






 本文详细介绍了GPU中的Warp调度过程,以Volta架构为例,每个SM有4个WarpScheduler,每个周期最多可调度16个warps。内容包括Warp状态、调度策略以及性能统计数据如active warps、stalled warps和发射率等。通过案例分析,揭示了提高kernel效率的关键在于增加eligible warps数量和减少stall时间。
本文详细介绍了GPU中的Warp调度过程,以Volta架构为例,每个SM有4个WarpScheduler,每个周期最多可调度16个warps。内容包括Warp状态、调度策略以及性能统计数据如active warps、stalled warps和发射率等。通过案例分析,揭示了提高kernel效率的关键在于增加eligible warps数量和减少stall时间。
本文内容主要参考YT上的这个视频:
https://www.youtube.com/watch?v=nYSdsJE2zMs
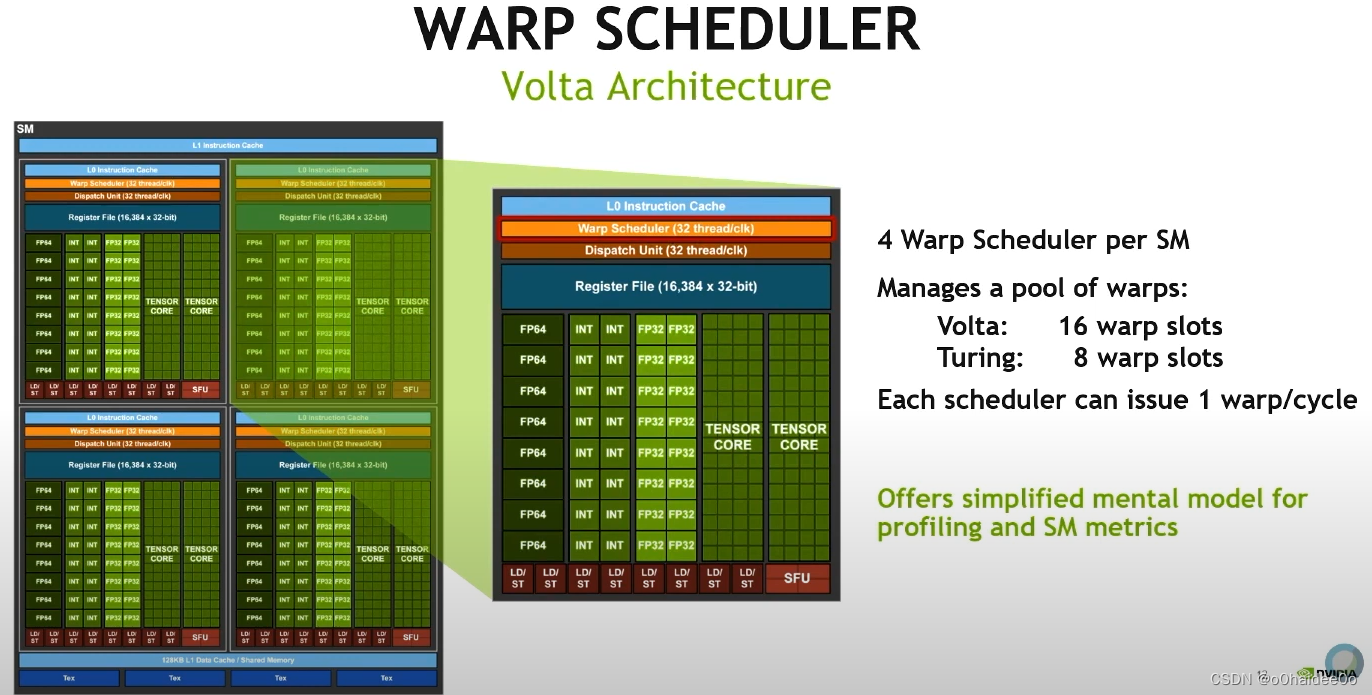
Warp硬件架构介绍
