






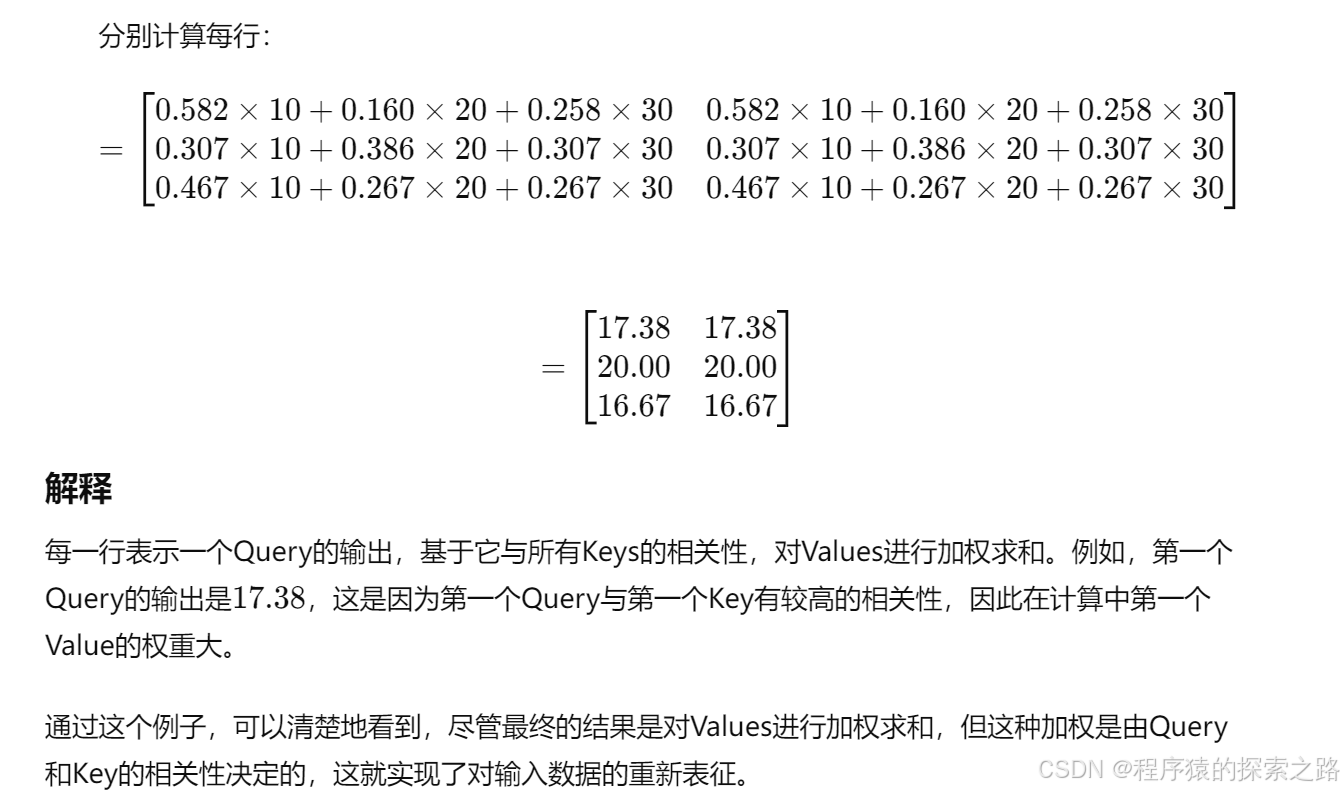
注1:
self.cls_token.expand(x.shape[0], -1, -1)
-1 表示在对应的维度上不改变大小。
self.cls_token 是一个形状为 (1, 1, embed_dim) 的张量,其中:
第一个维度大小为 1,表示单个 batch。
第二个维度大小为 1,表示单个 token。
第三个维度大小为 embed_dim,表示 token 的嵌入维度。
x.shape[0]:
x.shape[0] 表示输入张量 x 的第一个维度大小,即批量大小(batch size)。
expand 方法:
self.cls_token.expand(x.shape[0], -1, -1) 使用 expand 方法将 self.cls_token 的形状从 (1, 1, embed_dim) 扩展到 (batch_size, 1, embed_dim),其中 batch_size 是输入张量 x 的批量大小。
注2:

预备知识:
Vision Transformer (ViT)




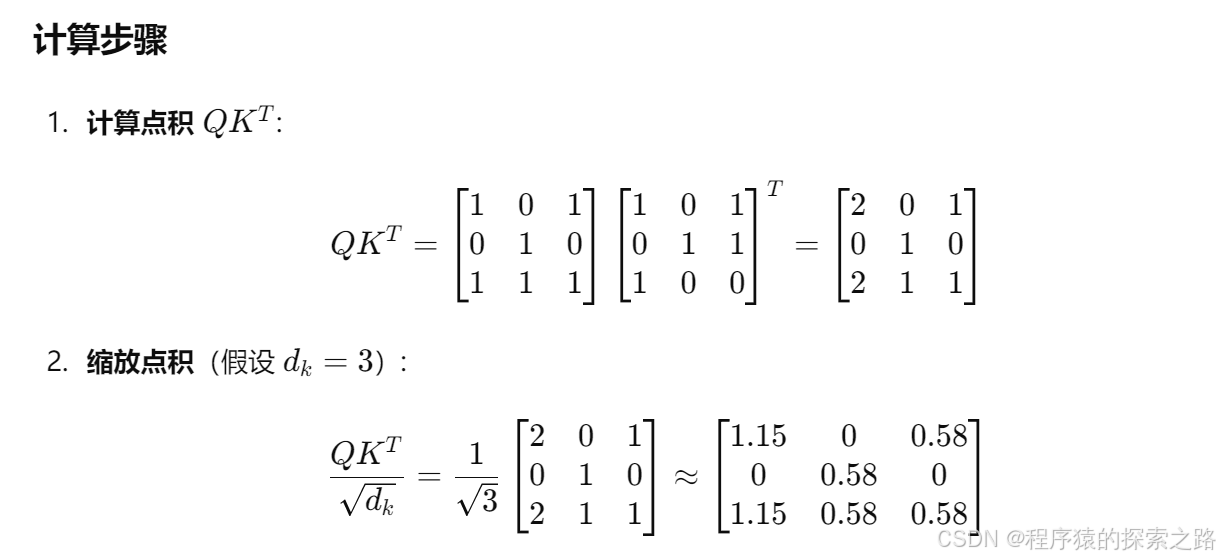


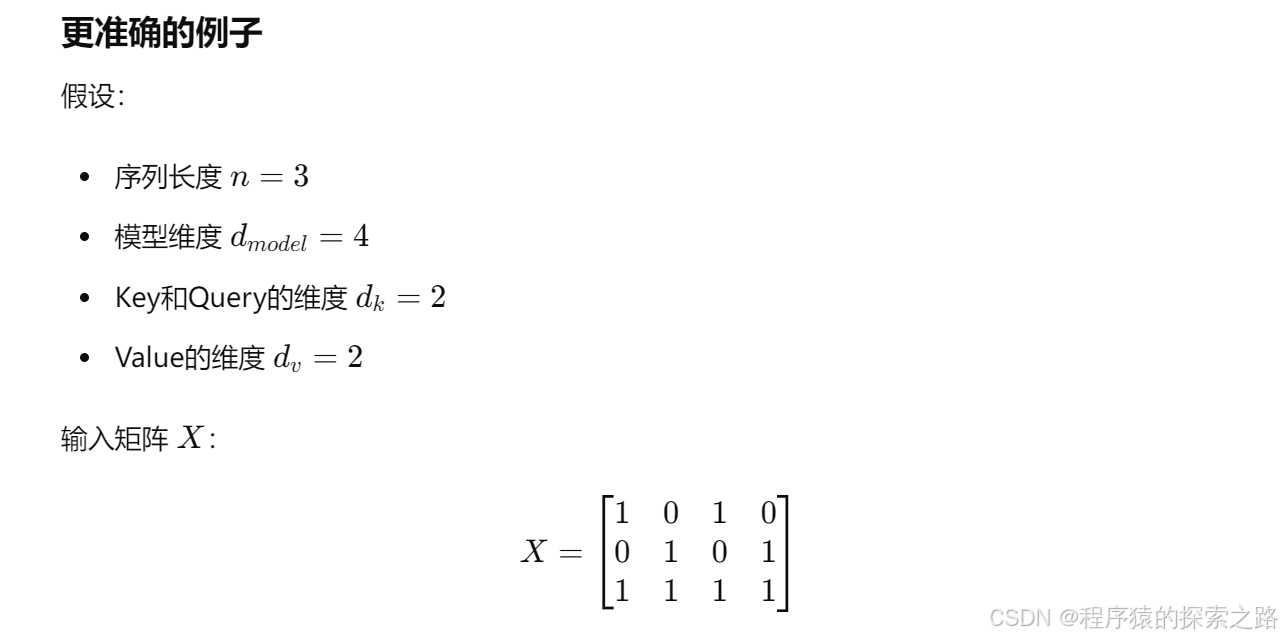
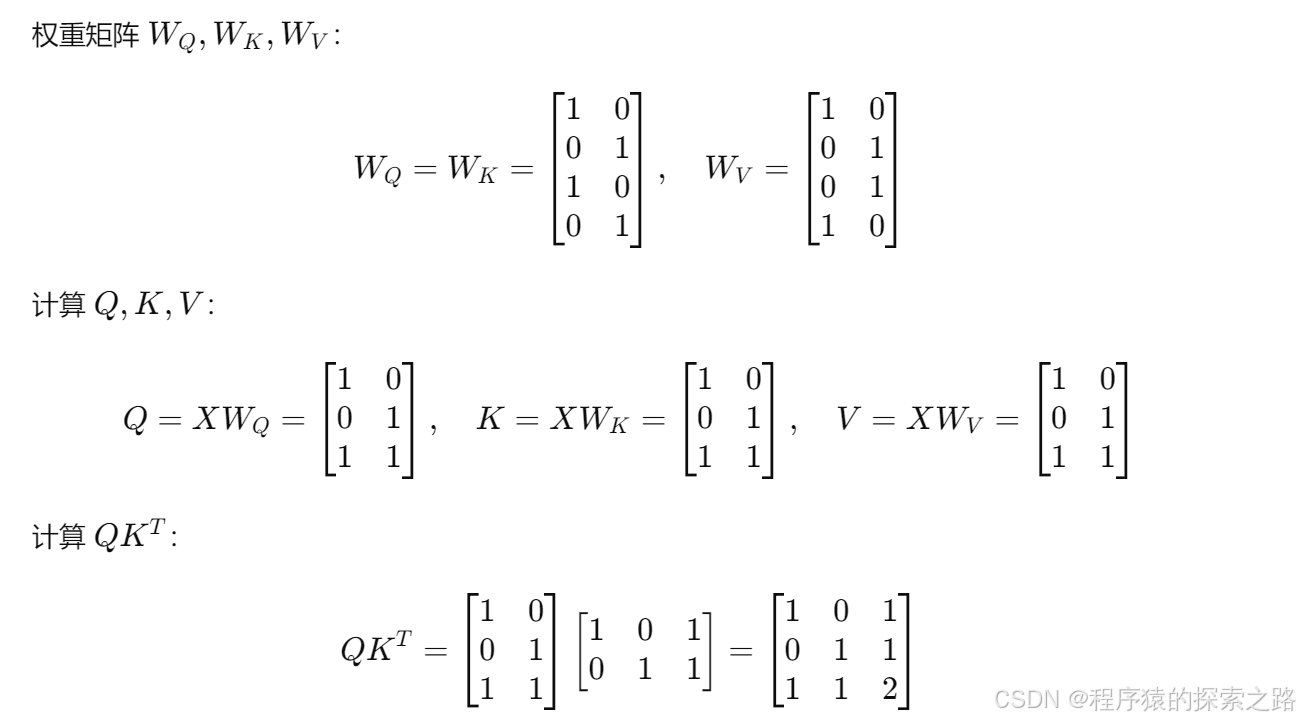





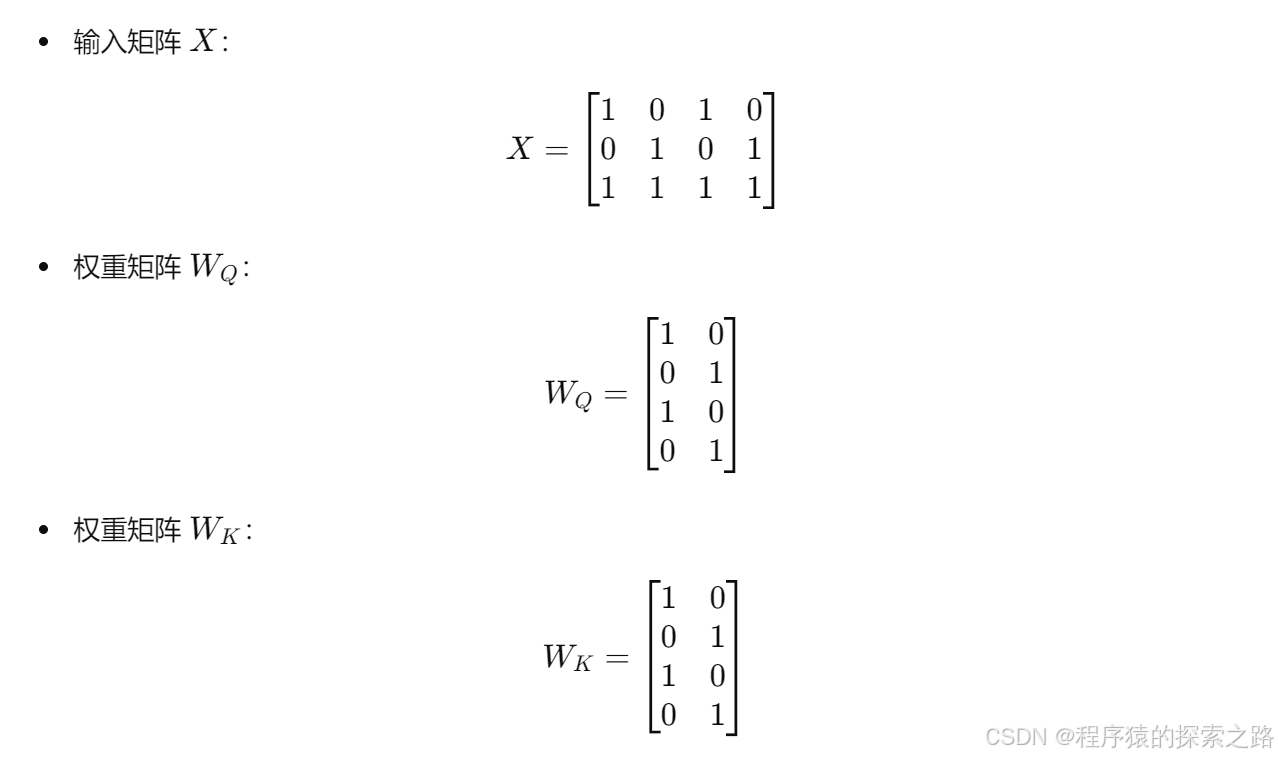
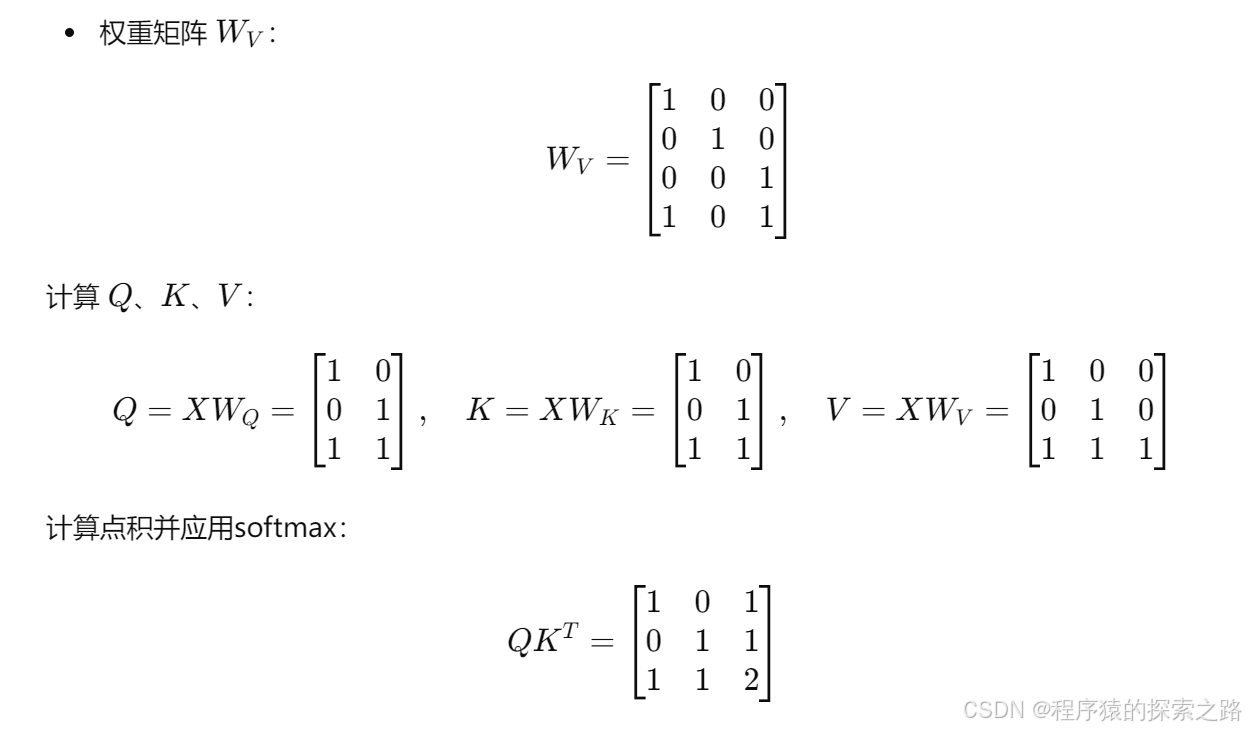

位置编码:









架构基础:ViT是由Google提出的一种基于Transformer的图像分类模型。它直接将图像划分为一系列不重叠的patches,并将这些patches视为序列数据输入Transformer模型。每个patch都会被映射到一个固定长度的向量,这些向量再通过位置编码后输入到Transformer中进行处理。
模型组成:
Patch Embedding:将输入图像划分为固定大小的patch,并通过线性投影将其映射到高维空间。
