







 本文介绍StarGAN,一种能在多个领域间进行图像生成的生成对抗网络。通过引入辅助分类器和循环一致性损失,StarGAN实现了高质量的跨域图像转换。实验中采用WGAN-gp改进训练稳定性。
本文介绍StarGAN,一种能在多个领域间进行图像生成的生成对抗网络。通过引入辅助分类器和循环一致性损失,StarGAN实现了高质量的跨域图像转换。实验中采用WGAN-gp改进训练稳定性。
3. Star Generative Adversarial Networks
3.1. MultiDomain ImagetoImage Translation
学习目标是训练一个能够在multiple domains之间相互生成的生成器GGG
定义xxx为输入图像,yyy为生成图像,ccc为target domain label,于是有G(x,c)→yG(x, c)\rightarrow yG(x,c)→y
判别器DDD包含两部分,一部分是常规的判别真假的判别器DsrcD_{src}Dsrc,另一部分是auxiliary classifier DclsD_{cls}Dcls
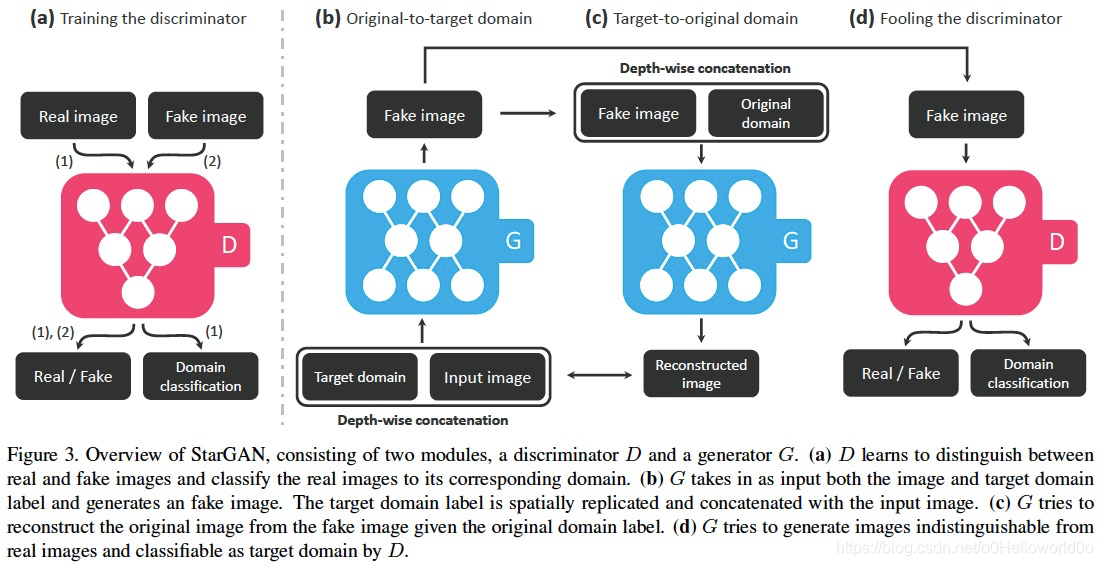
Figure3展示了StarGAN的训练过程
Adversarial Loss
Ladv=Ex[logDsrc(x)]+Ex,c[log(1−Dsrc(G(x,c)))](1)
\begin{aligned}
\mathcal{L}_{adv}=&\mathbb{E}_x\left [ \log D_{src}(x) \right ] +\\
&\mathbb{E}_{x,c}\left [ \log\left ( 1-D_{src}\left ( G(x,c) \right ) \right ) \right ] \qquad(1)
\end{aligned}
Ladv=Ex[logDsrc(x)]+Ex,c[log(1−Dsrc(G(x,c)))](1)
Domain Classification Loss
对于判别器DDD,需要正确地将real image xxx预测为所对应的domain c′c'c′
Lclsr=Ex,c′[−logDcls(c′∣x)](2)
\mathcal{L}_{cls}^r=\mathbb{E}_{x,c'}\left [ -\log D_{cls}\left ( c'\mid x \right ) \right ] \qquad(2)
Lclsr=Ex,c′[−logDcls(c′∣x)](2)
对于生成器GGG,需要最小化fake image G(x,c)G(x,c)G(x,c)被预测为domain
Lclsf=Ex,c[−logDcls(c∣G(x,c))](3)
\mathcal{L}_{cls}^f=\mathbb{E}_{x,c}\left [ -\log D_{cls}\left ( c\mid G(x,c) \right ) \right ] \qquad(3)
Lclsf=Ex,c[−logDcls(c∣G(x,c))](3)
Reconstruction Loss
对于生成器GGG,只考虑公式(1)和(3)无法保证GGG只修改图像中与target domain有关的部分,修改与target domain无关的部分,因此引入文献[8, 32]中提出的cycle consistency loss
Lrec=Ex,c,c′∥x−G(G(x,c),c′)∥1(4) \mathcal{L}_{rec}=\mathbb{E}_{x,c,c'}\left \| x-G\left ( G(x,c), c' \right ) \right \|_1 \qquad(4) Lrec=Ex,c,c′∥x−G(G(x,c),c′)∥1(4)
