




 本文详细介绍了一个基于Python的Scrapy框架实现的51job职位信息爬虫项目。项目包括了从网页抓取数据、数据清洗、数据存储到MySQL数据库的全过程。爬虫通过解析网页获取职位名称、公司名、地址、薪资等信息,并使用动态代理和自动请求头轮换来规避反爬虫策略。数据存储部分实现了薪资范围的转换和城市信息的提取。
本文详细介绍了一个基于Python的Scrapy框架实现的51job职位信息爬虫项目。项目包括了从网页抓取数据、数据清洗、数据存储到MySQL数据库的全过程。爬虫通过解析网页获取职位名称、公司名、地址、薪资等信息,并使用动态代理和自动请求头轮换来规避反爬虫策略。数据存储部分实现了薪资范围的转换和城市信息的提取。
1、项目结构如下图所示,说明如下:
源代码工程文件下载地址:https://download.youkuaiyun.com/download/nosprings/12047437
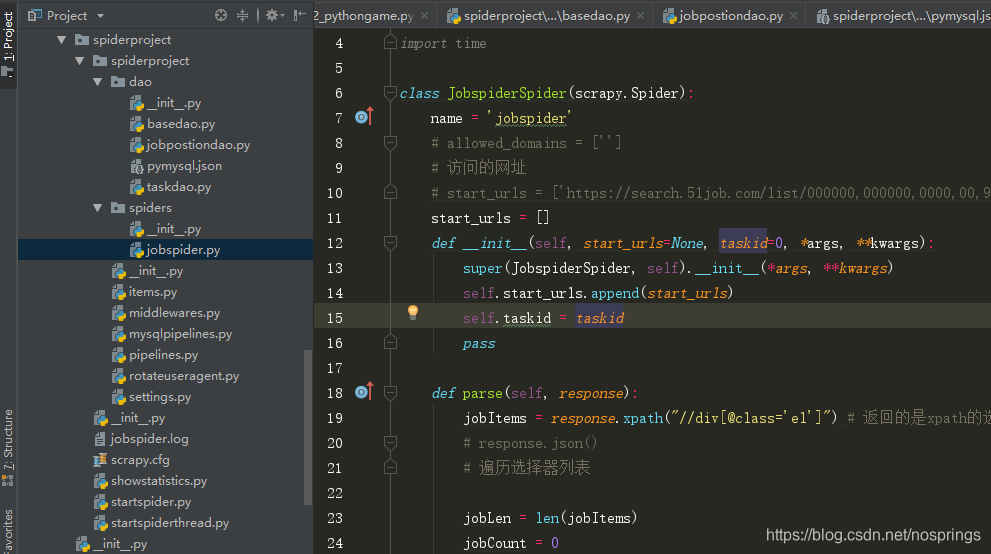
spiderproject------项目工程目录
—spiderproject------爬虫主项目目录
——dao ------ 数据库访问封装
———basedao.py ------ 数据库封装基础类
# 引入pymysql
import pymysql
import json
import logging
import os
class BaseDao(): # DAO: database access object
def __init__(self, configFile='pymysql.json'):
self.__connection = None
self.__cursor = None
self.__config = json.load(open(os.path.dirname(__file__) + os.sep + configFile, 'r')) # 通过json配置获得数据的连接配置信息
print(self.__config)
pass
# 获取数据库连接的方法
def getConnection(self):
# 当有连接对象时,直接返回连接对象
if self.__connection:
return self.__connection
# 否则通过建立新的连接对象
try:
self.__connection = pymysql.connect(**self.__config)
return self.__connection
except pymysql.MySQLError as e:
print("Exception:" + str(e))
pass
pass
# 用于执行sql语句的通用方法 # sql注入
def execute(self, sql, params):
try:
self.__cursor = self.getConnection().cursor()
# result返回sql语句影响到的条数
if params: # 带参数sql语句
result = self.__cursor.execute(sql, params)
else: # 不带参数sql语句
result = self.__cursor.execute(sql)
return result
except (pymysql.MySQLError, pymysql.DatabaseError, Exception) as e:
print("出现数据库访问异常:" + str(e))
self.rollback()
pass
finally:
pass
pass
def fetch(self):
if self.__cursor:
return self.__cursor.fetchall()
pass
def commit(self):
if self.__connection:
self.__connection.commit()
pass
def rollback(self):
if self.__connection:
self.__connection.rollback()
pass
# 返回最后的自增主键
def getLastRowId(self):
if self.__cursor:
return self.__cursor.lastrowid
pass
def close(self):
if self.__cursor:
self.__cursor.close()
if self.__connection:
self.__connection.close()
pass
pass
———jobpositiondao.py ------ 职位数据操作基本类文件
from .basedao import BaseDao
# 定义一个操作职位数据的数据库访问类
class JobPositionDao(BaseDao):
def __init__(self):
super().__init__()
pass
# 向数据库插入职位信息
def create(self, params):
sql = "insert into job_position (job_position, job_company, job_address, job_salary, job_date" \
",job_taskid, job_lowsalary,job_highsalary,job_meansalary,job_city) values (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s)"
result = self.execute(sql, params)
lastRowId = self.getLastRowId()
self.commit()
return result, lastRowId
pass
def createDetail(self, params):
sql = "insert into job_position_detail (detail_desciption, detail_positionid)"\
"values (%s, %s)"
result = self.execute(sql, params) # ORM