位置编码:由于Transformer模型无法处理位置信息,因此需要为每个patch添加位置编码。
Transformer编码器:使用标准的Transformer编码器,对输入的patch序列进行处理,提取特征。
应用场景:主要用于图像分类任务。ViT的设计使其能够处理大规模图像数据集,尤其在使用大型预训练模型时性能表现出色。
Swin Transformer (Swin-ViT)
架构基础:Swin Transformer是一种层次化的视觉Transformer模型,使用移动窗口(Shifted Windows)机制来处理图像数据。其设计目的是通过局部窗口的自注意力机制,捕捉图像中的局部和全局信息。
模型组成:
Patch Embedding:与ViT类似,Swin Transformer也将图像划分为patches,并通过线性投影进行高维映射。
移动窗口注意力:在每个层次上,Swin Transformer将图像划分为固定大小的窗口,并在这些窗口内进行自注意力计算。与ViT不同的是,Swin Transformer会在不同的层次上移动这些窗口,以捕捉跨窗口的依赖关系。
层次化设计:Swin Transformer通过多层的方式,从较小的patch到较大的区域逐步提取特征。
应用场景:除了图像分类外,Swin Transformer在目标检测、图像分割等任务中也表现出色。其层次化的设计使其在处理高分辨率图像时具有优势。
总结
结构设计:
ViT:直接将图像划分为patches,并通过标准的Transformer进行处理。
Swin-ViT:采用层次化设计,通过移动窗口的自注意力机制,逐步从局部到全局提取特征。
应用范围:
ViT:主要用于图像分类任务,在大规模预训练模型上表现优越。
Swin-ViT:除了图像分类,还在目标检测和图像分割等任务中表现出色,适用于处理高分辨率图像。
另外:
Swin Transformer使用了类似卷积神经网络中的层次化构建方法(Hierarchical feature maps),比如特征图尺寸中有对图像下采样4倍的,8倍的以及16倍的,这样的backbone有助于在此基础上构建目标检测,实例分割等任务。而在之前的Vision Transformer中是一开始就直接下采样16倍,后面的特征图也是维持这个下采样率不变。
在Swin Transformer中使用了Windows Multi-Head Self-Attention(W-MSA)的概念,比如在下图的4倍下采样和8倍下采样中,将特征图划分成了多个不相交的区域(Window),并且Multi-Head Self-Attention只在每个窗口(Window)内进行。相对于Vision Transformer中直接对整个(Global)特征图进行Multi-Head Self-Attention,这样做的目的是能够减少计算量的,尤其是在浅层特征图很大的时候。这样做虽然减少了计算量但也会隔绝不同窗口之间的信息传递,所以在论文中作者又提出了 Shifted Windows Multi-Head Self-Attention(SW-MSA)的概念,通过此方法能够让信息在相邻的窗口中进行传递。

ViT:
"""
original code from rwightman:
https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
"""
from functools import partial
from collections import OrderedDict
import torch
import torch.nn as nn
def drop_path(x, drop_prob: float = 0., training: bool = False):
"""
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
This is the same as the DropConnect impl I created for EfficientNet, etc networks, however,
the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for
changing the layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use
'survival rate' as the argument.
