







 这篇博客详细介绍了如何使用PyTorch构建自定义数据集类`MyDataSet`,包括读取数据、处理数据预处理(如归一化、尺寸调整)、以及计算数据集的均值和标准差。在数据加载器`DataLoader`的帮助下,可以批量处理数据,其中`__getitem__`方法用于获取单个样本,`__len__`方法返回数据集长度。博客还强调了`torch.tensor`和`Tensor([target])`之间的区别,并展示了如何从数据加载器中获取批量数据并进行进一步的统计计算。
这篇博客详细介绍了如何使用PyTorch构建自定义数据集类`MyDataSet`,包括读取数据、处理数据预处理(如归一化、尺寸调整)、以及计算数据集的均值和标准差。在数据加载器`DataLoader`的帮助下,可以批量处理数据,其中`__getitem__`方法用于获取单个样本,`__len__`方法返回数据集长度。博客还强调了`torch.tensor`和`Tensor([target])`之间的区别,并展示了如何从数据加载器中获取批量数据并进行进一步的统计计算。
注意以下代码中:
返回的是单张图片数据。
而

返回得到的 x 是batch_size的图片矩阵。
target 和 y同理。
在img和x的类型方面,img 是<class 'numpy.ndarray'>,img.dtype报错。 ,而 x 是 <class 'torch.Tensor'>,数据是 torch.float64。
import torch
import os
import numpy as np
from PIL import Image
from torch.utils.data import Dataset, DataLoader
import matplotlib.pyplot as plt
class MyDataSet(Dataset):
def __init__(self, path):
# print("__init__",path)
"""根据路径获得数据集"""
self.path = path
"""读取路径下的所有文件"""
self.dataset = os.listdir(self.path)
# 均值和方差的求解过程下面会交代
self.mean = [0.4878, 0.4545, 0.4168]
self.std = [0.2623, 0.2555, 0.2577]
def __len__(self):
# print("__len__",len(self.dataset))
"""获取数据集的长度"""
return len(self.dataset)
def __getitem__(self, index):
"""根据索引获得数据集"""
# print(index)
# print("__getitem__",self.dataset[index])
# 获得数据的标签
name = self.dataset[index]
# 数据集的文件名为i.j.jpeg, 这个标签的第i个位置如果是0表示猫,1则表示狗,第j个位置是图片的个数
name_list = name.split(".")
target = int(name_list[0])
# 这里需要注意,tensor(target) 和Tensor([target])的区别,否则在one-hot解码的时候会出现错误
target = torch.tensor(target)
"""数据预处理"""
# 打开图片
img = Image.open(os.path.join(self.path, name))
# 设置图片大小
# img = np.resize(img, (3, 10, 10))
# 归一化,先将图片转化为一个矩阵,然后除以255
img = np.array(img) / 255
# # 去均值
# img = (img - self.mean) / self.std
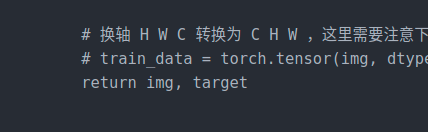
# 换轴 H W C 转换为 C H W ,这里需要注意下,其实我们可以不这么处理,在前面设置图片大小的时候设置为3 * 100 * 100 的就可以。
# train_data = torch.tensor(img, dtype=torch.float32).permute(2, 0, 1)
return img, target
if __name__ == '__main__':
"""注意:求均值和标准差时,首先把上面去均值的那一行代码注释了"""
dataset = MyDataSet(r'./cat_dog/img')
# print("70周年")
# 求均值,将DataLoader进行打包,这里batch_size的数量应该是训练图片的总数
data_loader = DataLoader(dataset=dataset, batch_size=120, shuffle=True)
# print("万岁")
# input()
# 将data_loader作为一个迭代器进行运算,这里面包含了输入数据和标签,所以后面取第0个位置的数,也就是取输入数据
for x,y in data_loader:
# print("hello world")
# input()
print(x.size(),y.size(),x[0][0])
# plt.imshow(x[0][0])
# plt.show()
# print(x,y)
# input()
# print(data_loader)
# input()
# print("china 100 birthday")
a=next(iter(data_loader))[0]
input()
data = next(iter(data_loader))[0]
# print(data,data.size())
# 这里图片N(每批的数量) C(通道数) H(高) W(宽) 几个维度,求的.0是通道层面的均值,所以dim=(0, 2, 3)
mean = torch.mean(data, dim=(0, 2, 3))
std = torch.std(data, dim=(0, 2, 3))
print(mean)
print(std)


















 2378
2378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











