



小模型迁移到昇腾怎么才能比 NVIDIA 更快?一次真实踩坑复盘告诉你答案
小模型迁移到昇腾,可能遇到速度变慢的情况,一般会以为是硬件差异导致的,尤其是和 NVIDIA 的 4090、A100 这种 GPU 比。此次迁移一个不到 1B 的小模型后,才发现可能是因为没正确调优。
1. 迁移后推理从 1 秒变成 1.5 秒
基于 LLM 框架,在 NVIDIA 机器上推理该小模型时,单次推理耗时约 1 秒,当迁移到昇腾(300I Duo)后测出来,推理 + to(cpu)需要1.5s,从打印出来看上去 to(cpu) 占了将近一半。
观察代码进行初步推测,可能是HostBound 或者 NPU→CPU 的下发速度拖慢了。先试了异步 to(cpu),提前 sync和手动减少拷贝次数等方法尝试解决问题,
……几乎都没有明显改善,只能采取更细致的方法。
2. 使用Profile
简单的调整无法解决问题,便转向使用 Ascend PyTorch Profiler 进行深入的性能分析。通过在代码中插入 torch_npu.profiler.profile() 接口,能够采集推理过程中每个阶段的时间数据。为我们提供了关于推理过程瓶颈的详细视图,尤其是在NPU → CPU 数据传输这一环节。
2.1 实际 Profiling 过程与结果验证(Notebook 环境)
说明:由于本地无昇腾硬件,本次实验基于云电脑提供的 Ascend Notebook 环境完成。该环境中仅 Notebook 实例具备 NPU 访问能力,因此模型运行与 Profiling 均在 Notebook 内完成,而 MindStudio Insight 用于离线分析 trace 文件。
2.1.1 Ascend NPU 环境确认
在 Notebook 中通过 torch_npu 接口确认当前实例已成功识别 Ascend NPU 设备:
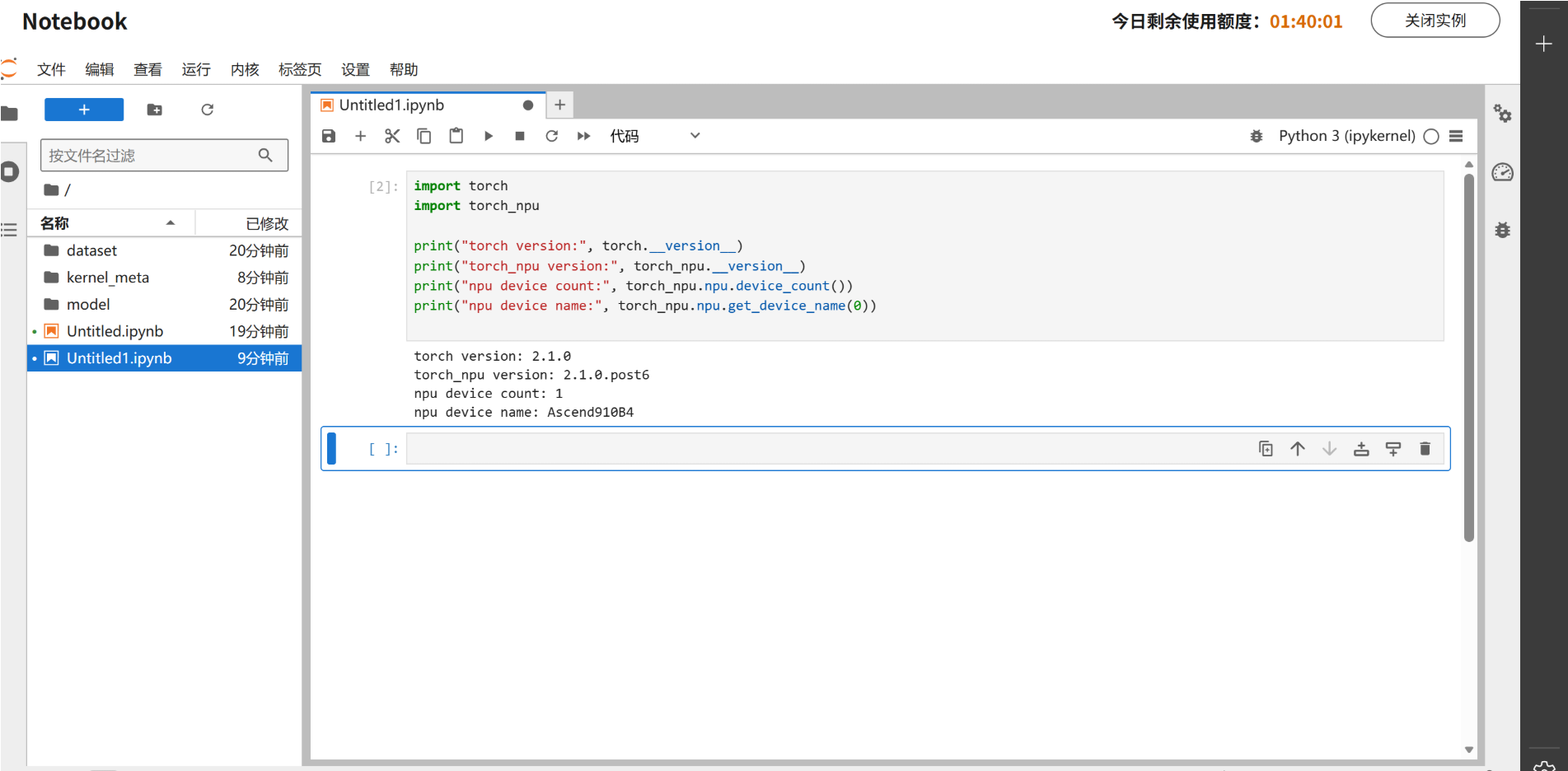
2.1.2 Profiler 数据采集
在 Notebook 中使用 torch_npu.profiler.profile 对一次最小计算任务进行 Profiling,用于验证 CPU/NPU 调度与 Timeline 行为。

这里有几个需要注意的点:
当只有一个 step 时,调用 prof.step() 反而可能采集不到数据,此时需要将其删除;必要时可在 stop 前额外插入一次同步
torch_npu.npu.synchronize()让 CPU/NPU 的 timeline 对齐