"""
if drop_prob == 0. or not training: # if there is no throwing or no training
return x
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device) # torch.rand() [0,1)
random_tensor.floor_() # binarize # random_tensor.floor_() 会将每个浮点数向下取整
output = x.div(keep_prob) * random_tensor
return output
# x = torch.tensor([[1.0, 2.0],
# [3.0, 4.0],
# [5.0, 6.0],
# [7.0, 8.0]])
# keep_prob = 1 - drop_prob
# keep_prob = 1 - 0.5
# keep_prob = 0.5
# shape = (x.shape[0],) + (1,) * (x.ndim - 1)
# shape = (4,) + (1,) * (2 - 1)
# shape = (4, 1)
#
# random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
# random_tensor = 0.5 + torch.rand((4, 1))
#
# # 生成的 random_tensor 可能类似于
# random_tensor = torch.tensor([[0.8],
# [0.3],
# [0.7],
# [0.1]])
# random_tensor.floor_()
# random_tensor = torch.tensor([[1.0],
# [0.0],
# [1.0],
# [0.0]])
# output = x.div(keep_prob) * random_tensor
# output = x.div(0.5) * random_tensor
#
# # 计算每个元素
# output = torch.tensor([[1.0 / 0.5, 2.0 / 0.5],
# [3.0 / 0.5, 4.0 / 0.5],
# [5.0 / 0.5, 6.0 / 0.5],
# [7.0 / 0.5, 8.0 / 0.5]]) * random_tensor
#
# output = torch.tensor([[2.0, 4.0],
# [6.0, 8.0],
# [10.0, 12.0],
# [14.0, 16.0]]) * random_tensor
#
# # 计算结果
# output = torch.tensor([[2.0, 4.0],
# [0.0, 0.0],
# [10.0, 12.0],
# [0.0, 0.0]])
# 在这个例子中,每个样本的路径被随机丢弃。
# 对于丢弃的路径,输出张量中的对应元素被设置为0,而未丢弃的路径的值按比例放大,以保持整体的期望值不变。
#
# 这种方法在深度学习中的作用类似于 Dropout,但它是对整个路径(例如残差块)进行随机丢弃,而不是对单个神经元。
# 这种技术能够提高模型的鲁棒性和泛化能力。
class DropPath(nn.Module):
"""
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
"""
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
class PatchEmbed(nn.Module):
"""
2D Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_c=3, embed_dim=768, norm_layer=None):
super().__init__()
img_size = (img_size, img_size) # (224,224)
patch_size = (patch_size, patch_size) # (16,16)
self.img_size = img_size # 224
self.patch_size = patch_size # 16
self.grid_size = (img_size[0] // patch_size[0], img_size[1] // patch_size[1]) # (14,14)
self.num_patches = self.grid_size[0] * self.grid_size[1] # 14*14=196
self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size) # 3,768,16,16
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
B, C, H, W = x.shape
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
# flatten: [B, C, H, W] -> [B, C, HW]
# transpose: [B, C, HW] -> [B, HW, C]
x = self.proj(x).flatten(2).transpose(1, 2)
x = self.norm(x)
return x
class Attention(nn.Module):
def __init__(self,
dim, # 输入token的dim
num_heads=8,
qkv_bias=False,
qk_scale=None,
attn_drop_ratio=0.,
proj_drop_ratio=0.):
super(Attention, self).__init__()
self.num_heads = num_heads # 12
head_dim = dim // num_heads # 64 = 768 / 12
self.scale = qk_scale or head_dim ** -0.5 # 这是计算 64 的倒数的平方根
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias) # on the last dimension of the input tensor
self.attn_drop = nn.Dropout(attn_drop_ratio)
# 在训练模式下(model.train()),Dropout 层以 50% 的概率随机将一些神经元的输出置为零。
# 在评估模式下(model.eval()),Dropout 层不会丢弃任何神经元的输出,但会将所有神经元的输出乘以 0.5(因为丢弃概率为 0.5)。
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop_ratio)
def forward(self, x):
# [batch_size, num_patches + 1, total_embed_dim]
B, N, C = x.shape
# print(x.shape) # torch.Size([8, 197, 768])
# print(self.qkv(x).shape) # torch.Size([8, 197, 2304])
# print(self.num_heads) # 12
# print(self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).shape)# torch.Size([8, 197, 3, 12, 64])
# input()
# qkv(): -> [batch_size, num_patches + 1, 3 * total_embed_dim]
# reshape: -> [batch_size, num_patches + 1, 3, num_heads, embed_dim_per_head] # # torch.Size([8, 197, 3, 12, 64])
# permute: -> [3, batch_size, num_heads, num_patches + 1, embed_dim_per_head] # # torch.Size([3, 8, 12, 197, 64])
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
# [batch_size, num_heads, num_patches + 1, embed_dim_per_head]
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple) # torch.Size([8, 12, 197, 64])
# print(q.shape) # torch.Size([8, 12, 197, 64])
# print(q.transpose(-2,-1).shape) # torch.Size([8, 12, 64, 197])
# print((q.permute(0,1,3,2)).shape) # torch.Size([8, 12, 64, 197])
#
# # print(q.permute(-2,-1)) # error: i.e. input.dim() = 4 is not equal to len(dims) = 2
#
# print("***")
#
# print((q @ k.transpose(-2, -1)) .shape) # torch.Size([8, 12, 197, 197])
#
# input()
# print(64 ** -0.5) # 这是计算 64 的倒数的平方根。
# input()
# transpose: -> [batch_size, num_heads, embed_dim_per_head, num_patches + 1]
# @: multiply -> [batch_size, num_heads, num_patches + 1, num_patches + 1]
attn = (q @ k.transpose(-2, -1)) * self.scale # torch.Size([8, 12, 197, 197])
attn = attn.softmax(dim=-1) # softmax 是一种常用的激活函数,通常用于多分类任务的输出层。它将输入的向量转换为概率分布,即输出的每个元素都在 0 到 1 之间,并且这些元素的总和为 1
attn = self.attn_drop(attn)
# @: multiply -> [batch_size, num_heads, num_patches + 1, embed_dim_per_head] # torch.Size([8, 12, 197, 64])
# transpose: -> [batch_size, num_patches + 1, num_heads, embed_dim_per_head] # torch.Size([8, 197, 12, 64])
# reshape: -> [batch_size, num_patches + 1, total_embed_dim] # torch.Size([8, 197, 768])
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x) # torch.Size([8, 197, 768])
x = self.proj_drop(x)
return x
class Mlp(nn.Module):
"""
MLP as used in Vision Transformer, MLP-Mixer and related networks
"""
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class Block(nn.Module):
def __init__(self,
dim,
num_heads,
mlp_ratio=4.,
qkv_bias=False,
qk_scale=None,
drop_ratio=0.,
attn_drop_ratio=0.,
drop_path_ratio=0.,
act_layer=nn.GELU,
norm_layer=nn.LayerNorm): # 对每个样本的所有通道计算均值和标准差
super(Block, self).__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop_ratio=attn_drop_ratio, proj_drop_ratio=drop_ratio)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path_ratio) if drop_path_ratio > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop_ratio)
def forward(self, x):
