






想象一下,当前最先进的语言模型包含数百亿、数千亿个参数。这些模型实在是太大了,无法在单个GPU上训练,必须分布在多个GPU甚至多个计算节点上。目前学术界提出了一下3种并行策略:
- 数据并行(DP):将训练数据分成小批次分配给不同GPU,每个GPU拥有完整模型的副本
- 张量并行(TP):将单个计算操作分散到多个GPU上
- 流水线并行(PP):将模型的不同层分配到不同GPU上
此外,还可以使用ZeRO(零冗余优化器)技术来优化GPU内存使用。工业界通常都是将3者结合起来一起用,也就是3D并行:
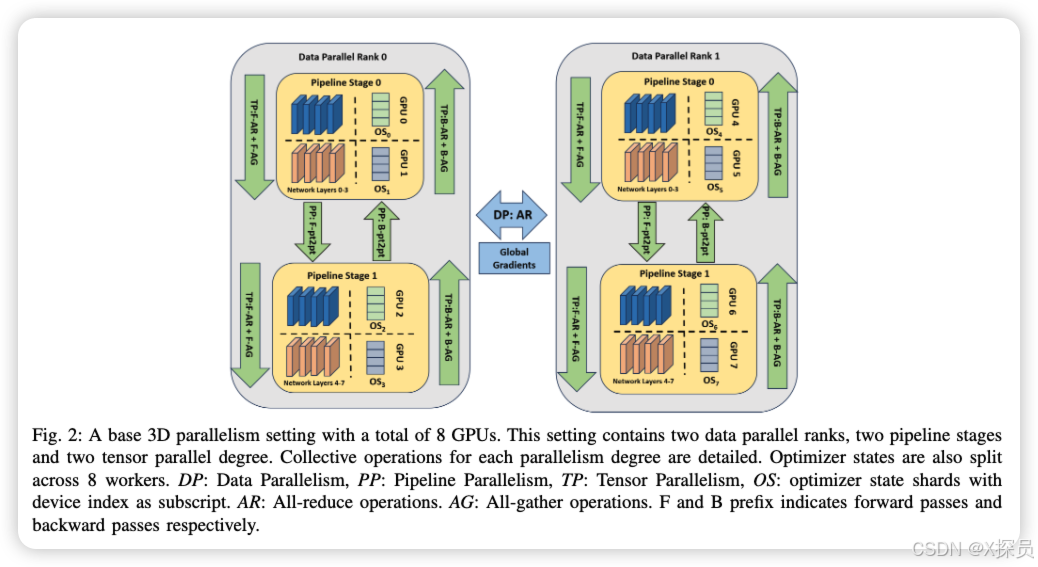
图片来源于:[2409.02423] Accelerating Large Language Model Training with Hybrid GPU-based Compression
对于一般企业就只是拿小基模微调的话,其实用不到所有的技术。
工业界小公司Pytorch中的并行化实践
数据并行(DP)
import torch.nn as nn
model = nn.Linear(100, 10)
# Automatically split your data across available GPUs
model = nn.DataParallel(model)
model = model.cuda()分布式数据并行(Distributed Data Parallel, DDP)
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
# Initialize the distributed environment
# Make sure you set up your environment variables correctly
dist.init_process_group(backend='nccl')
model = nn.Linear(100, 10).cuda()
model = DDP(model)完全分片的数据并行(Fully Sharded Data Parallel,FSDP)
# Based on: https://github.com/pytorch/examples/blob/master/mnist/main.py
import os
import argparse
import functools
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.optim.lr_scheduler import StepLR
import torch.distributed as dist
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.data.distributed import DistributedSampler
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
from torch.distributed.fsdp.fully_sharded_data_parallel import (
CPUOffload,
BackwardPrefetch,
)
from torch.distributed.fsdp.wrap import (
size_based_auto_wrap_policy,
enable_wrap,
wrap,
)节选自:Getting Started with Fully Sharded Data Parallel(FSDP)
当然还有DeepSpeed(不是DeepSeek)等这种大而全的框架,可以方便的帮我们并行化。
这个系列只讲概念,只带我的朋友们入门。丰富的理论反而不适合我们的大脑机制,5分钟内能搞清楚一些未接触的概念是比较适合我们的大脑机能的。要想弄懂就自行动手搜索,现在ChatGPT的DeepSearch、Google的gemini等等,都能让你从一个概念出发得出一整个理论丰富的研究报告。
费曼说:“What I cannot create, I do not understand.”

















 21
21

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