self.commit()
return result
pass
def findPositionClassify(self):
sql = 'select avg(job_meansalary), job_taskid, task_title from job_position, job_collect_task '+ \
'where job_position.job_taskid=job_collect_task.task_id group by job_taskid, task_title'
result = self.execute(sql, params=None)
self.commit()
return self.fetch()
pass
def findCityPositionClassify(self):
sql = 'select avg(t1.job_meansalary) as m, t1.job_taskid, t2.task_title ,t1.job_city from '+ \
'job_position t1 left join job_collect_task t2 on t1.job_taskid = t2.task_id '+ \
'group by job_taskid, job_city, t2.task_title order by t1.job_taskid asc, m desc'
result = self.execute(sql, params=None)
self.commit()
return self.fetch()
pass
pass———pymysql.json ------ 数据库访问基本配置文件
{"host":"127.0.0.1", "user":"root","password":"root", "database":"db_job_data", "port":3306, "charset":"utf8"}———taskdao.py ------ 任务操作数据库操作
from .basedao import BaseDao
class TaskDao(BaseDao):
def create(self, params):
sql = "insert into job_collect_task (task_title, task_url) values (%s, %s)"
result = self.execute(sql, params)
lastRowId = self.getLastRowId()
self.commit()
self.close()
return result, lastRowId
pass
pass——spiders ------ 爬虫主文件目录
———jobspider.py ------ 爬虫主程序文件
# -*- coding: utf-8 -*-
import scrapy
from day22.spiderproject.spiderproject.items import SpiderprojectItem
import time
class JobspiderSpider(scrapy.Spider):
name = 'jobspider'
# allowed_domains = ['']
# 访问的网址
# start_urls = ['https://search.51job.com/list/000000,000000,0000,00,9,99,Python,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=']
start_urls = []
def __init__(self, start_urls=None, taskid=0, *args, **kwargs):
super(JobspiderSpider, self).__init__(*args, **kwargs)
self.start_urls.append(start_urls)
self.taskid = taskid
pass
def parse(self, response):
jobItems = response.xpath("//div[@class='el']") # 返回的是xpath的选择器列表
# response.json()
# 遍历选择器列表
jobLen = len(jobItems)
jobCount = 0
nextURL = response.xpath('//li[@class="bk"]/a/@href').extract() # 取下一页的地址
nextText = response.xpath('//li[@class="bk"]/a/text()').extract()
# print(nextURL)
realURL = ""
if nextURL and nextText[-1].strip() == '下一页':
realURL = response.urljoin(nextURL[-1])
pass
for jobItem in jobItems:
jobCount += 1
sItem = SpiderprojectItem()
sItem['taskId'] = self.taskid
# 解析职位名称
position = jobItem.xpath("p/span/a/text()")
if position:
sItem['jobPosition'] = position.extract()[0].strip()
pass
positionDetail = jobItem.xpath("p[@class='t1 ']/span/a/@href") # 返回的是选择器
# 解析公司名称
jobCompany = jobItem.xpath("span[@class='t2']/a/text()")
if jobCompany:
sItem['jobCompany'] = jobCompany.extract()[0].strip()
pass
# 解析地址
jobAddress = jobItem.xpath("span[@class='t3']/text()")