否则会以为“Profiler 不工作”,但实际上是采集策略没踩对点。
在 Profiling 结束后,Notebook 中成功生成 trace_view.json 文件,为后续 Timeline 分析提供基础数据。
3. 把 trace_view.json 丢进 MindStudio查看
先去昇腾社区下载MindStudioInsight社区版
打开软件后
将生成的 trace_view.json import 进入 (有些人打开json文件时可能遇到直接在网页打开的情况,这是语言特性,只需要按ctrl+s就可以保存了)MindStudio Insight(离线分析,无需 NPU),在 Timeline 视图中观察 CPU 与 NPU 的执行关系。
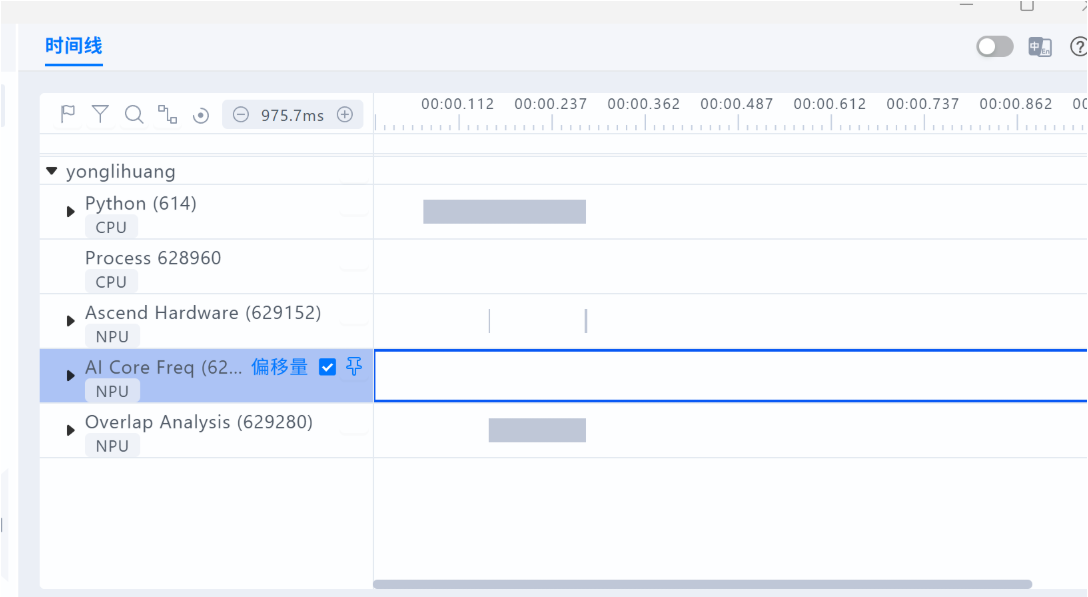
从 Timeline 中可以观察到CPU 首先发起算子调度,NPU 随后异步开始执行计算任务。在同步点处,CPU 与 NPU 基本同时结束。而在轻量 workload 场景下,由于算子数量与执行时间有限,AI Core 频率与 Ascend Hardware 的活跃区间较短,属于正常现象。
需要说明的是,该示例为最小计算任务,并非完整大模型推理场景,因此 Timeline 形态与真实模型存在差异,但 CPU/NPU 的调度关系与等待行为具有一致的分析意义。
可以发现,to(cpu) 本身只消耗了非常少的时间,真正的耗时来自模型推理尚未结束这一阶段。也就是说之前看到的to(cpu)是个假象。真正发生的是
模型推理(NPU 上)尚未完成 → to(cpu) 必须等待未完成的推理结束 → 看起来像 to(cpu) 很慢
在 Notebook 的最小 Profiling 示例中,也可以观察到类似的 CPU/NPU 异步行为:CPU 的时间感知往往无法反映 NPU 上的真实执行进度,只有通过 Timeline 才能确认等待关系的真实来源。
这也解释了为什么前文提到的异步 to(cpu)、提前 sync 以及减少拷贝次数等方法并未起作用。因为打印时间是 CPU 层的感知,而 NPU 的真实执行进度你看不到(除非 profile)。
4. 优化推理
定位到问题后,接下来就分成两条路:
方案 A:使用昇腾专门给小模型优化过的框架
对于小模型,昇腾已经有专门做过优化的推理框架:
-
torchair
https://gitee.com/ascend/torchair
它主要是把小模型的 kernel 调度、流水线结构、算子拆分做了深度优化,因为
