







 本文介绍了使用PyTorch进行数据预处理的步骤,包括处理缺失值、使用get_dummies进行one-hot编码,以及将数据转换为张量格式。在数据预处理阶段,对缺失值进行了插值处理,并使用fillna()函数用列均值填充。之后,利用get_dummies将类别特征转换为二进制表示。最后,将预处理后的数据转换为张量,为后续的线性神经网络模型做准备。
本文介绍了使用PyTorch进行数据预处理的步骤,包括处理缺失值、使用get_dummies进行one-hot编码,以及将数据转换为张量格式。在数据预处理阶段,对缺失值进行了插值处理,并使用fillna()函数用列均值填充。之后,利用get_dummies将类别特征转换为二进制表示。最后,将预处理后的数据转换为张量,为后续的线性神经网络模型做准备。
day01
b站:https://space.bilibili.com/1567748478/channel/seriesdetail?sid=358497
教材:https://zh-v2.d2l.ai/chapter_preface/index.html#sec-code
代码注解:https://blog.youkuaiyun.com/shakalakaphd/category_10318255_2.html
03 安装
我没有按照他的来 我使用的是anaconda
1)anaconda prompt
2) cd 到下载好的jupyter记事本位置
3)jupyter notebook
即可
04 数据操作+数据预处理
(沐神没告诉我在jupyter记事本的位置…尬住
数据操作:notebooks/pytorch/chapter_preliminaries/ndarray.ipynb
数据预处理:notebooks/pytorch/chapter_preliminaries/pandas.ipynb
数据预处理
读取数据集
下载torch很慢
→ pip install -i https://pypi.tuna.tsinghua.edu.cn/simple torch

我保存在了./data1/house_tiny.csv
import os
os.makedirs(os.path.join('.', 'data1'), exist_ok=True)
data_file = os.path.join('.', 'data1', 'house_tiny.csv')
with open(data_file, 'w') as f:
f.write('NumRooms,Alley,Price\n') # 列名
f.write('NA,Pave,127500\n') # 每行表示一个数据样本
f.write('2,NA,106000\n')
f.write('4,NA,178100\n')
f.write('NA,NA,140000\n')
os.makedirs 创建目录
os.path.join 路径拼接函数

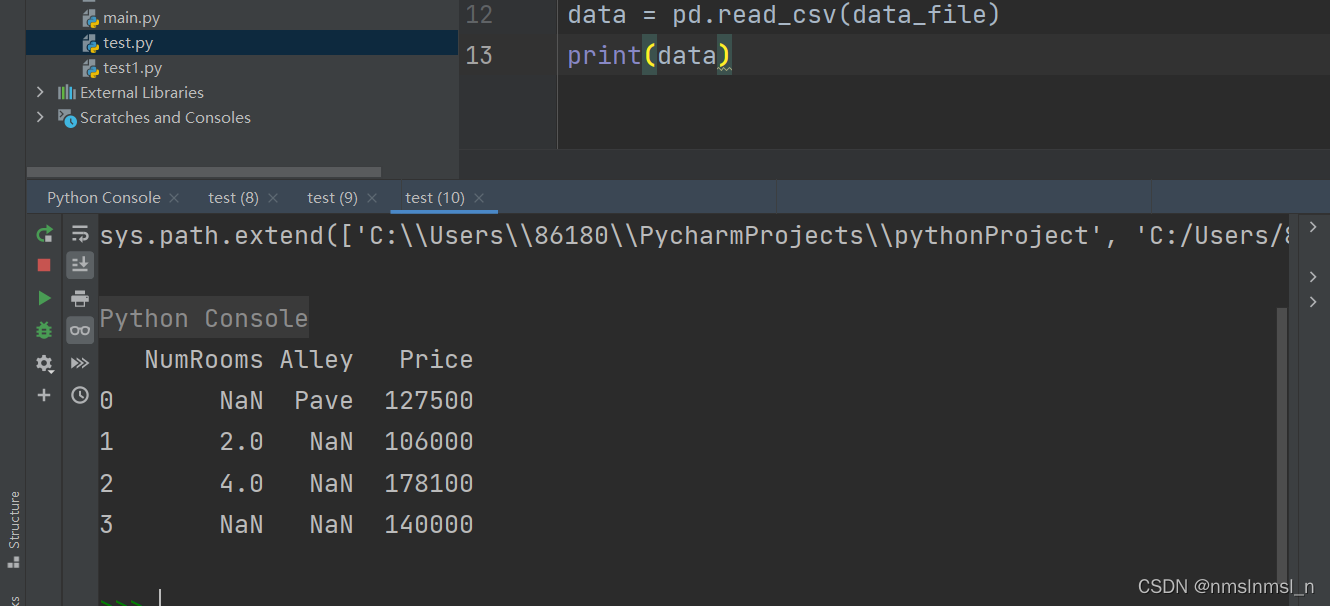
处理缺失值
注意,“NaN”项代表缺失值。 [为了处理
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 477
477

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