以Volta架构为例,每个SM有4个Warp Scheduler,每个Warp Scheduler有4个warp slots,因此Volta架构中整个GPU每个cycle总共最多可以有16个warps同时处于被调度的状态,每个时钟周期最多可以发射4个warps。(而以前的Turing架构只有8个warp slots,可以看出未来GPU中warp slot数量应该是有上升趋势的。)
Warp调度过程介绍
为了画图简单,下面就用8个warp slots做演示,每个时钟周期也按照只能发射一个warp去假设。
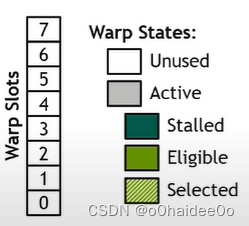
首先,下图左侧画的Warp Slots中0-7个方块代表了GPU中的全部8个Warp Slots。其次,右侧的Warp States介绍了NV中对warp的5种分类,其中白色Unused表示还在warp队列中排队的warp,这个状态的warp一般先不用关心;凡是有颜色的warp其实都属于Active Warp,这里的灰色warp是不属于其他3种绿色的Active Warp,指这个warp所在的block已经被调度到指定SM上的warp(这里为了严谨说的有点绕了,简单理解灰色块就是还没准备好被发射的warp);Eligible Warp就是准备好被发射的Warp;Stalled是指因为一些原因(指令还没加载完成、依赖项还没有得到等等)而被中断暂停的warp;Seleted表示被选中发射的warp。
下面就看一下warp调度过程:
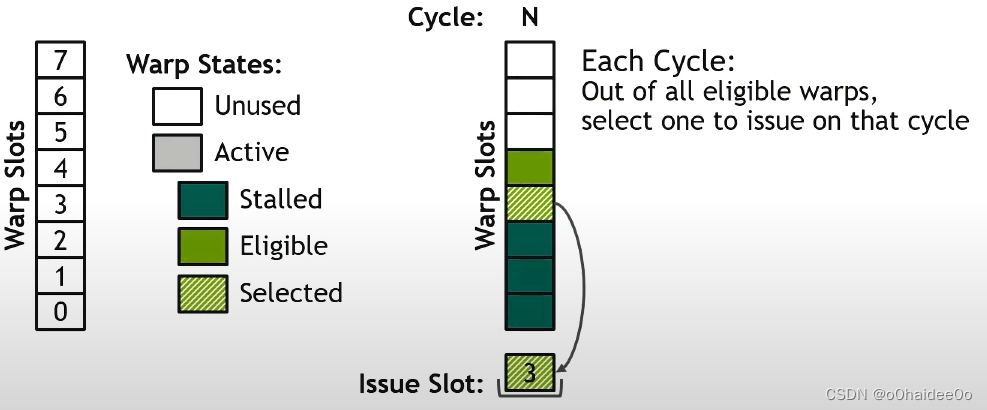
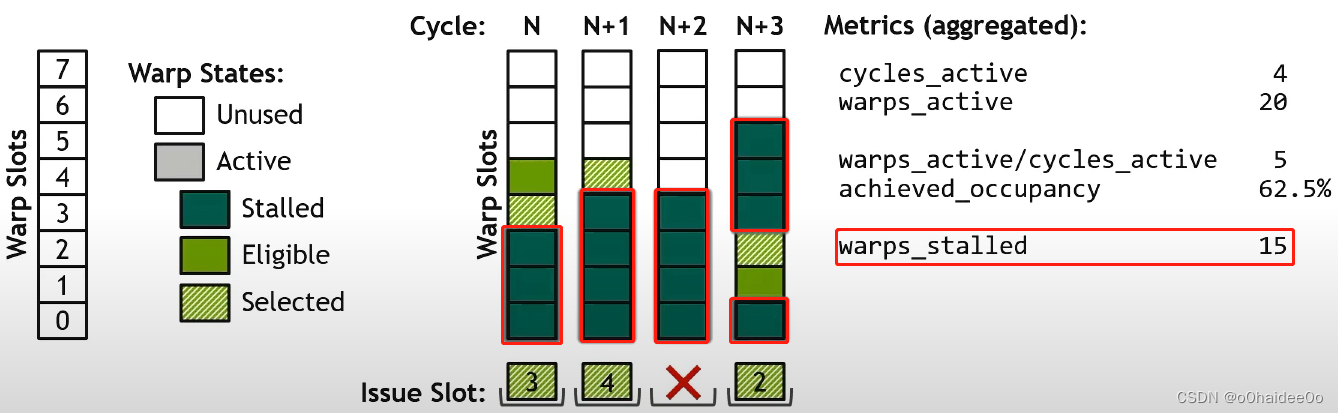
假设核函数执行到第N个时钟周期时,有3个Stalled Warp(最下面深绿色的0-2 Slots中的Warp)和2个Eligible Warp以及3个Unused Warp。这时,随机选取一个Eligible Warp(3号warp)放在下面的Issue slot中发射。这个时钟周期就过去了。
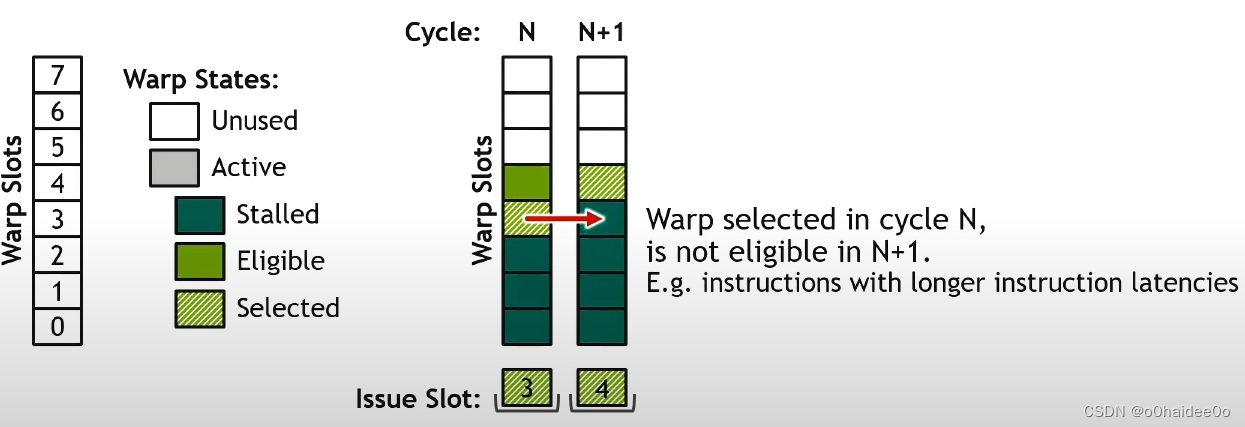