小模型没有大模型那种巨量算子来填满 NPU,所以需要更细粒度的 pipeline 调度来减少碎片、减少 HostBound、减少 bubble。
它的 latency 效率高于pytorch的默认实现方式。
方案 B:PyTorch手工调优
这是此次主要路线,核心优化项有两个:
1)避免npu等待cpu
通过设置环境变量 TASK_QUEUE_ENABLE=2,优化计算任务与调度之间的流水线,减少 HostBound,使 NPU 能够连续执行计算任务,不会出现长时间的等待空洞。
export TASK_QUEUE_ENABLE=2它能优化计算与调度的 pipeline,减少 HostBound, 让 NPU 连续执行 Kernel,不出现等待执行的空洞
很像 CUDA Graph,但作用机制不同,这2个策略旧版本无效,需要将驱动固件和cann包升级到较新的版本。
2)禁用在线算子编译,避免每次都重新编 JIT Kernel
在 PyTorch 中,JIT 编译会导致首次执行时推理延迟翻倍。禁用 JIT 编译后,所有推理任务的内核将直接调用,避免了每次执行时都需要重新编译的开销。
torch_npu.npu.set_compile_mode(jit_compile=False)
torch_npu.npu.config.allow_internal_format = False如果你的模型有很多动态 shape 或第一次执行需要 JIT,会导致延迟直接翻倍。
禁掉之后,全流程的 Kernel 调用稳定很多。
5. 演示结果
完成以上优化后,重新测了一次:
| 平台 | 推理时延 |
|---|---|
| NVIDIA(1B 小模型) | ~1.0 s |
| Ascend(迁移前) | ~1.5 s |
| Ascend(优化后) | 0.7 s |
可以看出,在完成针对 HostBound 与在线编译问题的调优后,整体推理性能得到明显改善。尽管本文中的 Notebook 示例并未直接复现完整模型的端到端时延对比,但通过 Profiler 与 Timeline 的分析可以确认,HostBound、流水线空洞以及在线算子编译确实是小模型迁移到昇腾后常见的性能瓶颈来源。
在实际项目中,通过开启 TASK_QUEUE 并禁用 JIT 编译,上述问题可以明显缓解,推理时延也能显著下降。


















 17万+
17万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