# torch.Size([8, 197, 768]) # Batch=8 对每个样本的所有通道计算均值和标准差
x = x + self.drop_path(self.attn(self.norm1(x))) # Attention input(x): torch.Size([8,197,768]) output: torch.Size([8,197,768])
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class VisionTransformer(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_c=3, num_classes=1000,
embed_dim=768, depth=12, num_heads=12, mlp_ratio=4.0, qkv_bias=True,
qk_scale=None, representation_size=None, distilled=False, drop_ratio=0.,
attn_drop_ratio=0., drop_path_ratio=0., embed_layer=PatchEmbed, norm_layer=None,
act_layer=None):
"""
Args:
img_size (int, tuple): input image size
patch_size (int, tuple): patch size
in_c (int): number of input channels
num_classes (int): number of classes for classification head
embed_dim (int): embedding dimension
depth (int): depth of transformer
num_heads (int): number of attention heads
mlp_ratio (int): ratio of mlp hidden dim to embedding dim
qkv_bias (bool): enable bias for qkv if True
qk_scale (float): override default qk scale of head_dim ** -0.5 if set
representation_size (Optional[int]): enable and set representation layer (pre-logits) to this value if set
distilled (bool): model includes a distillation token and head as in DeiT models
drop_ratio (float): dropout rate
attn_drop_ratio (float): attention dropout rate
drop_path_ratio (float): stochastic depth rate
embed_layer (nn.Module): patch embedding layer
norm_layer: (nn.Module): normalization layer
"""
super(VisionTransformer, self).__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
self.num_tokens = 2 if distilled else 1
norm_layer = norm_layer or partial(nn.LayerNorm, eps=1e-6)
act_layer = act_layer or nn.GELU
self.patch_embed = embed_layer(img_size=img_size, patch_size=patch_size, in_c=in_c, embed_dim=embed_dim)
num_patches = self.patch_embed.num_patches
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
# 定义一个可训练的分类标记(classification token,简称 cls_token)。这个标记用于表示整个输入序列或图像的全局信息,通常用于分类任务。
self.dist_token = nn.Parameter(torch.zeros(1, 1, embed_dim)) if distilled else None
# 定义了一个形状为 (1, 1, embed_dim) 的全零张量,并将其转换为可训练的参数(如果 distilled 为 True)。
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + self.num_tokens, embed_dim))
self.pos_drop = nn.Dropout(p=drop_ratio)
dpr = [x.item() for x in torch.linspace(0, drop_path_ratio, depth)] # stochastic depth decay rule
self.blocks = nn.Sequential(*[
Block(dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop_ratio=drop_ratio, attn_drop_ratio=attn_drop_ratio, drop_path_ratio=dpr[i],
norm_layer=norm_layer, act_layer=act_layer)
for i in range(depth)
])
self.norm = norm_layer(embed_dim)
# Representation layer
if representation_size and not distilled:
self.has_logits = True
self.num_features = representation_size
self.pre_logits = nn.Sequential(OrderedDict([
("fc", nn.Linear(embed_dim, representation_size)),
("act", nn.Tanh())
]))
else:
self.has_logits = False
self.pre_logits = nn.Identity()
# Classifier head(s)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
self.head_dist = None
if distilled:
self.head_dist = nn.Linear(self.embed_dim, self.num_classes) if num_classes > 0 else nn.Identity()
# Weight init
nn.init.trunc_normal_(self.pos_embed, std=0.02)
if self.dist_token is not None:
nn.init.trunc_normal_(self.dist_token, std=0.02)
nn.init.trunc_normal_(self.cls_token, std=0.02)
self.apply(_init_vit_weights)
def forward_features(self, x):
# [B, C, H, W] -> [B, num_patches, embed_dim]
x = self.patch_embed(x) # [B, 196, 768]
# [1, 1, 768] -> [B, 1, 768]
cls_token = self.cls_token.expand(x.shape[0], -1, -1)
if self.dist_token is None:
x = torch.cat((cls_token, x), dim=1) # [B, 197, 768]
else:
x = torch.cat((cls_token, self.dist_token.expand(x.shape[0], -1, -1), x), dim=1)
x = self.pos_drop(x + self.pos_embed)
x = self.blocks(x)
x = self.norm(x)
if self.dist_token is None:
return self.pre_logits(x[:, 0])
else:
return x[:, 0], x[:, 1]
# x[:, 0] 是每个样本的分类标记
# x[:, 1] 是每个样本的蒸馏标记(dist_token)
def forward(self, x):
x = self.forward_features(x)
if self.head_dist is not None:
x, x_dist = self.head(x[0]), self.head_dist(x[1])
if self.training and not torch.jit.is_scripting():
# during inference, return the average of both classifier predictions
return x, x_dist
else:
return (x + x_dist) / 2
else:
x = self.head(x)
return x
def _init_vit_weights(m):
"""
ViT weight initialization
:param m: module
"""
if isinstance(m, nn.Linear):
nn.init.trunc_normal_(m.weight, std=.01)
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out")
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.LayerNorm):
nn.init.zeros_(m.bias)
nn.init.ones_(m.weight)
def vit_base_patch16_224(num_classes: int = 1000):
"""
ViT-Base model (ViT-B/16) from original paper (https://arxiv.org/abs/2010.11929).
ImageNet-1k weights @ 224x224, source https://github.com/google-research/vision_transformer.
weights ported from official Google JAX impl:
链接: https://pan.baidu.com/s/1zqb08naP0RPqqfSXfkB2EA 密码: eu9f
"""
model = VisionTransformer(img_size=224,
patch_size=16,
embed_dim=768,
depth=12,
num_heads=12,
representation_size=None,
num_classes=num_classes)
return model
def vit_base_patch16_224_in21k(num_classes: int = 21843, has_logits: bool = True):
"""
ViT-Base model (ViT-B/16) from original paper (https://arxiv.org/abs/2010.11929).
ImageNet-21k weights @ 224x224, source https://github.com/google-research/vision_transformer.
weights ported from official Google JAX impl:
https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_base_patch16_224_in21k-e5005f0a.pth
"""
model = VisionTransformer(img_size=224,
patch_size=16,
embed_dim=768,
depth=12,
num_heads=12,
representation_size=768 if has_logits else None,
num_classes=num_classes)
return model
def vit_base_patch32_224(num_classes: int = 1000):
"""
ViT-Base model (ViT-B/32) from original paper (https://arxiv.org/abs/2010.11929).