if jobAddress:
sItem['jobAddress'] = jobAddress.extract()[0].strip()
pass
# 解析信息范围
jobSalary = jobItem.xpath("span[@class='t4']/text()")
if jobSalary:
sItem['jobSalary'] = jobSalary.extract()[0].strip()
pass
# 解析分布日期
jobDate = jobItem.xpath("span[@class='t5']/text()")
if jobDate:
sItem['jobDate'] = jobDate.extract()[0].strip()
pass
if position and jobCompany and jobAddress and jobSalary and jobDate and positionDetail:
detailURL = positionDetail.extract()[0]
sItem['nextURL'] = realURL
yield scrapy.Request(url=detailURL, callback=self.parse_detail, meta={'item':sItem, 'jobLen':jobLen, 'jobCount':jobCount}, dont_filter=True) # dont_filter是否去重复地址
pass
pass
pass
# 定义爬取详情页的方法
def parse_detail(self, response):
sItem = response.meta['item']
jobLen = response.meta['jobLen']
jobCount = response.meta['jobCount']
detailData = response.xpath("//div[@class='bmsg job_msg inbox']")
print('detailData:', detailData)
if detailData:
contents = detailData.xpath('//p/text()') # 返回当前选择器
ct = ""
if contents:
for temp in contents.extract():
if temp.strip() == "" or temp.strip() == "/":
continue
ct += temp + "\n"
pass
sItem['jobDetail'] = ct
yield sItem # 保顺序
pass
# 判断当前页是否爬取完成了,完成就继续爬取下一页
if jobLen == jobCount:
if sItem['nextURL']:
yield scrapy.Request(sItem['nextURL'], self.parse, dont_filter=False)
pass
pass
pass——items.py ------ scrapy框架用来封装数据的实体类
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
# 数据封装的实体类
class SpiderprojectItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
jobPosition = scrapy.Field()
jobCompany = scrapy.Field()
jobSalary = scrapy.Field()
jobAddress = scrapy.Field()
jobDate = scrapy.Field()
jobDetailURL = scrapy.Field()
nextURL = scrapy.Field()
jobDetail = scrapy.Field()
taskId = scrapy.Field()
pass
——middlewares.py ------ scrapy框架的中间件配置(例如下载器等)
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
from scrapy import signals
class SpiderprojectSpiderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the spider middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
# Called for each response that goes through the spider
# middleware and into the spider.
# Should return None or raise an exception.
return None
def process_spider_output(self, response, result, spider):
# Called with the results returned from the Spider, after
# it has processed the response.
# Must return an iterable of Request, dict or Item objects.
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
# Called when a spider or process_spider_input() method
# (from other spider middleware) raises an exception.
# Should return either None or an iterable of Request, dict
# or Item objects.
pass
def process_start_requests(self, start_requests, spider):