到了下一个也就是N+1个时钟周期时,上一步选的3号warp因为取指令需要不止一个时钟周期而被stall变成深绿色。这时所有之前发射的warp都被stall了,warp scheduler不得不再选一个eligible warp来发射,因此选则了唯一的eligible warp也就是4号warp来发射。
再到N+2个时钟周期时,有一个warp执行结束就退出warp slot了,而warp slot中也没有可以发射的eligible warp了,因此这个周期就这样空过去了。
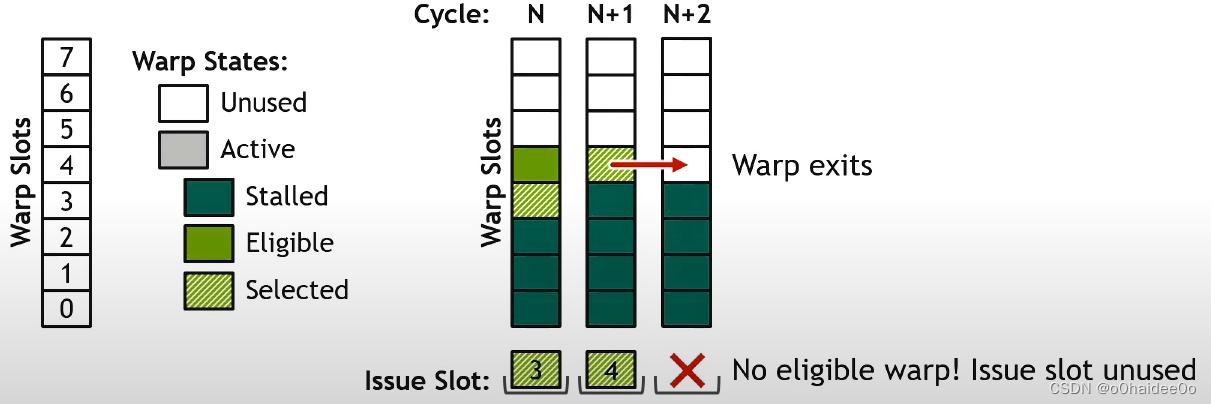
再下一个周期即N+3个时钟周期,新增了两个eligible warp,又在eligible warp中随机选择一个(2号)warp发射。
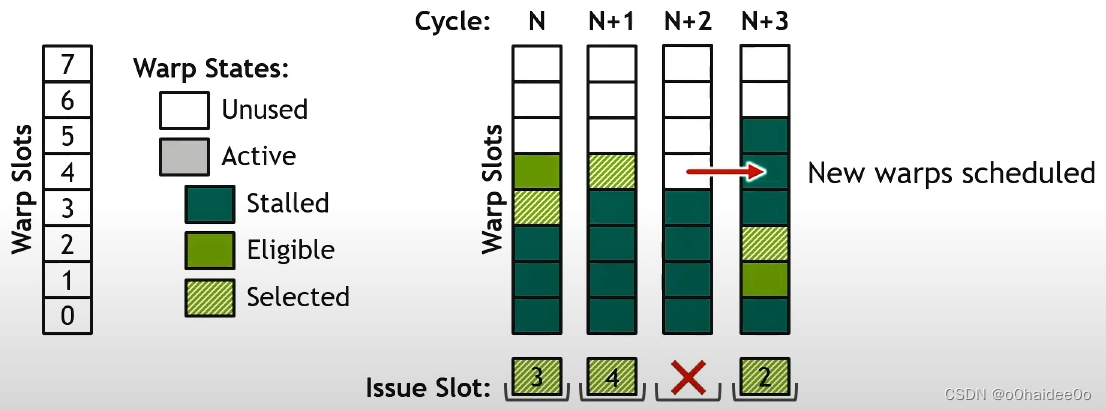
Scheduler Statistics 数据解读
cycles_active:一共有多少个包含active warp的cycle。
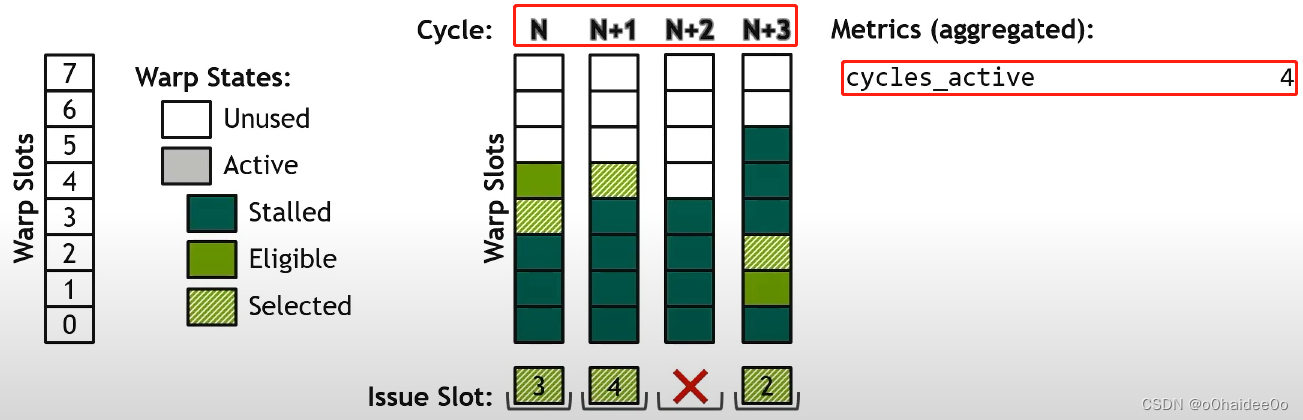
warps_active:一共有多少个active warp(有颜色的方块有多少个)。