Full Objective
LD=−Ladv+λclsLclsr(5)
\mathcal{L}_D=-\mathcal{L}_{adv}+\lambda_{cls}\mathcal{L}_{cls}^r \qquad(5)
LD=−Ladv+λclsLclsr(5)
LG=Ladv+λclsLclsf+λrecLrec(6)
\mathcal{L}_G=\mathcal{L}_{adv}+\lambda_{cls}\mathcal{L}_{cls}^f+\lambda_{rec}\mathcal{L}_{rec} \qquad(6)
LG=Ladv+λclsLclsf+λrecLrec(6)
注:DDD需要最大化Ladv\mathcal{L}_{adv}Ladv,所以加上了一个负号
实验中设置λcls=1\lambda_{cls}=1λcls=1,λrec=10\lambda_{rec}=10λrec=10
3.2. Training with Multiple Datasets
如果涉及多个数据集,每个数据集的attribute是不一样的
Mask Vector
引入mask vector mmm用于指示label中哪些分量是已知的
假设使用nnn个数据集,则mask vector mmm是一个nnn维的one-hot向量,并且将domain label扩展为
c~=[c1,⋯ ,cn,m](7)
\tilde{c}=\left [ c_1,\cdots,c_n,m \right ] \qquad(7)
c~=[c1,⋯,cn,m](7)
其中cic_ici表示第iii个数据集的attribute的0-1向量
假设当前图像属于第kkk个数据集,那么ckc_kck为表示attribute的0-1向量,其它ci(i≠k)c_i(i\neq k)ci(i=k)为全0向量
(个人认为这个mask vector的设计一般般)
4. Implementation
Improved GAN Training
为了使GAN的训练过程更加稳定,同时生成高质量的图像,将公式(1)替换为WGAN-gp的版本
Ladv=Ex[Dsrc(x)]−Ex.c[Dsrc(G(x,c))]−λgpEx^(∥∇x^Dsrc(x^)∥2−1)2(8)
\begin{aligned}
\mathcal{L}_{adv}=&\mathbb{E}_x\left [ D_{src}(x) \right ]-\mathbb{E}_{x.c}\left [ D_{src}(G(x,c)) \right ] \\
&- \lambda_{gp}\mathbb{E}_{\hat{x}}\left ( \left \| \nabla_{\hat{x}}D_{src}\left ( \hat{x} \right ) \right \|_2-1 \right )^2 \qquad(8)
\end{aligned}
Ladv=Ex[Dsrc(x)]−Ex.c[Dsrc(G(x,c))]−λgpEx^(∥∇x^Dsrc(x^)∥2−1)2(8)
其中x^\hat{x}x^是一组真实图像和假图像的线性组合,实验中设置λgp=10\lambda_{gp}=10λgp=10
Network Architecture
只对生成器GGG使用instance normalization,判别器DDD的结构为PatchGAN


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