ImageNet-1k weights @ 224x224, source https://github.com/google-research/vision_transformer.
weights ported from official Google JAX impl:
链接: https://pan.baidu.com/s/1hCv0U8pQomwAtHBYc4hmZg 密码: s5hl
"""
model = VisionTransformer(img_size=224,
patch_size=32,
embed_dim=768,
depth=12,
num_heads=12,
representation_size=None,
num_classes=num_classes)
return model
def vit_base_patch32_224_in21k(num_classes: int = 21843, has_logits: bool = True):
"""
ViT-Base model (ViT-B/32) from original paper (https://arxiv.org/abs/2010.11929).
ImageNet-21k weights @ 224x224, source https://github.com/google-research/vision_transformer.
weights ported from official Google JAX impl:
https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_base_patch32_224_in21k-8db57226.pth
"""
model = VisionTransformer(img_size=224,
patch_size=32,
embed_dim=768,
depth=12,
num_heads=12,
representation_size=768 if has_logits else None,
num_classes=num_classes)
return model
def vit_large_patch16_224(num_classes: int = 1000):
"""
ViT-Large model (ViT-L/16) from original paper (https://arxiv.org/abs/2010.11929).
ImageNet-1k weights @ 224x224, source https://github.com/google-research/vision_transformer.
weights ported from official Google JAX impl:
链接: https://pan.baidu.com/s/1cxBgZJJ6qUWPSBNcE4TdRQ 密码: qqt8
"""
model = VisionTransformer(img_size=224,
patch_size=16,
embed_dim=1024,
depth=24,
num_heads=16,
representation_size=None,
num_classes=num_classes)
return model
def vit_large_patch16_224_in21k(num_classes: int = 21843, has_logits: bool = True):
"""
ViT-Large model (ViT-L/16) from original paper (https://arxiv.org/abs/2010.11929).
ImageNet-21k weights @ 224x224, source https://github.com/google-research/vision_transformer.
weights ported from official Google JAX impl:
https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_large_patch16_224_in21k-606da67d.pth
"""
model = VisionTransformer(img_size=224,
patch_size=16,
embed_dim=1024,
depth=24,
num_heads=16,
representation_size=1024 if has_logits else None,
num_classes=num_classes)
return model
def vit_large_patch32_224_in21k(num_classes: int = 21843, has_logits: bool = True):
"""
ViT-Large model (ViT-L/32) from original paper (https://arxiv.org/abs/2010.11929).
ImageNet-21k weights @ 224x224, source https://github.com/google-research/vision_transformer.
weights ported from official Google JAX impl:
https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_large_patch32_224_in21k-9046d2e7.pth
"""
model = VisionTransformer(img_size=224,
patch_size=32,
embed_dim=1024,
depth=24,
num_heads=16,
representation_size=1024 if has_logits else None,
num_classes=num_classes)
return model
def vit_huge_patch14_224_in21k(num_classes: int = 21843, has_logits: bool = True):
"""
ViT-Huge model (ViT-H/14) from original paper (https://arxiv.org/abs/2010.11929).
ImageNet-21k weights @ 224x224, source https://github.com/google-research/vision_transformer.
NOTE: converted weights not currently available, too large for github release hosting.
"""
model = VisionTransformer(img_size=224,
patch_size=14,
embed_dim=1280,
depth=32,
num_heads=16,
representation_size=1280 if has_logits else None,
num_classes=num_classes)
return model
Swin Transformer:
""" Swin Transformer
A PyTorch impl of : `Swin Transformer: Hierarchical Vision Transformer using Shifted Windows`
- https://arxiv.org/pdf/2103.14030
Code/weights from https://github.com/microsoft/Swin-Transformer
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint as checkpoint
import numpy as np
from typing import Optional
def drop_path_f(x, drop_prob: float = 0., training: bool = False):
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
This is the same as the DropConnect impl I created for EfficientNet, etc networks, however,
the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for
changing the layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use
'survival rate' as the argument.
"""
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor_() # binarize
output = x.div(keep_prob) * random_tensor
return output
class DropPath(nn.Module):
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
"""
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path_f(x, self.drop_prob, self.training)
def window_partition(x, window_size: int):
"""
将feature map按照window_size划分成一个个没有重叠的window
Args:
x: (B, H, W, C)
window_size (int): window size(M)
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
# permute: [B, H//Mh, Mh, W//Mw, Mw, C] -> [B, H//Mh, W//Mh, Mw, Mw, C]
# view: [B, H//Mh, W//Mw, Mh, Mw, C] -> [B*num_windows, Mh, Mw, C]
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
def window_reverse(windows, window_size: int, H: int, W: int):
"""
将一个个window还原成一个feature map
Args:
windows: (num_windows*B, window_size, window_size, C)
window_size (int): Window size(M)
H (int): Height of image
W (int): Width of image
Returns:
x: (B, H, W, C)
"""
B = int(windows.shape[0] / (H * W / window_size / window_size))
# view: [B*num_windows, Mh, Mw, C] -> [B, H//Mh, W//Mw, Mh, Mw, C]
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
# permute: [B, H//Mh, W//Mw, Mh, Mw, C] -> [B, H//Mh, Mh, W//Mw, Mw, C]
# view: [B, H//Mh, Mh, W//Mw, Mw, C] -> [B, H, W, C]
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
class PatchEmbed(nn.Module):
"""
2D Image to Patch Embedding
"""
def __init__(self, patch_size=4, in_c=3, embed_dim=96, norm_layer=None):
super().__init__()
patch_size = (patch_size, patch_size)
self.patch_size = patch_size
self.in_chans = in_c
self.embed_dim = embed_dim
self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
_, _, H, W = x.shape
# padding
# 如果输入图片的H,W不是patch_size的整数倍,需要进行padding
pad_input = (H % self.patch_size[0] != 0) or (W % self.patch_size[1] != 0)
if pad_input:
# to pad the last 3 dimensions,
# (W_left, W_right, H_top,H_bottom, C_front, C_back)
x = F.pad(x, (0, self.patch_size[1] - W % self.patch_size[1],
0, self.patch_size[0] - H % self.patch_size[0],
0, 0))
# 下采样patch_size倍
x = self.proj(x)
_, _, H, W = x.shape
# flatten: [B, C, H, W] -> [B, C, HW]
# transpose: [B, C, HW] -> [B, HW, C]
x = x.flatten(2).transpose(1, 2)
x = self.norm(x)
return x, H, W
class PatchMerging(nn.Module):
r""" Patch Merging Layer.