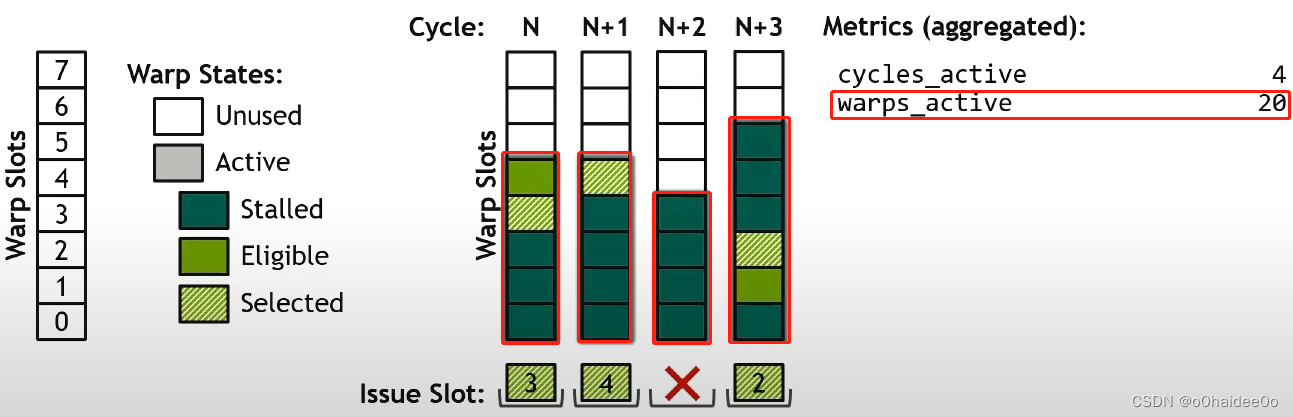
warp_active/cycle_active:warps_active除以cycles_active
achieved_occupancy:warps_active/(warp最大active数量*cycles_active)(warp最大active数量就是上文提到的,Volta的16和Turing的8)
achieved_occupancy = 有颜色的方块数量 / 所有的方块数量
warps_stalled:被stall的warp数量。即深绿色方块的数量。
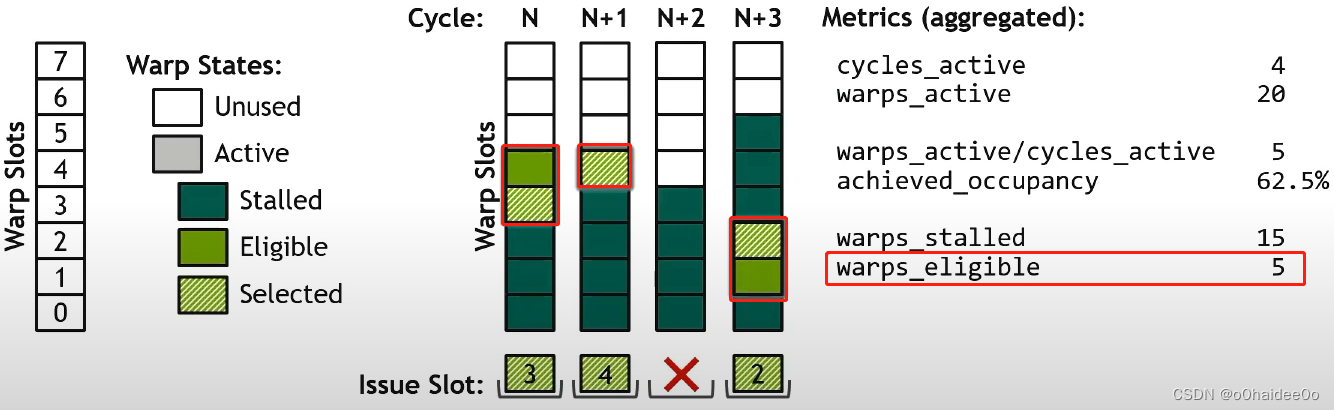
warps_eligible:全部cycle中eligible warp出现的总数。 即浅绿色方块的数量。
warps_issued:总共发射的warp数量。 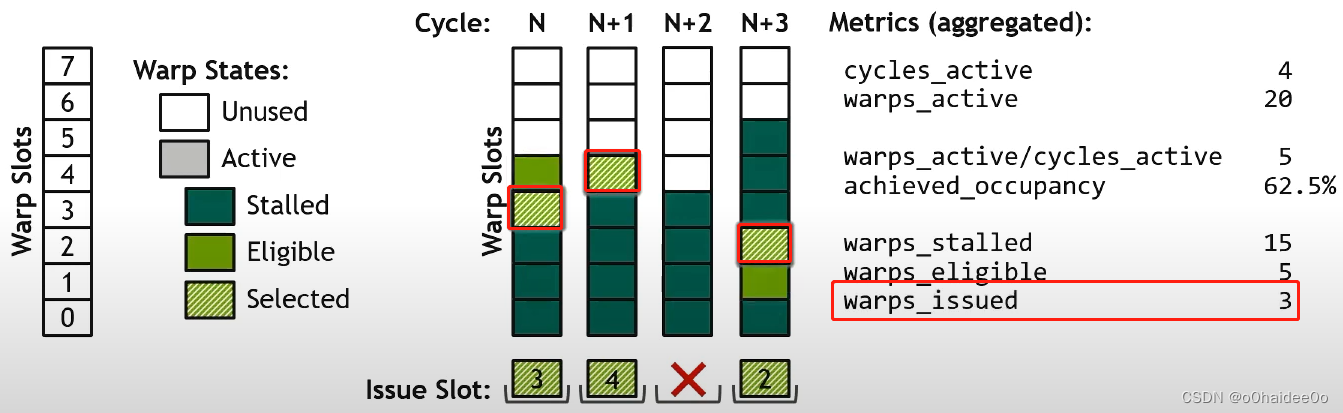
warps_issued/cycles_active:字面意思