# Called with the start requests of the spider, and works
# similarly to the process_spider_output() method, except
# that it doesn’t have a response associated.
# Must return only requests (not items).
for r in start_requests:
yield r
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
class SpiderprojectDownloaderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
return None
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
——mysqlpiplines.py ------ 自定义用来向mysql数据库写入数据的管道
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
from day22.spiderproject.spiderproject.dao.jobpostiondao import JobPositionDao
class SpiderMySqlPipeline(object):
def process_item(self, item, spider):
# 重用数据连接
jobPositionDao = JobPositionDao()
try:
jobAddress = item['jobAddress']
jobSalary = item['jobSalary']
lowSalary = 0
highSalary = 0
meanSalary = 0
# 获取地址信息中的城市信息
jobCity = jobAddress.split('-')[0]
# 处理薪资数据:1、判断单位
if jobSalary.endswith('万/月'):
jobSalary = jobSalary.replace('万/月', '')
if jobSalary.find('-'):
salaryArray = jobSalary.split('-')
lowSalary = float(salaryArray[0]) * 10000
highSalary = float(salaryArray[1]) * 10000
pass
else:
lowSalary = highSalary = float(jobSalary) * 10000
meanSalary = (lowSalary + highSalary)/2
pass
elif jobSalary.endswith('千/月'):
jobSalary = jobSalary.replace('千/月', '')
if jobSalary.find('-'):
salaryArray = jobSalary.split('-')
lowSalary = float(salaryArray[0]) * 1000
highSalary = float(salaryArray[1]) * 1000
pass
else:
lowSalary = highSalary = float(jobSalary) * 1000
meanSalary = (lowSalary + highSalary)/2
pass
elif jobSalary.endswith('万/年'):
jobSalary = jobSalary.replace('万/年', '')
if jobSalary.find('-'):
salaryArray = jobSalary.split('-')
lowSalary = float(salaryArray[0]) * 10000 / 12
highSalary = float(salaryArray[1]) * 10000 / 12
pass
else:
lowSalary = highSalary = float(jobSalary) * 10000 / 12
meanSalary = (lowSalary + highSalary)/2
pass
elif jobSalary.endswith('元/天'):
jobSalary = jobSalary.replace('元/天', '')
if jobSalary.find('-'):
salaryArray = jobSalary.split('-')
lowSalary = float(salaryArray[0]) * 22
highSalary = float(salaryArray[1]) * 22
pass
else:
lowSalary = highSalary = float(jobSalary) * 22
meanSalary = (lowSalary + highSalary) / 2
pass
else:
return
result, lastRowId = jobPositionDao.create((item['jobPosition'], item['jobCompany'], item['jobAddress'], item['jobSalary'],
item['jobDate'], item['taskId'], lowSalary, highSalary, meanSalary, jobCity))
if result:
jobPositionDao.createDetail((item['jobDetail'], lastRowId))
pass
except Exception as e:
print(e)
finally:
jobPositionDao.close()
return item
——piplines.py ------ scrapy自动生成的管道
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
class SpiderprojectPipeline(object):
def process_item(self, item, spider):
print("通过管道输出数据")
print(item['jobPosition'])
print(item['jobCompany'])
print(item['jobSalary'])
print(item['jobAddress'])
print(item['jobDate'])
print(item['jobDetail'])
return item
——rotateuseragent.py ------ scrapy框架来设置构造http请求头的代理
# -*- coding: utf-8 -*-"
# 导入random模块
import random
# 导入useragent用户代理模块中的UserAgentMiddleware类
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware
# RotateUserAgentMiddleware类,继承 UserAgentMiddleware 父类
# 作用:创建动态代理列表,随机选取列表中的用户代理头部信息,伪装请求。
# 绑定爬虫程序的每一次请求,一并发送到访问网址。
# 发爬虫技术:由于很多网站设置反爬虫技术,禁止爬虫程序直接访问网页,
# 因此需要创建动态代理,将爬虫程序模拟伪装成浏览器进行网页访问。
class RotateUserAgentMiddleware(UserAgentMiddleware):
def __init__(self, user_agent=''):
self.user_agent = user_agent
def process_request(self, request, spider):
#这句话用于随机轮换user-agent
ua = random.choice(self.user_agent_list)
if ua:
# 输出自动轮换的user-agent
print(ua)
request.headers.setdefault('User-Agent', ua)
# the default user_agent_list composes chrome,I E,firefox,Mozilla,opera,netscape
# for more user agent strings,you can find it in http://www.useragentstring.com/pages/useragentstring.php
# 编写头部请求代理列表
user_agent_list = [\
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"\
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",\
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",\