Args:
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x, H, W):
"""
x: B, H*W, C
"""
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
x = x.view(B, H, W, C)
# padding
# 如果输入feature map的H,W不是2的整数倍,需要进行padding
pad_input = (H % 2 == 1) or (W % 2 == 1)
if pad_input:
# to pad the last 3 dimensions, starting from the last dimension and moving forward.
# (C_front, C_back, W_left, W_right, H_top, H_bottom)
# 注意这里的Tensor通道是[B, H, W, C],所以会和官方文档有些不同
x = F.pad(x, (0, 0, 0, W % 2, 0, H % 2))
x0 = x[:, 0::2, 0::2, :] # [B, H/2, W/2, C]
x1 = x[:, 1::2, 0::2, :] # [B, H/2, W/2, C]
x2 = x[:, 0::2, 1::2, :] # [B, H/2, W/2, C]
x3 = x[:, 1::2, 1::2, :] # [B, H/2, W/2, C]
x = torch.cat([x0, x1, x2, x3], -1) # [B, H/2, W/2, 4*C]
x = x.view(B, -1, 4 * C) # [B, H/2*W/2, 4*C]
x = self.norm(x)
x = self.reduction(x) # [B, H/2*W/2, 2*C]
return x
class Mlp(nn.Module):
""" MLP as used in Vision Transformer, MLP-Mixer and related networks
"""
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.drop1 = nn.Dropout(drop)
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop2 = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop1(x)
x = self.fc2(x)
x = self.drop2(x)
return x
class WindowAttention(nn.Module):
r""" Window based multi-head self attention (W-MSA) module with relative position bias.
It supports both of shifted and non-shifted window.
Args:
dim (int): Number of input channels.
window_size (tuple[int]): The height and width of the window.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(self, dim, window_size, num_heads, qkv_bias=True, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # [Mh, Mw]
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = head_dim ** -0.5
# define a parameter table of relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # [2*Mh-1 * 2*Mw-1, nH]
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w], indexing="ij")) # [2, Mh, Mw]
coords_flatten = torch.flatten(coords, 1) # [2, Mh*Mw]
# [2, Mh*Mw, 1] - [2, 1, Mh*Mw]
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # [2, Mh*Mw, Mh*Mw]
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # [Mh*Mw, Mh*Mw, 2]
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # [Mh*Mw, Mh*Mw]
self.register_buffer("relative_position_index", relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
nn.init.trunc_normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask: Optional[torch.Tensor] = None):
"""
Args:
x: input features with shape of (num_windows*B, Mh*Mw, C)
mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
"""
# [batch_size*num_windows, Mh*Mw, total_embed_dim]
B_, N, C = x.shape
# qkv(): -> [batch_size*num_windows, Mh*Mw, 3 * total_embed_dim]
# reshape: -> [batch_size*num_windows, Mh*Mw, 3, num_heads, embed_dim_per_head]
# permute: -> [3, batch_size*num_windows, num_heads, Mh*Mw, embed_dim_per_head]
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
# [batch_size*num_windows, num_heads, Mh*Mw, embed_dim_per_head]
q, k, v = qkv.unbind(0) # make torchscript happy (cannot use tensor as tuple)
# transpose: -> [batch_size*num_windows, num_heads, embed_dim_per_head, Mh*Mw]
# @: multiply -> [batch_size*num_windows, num_heads, Mh*Mw, Mh*Mw]
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
# relative_position_bias_table.view: [Mh*Mw*Mh*Mw,nH] -> [Mh*Mw,Mh*Mw,nH]
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1)
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # [nH, Mh*Mw, Mh*Mw]
attn = attn + relative_position_bias.unsqueeze(0)
if mask is not None:
# mask: [nW, Mh*Mw, Mh*Mw]
nW = mask.shape[0] # num_windows
# attn.view: [batch_size, num_windows, num_heads, Mh*Mw, Mh*Mw]
# mask.unsqueeze: [1, nW, 1, Mh*Mw, Mh*Mw]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
# @: multiply -> [batch_size*num_windows, num_heads, Mh*Mw, embed_dim_per_head]
# transpose: -> [batch_size*num_windows, Mh*Mw, num_heads, embed_dim_per_head]
# reshape: -> [batch_size*num_windows, Mh*Mw, total_embed_dim]
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class SwinTransformerBlock(nn.Module):
r""" Swin Transformer Block.
Args:
dim (int): Number of input channels.
num_heads (int): Number of attention heads.
window_size (int): Window size.
shift_size (int): Shift size for SW-MSA.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float, optional): Stochastic depth rate. Default: 0.0
act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, num_heads, window_size=7, shift_size=0,
mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(
dim, window_size=(self.window_size, self.window_size), num_heads=num_heads, qkv_bias=qkv_bias,
attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x, attn_mask):
H, W = self.H, self.W
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C)
# pad feature maps to multiples of window size
# 把feature map给pad到window size的整数倍
pad_l = pad_t = 0
pad_r = (self.window_size - W % self.window_size) % self.window_size
pad_b = (self.window_size - H % self.window_size) % self.window_size
x = F.pad(x, (0, 0, pad_l, pad_r, pad_t, pad_b))
_, Hp, Wp, _ = x.shape
# cyclic shift
if self.shift_size > 0:
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
else:
shifted_x = x
attn_mask = None
# partition windows
x_windows = window_partition(shifted_x, self.window_size) # [nW*B, Mh, Mw, C]
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # [nW*B, Mh*Mw, C]
# W-MSA/SW-MSA
attn_windows = self.attn(x_windows, mask=attn_mask) # [nW*B, Mh*Mw, C]
# merge windows
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C) # [nW*B, Mh, Mw, C]
shifted_x = window_reverse(attn_windows, self.window_size, Hp, Wp) # [B, H', W', C]
# reverse cyclic shift
if self.shift_size > 0:
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
else:
x = shifted_x
if pad_r > 0 or pad_b > 0:
# 把前面pad的数据移除掉
x = x[:, :H, :W, :].contiguous()
x = x.view(B, H * W, C)
# FFN
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class BasicLayer(nn.Module):
"""
A basic Swin Transformer layer for one stage.
Args:
dim (int): Number of input channels.
depth (int): Number of blocks.
num_heads (int): Number of attention heads.
