件分别计数的行号
- ARGC:命令行参数的个数
- ARGV:数组,保存的是命令行所给定的各参数
自定义变量的方法
- 方法一:-v varname=value ,变量名区分字符大小写。
- 方法二:在program中直接定义。

















 283
283

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