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",\
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",\
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",\
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",\
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",\
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",\
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",\
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",\
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",\
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",\
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",\
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",\
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",\
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",\
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]——settings.py ------ 爬虫主配置文件
# -*- coding: utf-8 -*-
# Scrapy settings for spiderproject project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'spiderproject'
SPIDER_MODULES = ['spiderproject.spiders']
NEWSPIDER_MODULE = 'spiderproject.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'spiderproject (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 1
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
SPIDER_MIDDLEWARES = {
'spiderproject.middlewares.SpiderprojectSpiderMiddleware': 543,
}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'spiderproject.middlewares.SpiderprojectDownloaderMiddleware': 543,
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': None, # 这一行是取消框架自带的useragent
'spiderproject.rotateuseragent.RotateUserAgentMiddleware': 400
}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'spiderproject.pipelines.SpiderprojectPipeline': 300,
'spiderproject.mysqlpipelines.SpiderMySqlPipeline': 301, # 配置自己的管道
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
# 配置日志新的输出
LOG_LEVEL = 'ERROR'
LOG_FILE = 'jobspider.log'
—scrapy.cfg ------ 工程配置文件
# Automatically created by: scrapy startproject
#
# For more information about the [deploy] section see:
# https://scrapyd.readthedocs.io/en/latest/deploy.html
[settings]
default = spiderproject.settings
[deploy]
#url = http://localhost:6800/
project = spiderproject
—startspider.py ------ 爬虫启动文件
# 此脚本是爬虫启动脚本
from scrapy.cmdline import execute
from day22.spiderproject.spiderproject.dao.taskdao import TaskDao
# 启动爬虫
td = TaskDao()
result, taskId = td.create(('Python职位数据采集','https://search.51job.com/list/000000,000000,0000,00,9,99,Python,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare='))
if result:
execute(['scrapy', 'crawl', 'jobspider',
'-a', 'start_urls=https://search.51job.com/list/000000,000000,0000,00,9,99,Python,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=',
'-a', 'taskid=' + str(taskId)])
pass
#
# result, taskId = td.create(('Java职位数据采集','https://search.51job.com/list/000000,000000,0000,00,9,99,java,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare='))
# if result:
# execute(['scrapy', 'crawl', 'jobspider',
# '-a', 'start_urls=https://search.51job.com/list/000000,000000,0000,00,9,99,java,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=',
# '-a', 'taskid=' + str(taskId)])
# pass
'''
execute(['scrapy', 'crawl', 'jobspider',
'-a', 'start_urls=https://search.51job.com/list/000000,000000,0000,00,9,99,%25E4%25BA%25BA%25E5%25B7%25A5%25E6%2599%25BA%25E8%2583%25BD,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=',
'-a', 'taskid=2',
'-a', 'paramName=paramValue'])
'''2、数据库结构如下:
CREATE DATABASE IF NOT EXISTS `db_job_data` /*!40100 DEFAULT CHARACTER SET utf8 */;
USE `db_job_data`;
-- MySQL dump 10.13 Distrib 5.7.17, for Win64 (x86_64)
--
-- Host: localhost Database: db_job_data
-- ------------------------------------------------------
-- Server version 5.7.22
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */;
/*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */;
/*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */;
/*!40101 SET NAMES utf8 */;
/*!40103 SET @OLD_TIME_ZONE=@@TIME_ZONE */;