window_size (int): Local window size.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
"""
def __init__(self, dim, depth, num_heads, window_size,
mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, downsample=None, use_checkpoint=False):
super().__init__()
self.dim = dim
self.depth = depth
self.window_size = window_size
self.use_checkpoint = use_checkpoint
self.shift_size = window_size // 2
# build blocks
self.blocks = nn.ModuleList([
SwinTransformerBlock(
dim=dim,
num_heads=num_heads,
window_size=window_size,
shift_size=0 if (i % 2 == 0) else self.shift_size,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
drop=drop,
attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
norm_layer=norm_layer)
for i in range(depth)])
# patch merging layer
if downsample is not None:
self.downsample = downsample(dim=dim, norm_layer=norm_layer)
else:
self.downsample = None
def create_mask(self, x, H, W):
# calculate attention mask for SW-MSA
# 保证Hp和Wp是window_size的整数倍
Hp = int(np.ceil(H / self.window_size)) * self.window_size
Wp = int(np.ceil(W / self.window_size)) * self.window_size
# 拥有和feature map一样的通道排列顺序,方便后续window_partition
img_mask = torch.zeros((1, Hp, Wp, 1), device=x.device) # [1, Hp, Wp, 1]
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size) # [nW, Mh, Mw, 1]
mask_windows = mask_windows.view(-1, self.window_size * self.window_size) # [nW, Mh*Mw]
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2) # [nW, 1, Mh*Mw] - [nW, Mh*Mw, 1]
# [nW, Mh*Mw, Mh*Mw]
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
return attn_mask
def forward(self, x, H, W):
attn_mask = self.create_mask(x, H, W) # [nW, Mh*Mw, Mh*Mw]
for blk in self.blocks:
blk.H, blk.W = H, W
if not torch.jit.is_scripting() and self.use_checkpoint:
x = checkpoint.checkpoint(blk, x, attn_mask)
else:
x = blk(x, attn_mask)
if self.downsample is not None:
x = self.downsample(x, H, W)
H, W = (H + 1) // 2, (W + 1) // 2
return x, H, W
class SwinTransformer(nn.Module):
r""" Swin Transformer
A PyTorch impl of : `Swin Transformer: Hierarchical Vision Transformer using Shifted Windows` -
https://arxiv.org/pdf/2103.14030
Args:
patch_size (int | tuple(int)): Patch size. Default: 4
in_chans (int): Number of input image channels. Default: 3
num_classes (int): Number of classes for classification head. Default: 1000
embed_dim (int): Patch embedding dimension. Default: 96
depths (tuple(int)): Depth of each Swin Transformer layer.
num_heads (tuple(int)): Number of attention heads in different layers.
window_size (int): Window size. Default: 7
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4
qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True
drop_rate (float): Dropout rate. Default: 0
attn_drop_rate (float): Attention dropout rate. Default: 0
drop_path_rate (float): Stochastic depth rate. Default: 0.1
norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.
patch_norm (bool): If True, add normalization after patch embedding. Default: True
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False
"""
def __init__(self, patch_size=4, in_chans=3, num_classes=1000,
embed_dim=96, depths=(2, 2, 6, 2), num_heads=(3, 6, 12, 24),
window_size=7, mlp_ratio=4., qkv_bias=True,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,
norm_layer=nn.LayerNorm, patch_norm=True,
use_checkpoint=False, **kwargs):
super().__init__()
self.num_classes = num_classes
self.num_layers = len(depths)
self.embed_dim = embed_dim
self.patch_norm = patch_norm
# stage4输出特征矩阵的channels
self.num_features = int(embed_dim * 2 ** (self.num_layers - 1))
self.mlp_ratio = mlp_ratio
# split image into non-overlapping patches
self.patch_embed = PatchEmbed(
patch_size=patch_size, in_c=in_chans, embed_dim=embed_dim,
norm_layer=norm_layer if self.patch_norm else None)
self.pos_drop = nn.Dropout(p=drop_rate)
# stochastic depth
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
# build layers
self.layers = nn.ModuleList()
for i_layer in range(self.num_layers):
# 注意这里构建的stage和论文图中有些差异
# 这里的stage不包含该stage的patch_merging层,包含的是下个stage的
layers = BasicLayer(dim=int(embed_dim * 2 ** i_layer),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
window_size=window_size,
mlp_ratio=self.mlp_ratio,
qkv_bias=qkv_bias,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
norm_layer=norm_layer,
downsample=PatchMerging if (i_layer < self.num_layers - 1) else None,
use_checkpoint=use_checkpoint)
self.layers.append(layers)
self.norm = norm_layer(self.num_features)
self.avgpool = nn.AdaptiveAvgPool1d(1)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
nn.init.trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward(self, x):
# x: [B, L, C]
x, H, W = self.patch_embed(x)
x = self.pos_drop(x)
for layer in self.layers:
x, H, W = layer(x, H, W)
x = self.norm(x) # [B, L, C]
x = self.avgpool(x.transpose(1, 2)) # [B, C, 1]
x = torch.flatten(x, 1)
x = self.head(x)
return x
def swin_tiny_patch4_window7_224(num_classes: int = 1000, **kwargs):
# trained ImageNet-1K
# https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_tiny_patch4_window7_224.pth
model = SwinTransformer(in_chans=3,
patch_size=4,
window_size=7,
embed_dim=96,
depths=(2, 2, 6, 2),
num_heads=(3, 6, 12, 24),
num_classes=num_classes,
**kwargs)
return model
def swin_small_patch4_window7_224(num_classes: int = 1000, **kwargs):
# trained ImageNet-1K
# https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_small_patch4_window7_224.pth
model = SwinTransformer(in_chans=3,
patch_size=4,
window_size=7,
embed_dim=96,
depths=(2, 2, 18, 2),
num_heads=(3, 6, 12, 24),
num_classes=num_classes,
**kwargs)
return model
def swin_base_patch4_window7_224(num_classes: int = 1000, **kwargs):
# trained ImageNet-1K
# https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window7_224.pth
model = SwinTransformer(in_chans=3,
patch_size=4,
window_size=7,
embed_dim=128,
depths=(2, 2, 18, 2),
num_heads=(4, 8, 16, 32),
num_classes=num_classes,
**kwargs)
return model
def swin_base_patch4_window12_384(num_classes: int = 1000, **kwargs):
# trained ImageNet-1K
# https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window12_384.pth
model = SwinTransformer(in_chans=3,
patch_size=4,
window_size=12,
embed_dim=128,
depths=(2, 2, 18, 2),
num_heads=(4, 8, 16, 32),
num_classes=num_classes,
**kwargs)
return model
def swin_base_patch4_window7_224_in22k(num_classes: int = 21841, **kwargs):
# trained ImageNet-22K
# https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window7_224_22k.pth
model = SwinTransformer(in_chans=3,
patch_size=4,
window_size=7,
embed_dim=128,
depths=(2, 2, 18, 2),
num_heads=(4, 8, 16, 32),
num_classes=num_classes,
**kwargs)
return model
def swin_base_patch4_window12_384_in22k(num_classes: int = 21841, **kwargs):
# trained ImageNet-22K
# https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window12_384_22k.pth
model = SwinTransformer(in_chans=3,
patch_size=4,
window_size=12,
embed_dim=128,
depths=(2, 2, 18, 2),
num_heads=(4, 8, 16, 32),
num_classes=num_classes,
**kwargs)
return model
def swin_large_patch4_window7_224_in22k(num_classes: int = 21841, **kwargs):
# trained ImageNet-22K
# https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_large_patch4_window7_224_22k.pth
model = SwinTransformer(in_chans=3,
patch_size=4,
window_size=7,
embed_dim=192,
depths=(2, 2, 18, 2),
num_heads=(6, 12, 24, 48),
num_classes=num_classes,
**kwargs)
return model
def swin_large_patch4_window12_384_in22k(num_classes: int = 21841, **kwargs):
# trained ImageNet-22K
# https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_large_patch4_window12_384_22k.pth
model = SwinTransformer(in_chans=3,
patch_size=4,
window_size=12,
embed_dim=192,
depths=(2, 2, 18, 2),
num_heads=(6, 12, 24, 48),
num_classes=num_classes,
**kwargs)
return model


















 1343
1343

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