issue_slot_utilization:发射了warp的cycle数量 / cycles_active
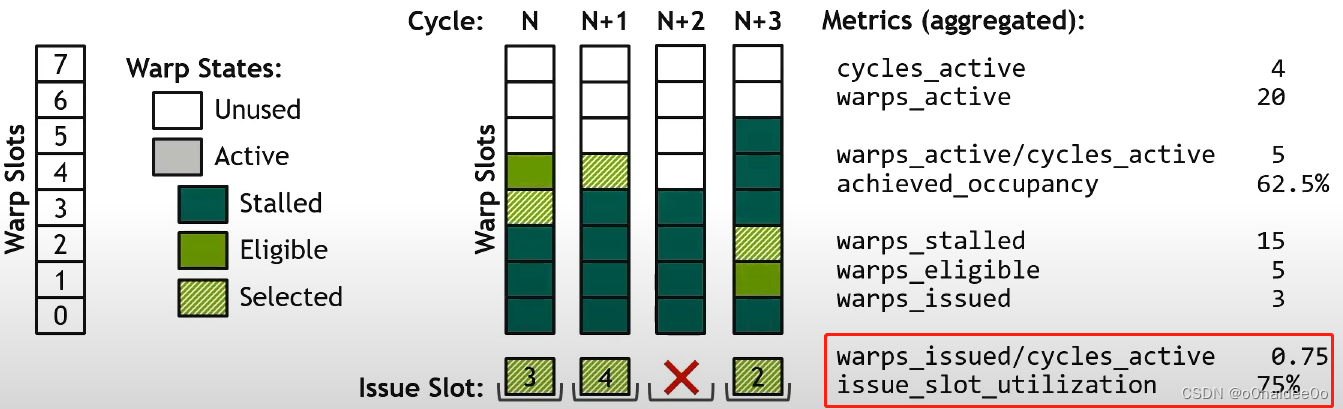
上述数据中,所有以warps开头的数据在Nsight Compute中都是要除以cycles_active来显示的。通常后面会加 Per Scheduler表示除以cycles_active。

这个例子是在V100中运行的,V100最佳情况下Active Warps Per Scheduler可以无限接近16,但该kernel平均分配每个调度器7.65个active warp,但是每个周期只有平均0.92个warp是eligible warp,真正被发射的每个周期才0.41个warp,这是很差的指标了。一般是两种方法改善:一是增加eligible warp的数量,二是减少active warp的stall时间。

















 1515
1515

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