/*!40103 SET TIME_ZONE='+00:00' */;
/*!40014 SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0 */;
/*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */;
/*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */;
/*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */;
--
-- Table structure for table `job_collect_task`
--
DROP TABLE IF EXISTS `job_collect_task`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!40101 SET character_set_client = utf8 */;
CREATE TABLE `job_collect_task` (
`task_id` int(11) NOT NULL AUTO_INCREMENT,
`task_title` varchar(128) DEFAULT NULL,
`task_url` varchar(1024) DEFAULT NULL,
`task_date` datetime DEFAULT CURRENT_TIMESTAMP,
`task_total` int(11) DEFAULT NULL,
`task_state` int(11) DEFAULT '1',
PRIMARY KEY (`task_id`)
) ENGINE=InnoDB AUTO_INCREMENT=13 DEFAULT CHARSET=utf8;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Table structure for table `job_dept`
--
DROP TABLE IF EXISTS `job_dept`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!40101 SET character_set_client = utf8 */;
CREATE TABLE `job_dept` (
`dept_id` int(11) NOT NULL,
`dept_name` varchar(45) DEFAULT NULL,
`dept_parentid` int(11) DEFAULT NULL,
PRIMARY KEY (`dept_id`),
UNIQUE KEY `dept_name_UNIQUE` (`dept_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Table structure for table `job_position`
--
DROP TABLE IF EXISTS `job_position`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!40101 SET character_set_client = utf8 */;
CREATE TABLE `job_position` (
`job_id` int(11) NOT NULL AUTO_INCREMENT,
`job_position` varchar(512) DEFAULT NULL,
`job_company` varchar(512) DEFAULT NULL,
`job_address` varchar(512) DEFAULT NULL,
`job_salary` varchar(45) DEFAULT NULL,
`job_date` varchar(45) DEFAULT NULL,
`job_taskid` int(11) DEFAULT NULL,
`job_degree` varchar(45) DEFAULT NULL,
`job_expyear` varchar(45) DEFAULT NULL,
`job_lowsalary` float DEFAULT NULL,
`job_highsalary` float DEFAULT NULL,
`job_meansalary` float DEFAULT NULL,
`job_city` varchar(128) DEFAULT NULL,
PRIMARY KEY (`job_id`)
) ENGINE=InnoDB AUTO_INCREMENT=2093 DEFAULT CHARSET=utf8;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Table structure for table `job_position_detail`
--
DROP TABLE IF EXISTS `job_position_detail`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!40101 SET character_set_client = utf8 */;
CREATE TABLE `job_position_detail` (
`detail_id` int(11) NOT NULL AUTO_INCREMENT,
`detail_desciption` longtext,
`detail_positionid` int(11) DEFAULT NULL,
PRIMARY KEY (`detail_id`)
) ENGINE=InnoDB AUTO_INCREMENT=2093 DEFAULT CHARSET=utf8;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Table structure for table `job_user`
--
DROP TABLE IF EXISTS `job_user`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!40101 SET character_set_client = utf8 */;
CREATE TABLE `job_user` (
`USER_ID` int(11) NOT NULL AUTO_INCREMENT,
`USER_NAME` varchar(32) NOT NULL,
`USER_PWD` varchar(512) NOT NULL,
`USER_AGE` int(11) DEFAULT NULL,
`USER_SEX` int(11) DEFAULT NULL,
`USER_QQ` int(11) DEFAULT NULL,
`USER_CELLPHONE` varchar(20) DEFAULT NULL,
`USER_MONEY` float DEFAULT NULL,
`USER_STATUS` int(11) DEFAULT '1',
`USER_PIC` varchar(128) DEFAULT NULL,
`USER_INTRO` longtext,
`USER_BIRTH` datetime DEFAULT NULL,
`USER_DEPTID` int(11) DEFAULT NULL,
`USER_ROLE` int(11) DEFAULT '1',
PRIMARY KEY (`USER_ID`),
UNIQUE KEY `USER_NAME_UNIQUE` (`USER_NAME`)
) ENGINE=InnoDB AUTO_INCREMENT=3595 DEFAULT CHARSET=utf8;
/*!40101 SET character_set_client = @saved_cs_client */;
/*!40103 SET TIME_ZONE=@OLD_TIME_ZONE */;
/*!40101 SET SQL_MODE=@OLD_SQL_MODE */;
/*!40014 SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS */;
/*!40014 SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS */;
/*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */;
/*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS */;
/*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION */;
/*!40111 SET SQL_NOTES=@OLD_SQL_NOTES */;
-- Dump completed on 2019-12-23 16:50:55

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









