





目录
6 应用范式:从 RAG 到 Many-Shot ICL 与 Agent
6.2 Many-Shot ICL 与 Context Engineering
1 引言
大模型发展到 2025 年,参数规模已经不再是唯一的“卷点”,上下文长度正在变成新的战场。从最早 512 / 2K 的 Transformer,到 8K 的第一代 GPT-3 / Llama,再到 32K、128K,如今 OpenAI、Google、Anthropic 等头部厂商已经把上下文窗口推到了 百万级甚至 200 万 token,并围绕长上下文做了专门的评测基准和工程优化。Gemini 系列在 Google Cloud 的 Vertex AI 中,将长上下文作为产品卖点之一,Gemini 1.5 Pro 的上下文窗口已经在云端 GA 到 2M tokens,而且在 Needle-In-A-Haystack(NIAH)这类检索任务上能实现接近 100% 的召回率。(Google Cloud Documentation)
OpenAI 这边,一方面在 GPT-4.1 上就已经推出了 1M token 上下文窗口,同时在 2025 年 11 月又发布了 GPT-5.1 系列,包括 GPT-5.1 Chat / GPT-5.1 Instant / GPT-5.1 Thinking,以及面向代码场景的 GPT-5.1-Codex / GPT-5.1-Codex-Max,其中 Codex 方向的模型上下文窗口可达 400K tokens,并通过“compaction”机制在接近上限时自动裁剪历史,从而在“名义上有限、实际接近无限”的时间跨度上跑完大型工程任务。(OpenAI)
中国与开源阵营也没闲着:阿里系的 Qwen3 全系列支持 32K 乃至 256K 级别的上下文,其中 Qwen3-32B 原生 32,768 tokens,并通过 YaRN 等 RoPE 扩展技术在实验中验证了 131,072 tokens 的长度;而 Qwen3-Next-80B-A3B 默认上下文就拉到了 256K tokens。(Hugging Face) Meta 的 Llama 3.1 / 3.2 系列则将开源阵营主流模型的上下文提升到 128K,并衍生出各种利用 RoPE 重标定实现 1M+ 长度的社区版本。(Meta AI)
可以看到,“从 32K 到百万 token”已不再是论文里画饼,而是真实产品和开源模型正在跑的场景。学术界也开始系统梳理长上下文技术路线:例如 2024 年 IJCAI 上关于扩展上下文长度技术的综述系统总结了长度外推、注意力近似、注意力-自由结构(如 Mamba / SSM)、模型压缩与硬件友好 Transformer 等一整套方法体系;而 2025 年又出现了专门聚焦长上下文语言模型(LCLM)的综合 survey,以及围绕 many-shot in-context learning、NoLiMa 等新基准的研究,标志着“长上下文”已经从工程技巧升级成系统研究方向。(IJCAI)
本文将围绕“长上下文建模突破:从 32K 到百万 token 的技术路径”展开,从相关工作综述、基础原理出发,重点分析几个关键技术路线(RoPE/ALiBi 等位置编码外推、注意力近似与混合架构、缓存与压缩、系统层的 RAG + 长上下文协同),并结合 GPT-5.1、Gemini 3、Claude Sonnet 4、Qwen3、Llama 3.1、DeepSeek-V3.1 等最新模型的数据,对比它们在上下文窗口、长上下文评测表现和成本上的差异,最后讨论在实际系统中如何设计“能用得起、用得好”的百万级上下文应用。
2 相关工作综述
2.1 主流长上下文模型与上下文窗口规模
为了避免再出现“版本落后”的问题,这里直接给出截至 2025-12-02 公开资料中,几家头部模型在“长上下文”上的关键参数(只列代表型号,不做穷举)。
表 1 主流长上下文模型的上下文窗口与定位
| 模型家族与版本 | 典型模型 / 接口 | 最大上下文窗口(官方 / 文档) | 典型应用定位(官方宣传与生态) |
|---|---|---|---|
| OpenAI GPT-5 系列 | GPT-5.1 Chat / GPT-5.1 Thinking | 128K tokens(Chat 版本文档)(OpenAI 平台) | 通用对话、复杂推理,ChatGPT 默认推理内核 |
| GPT-5.1-Codex / GPT-5.1-Codex-Max | 400K tokens 上下文窗口,并支持基于 compaction 的多窗口长程工作(OpenAI 平台) | 大型代码库重构、长时 Agent、多轮工具调用 | |
| 早期 GPT-4.1 | 1M tokens(API 与媒体报道)(The Verge) | 率先把闭源 LLM 上下文打到百万级的代表之一 | |
| Google Gemini 系列 | Gemini 3 Pro / Ultra(2025-11 发布) | 延续 Gemini 家族标准:1M 级上下文;云端典型通过 1.5 / 2.5 实现 1–2M 上下文(Google Cloud Documentation) | 全面多模态推理,强化“Deep Think”模式与工具调用 |
| Gemini 1.5 Pro / 2.5 Pro | 默认 1M,Vertex AI 上 GA 的 2M tokens 上下文窗口(Google Cloud Documentation) | 真正意义上的“2M 长上下文”生产可用版本 | |
| Anthropic Claude 系列 | Claude Sonnet 4 / 4.5 | 标准 200K,上线 1M tokens 上下文 beta(需特殊 header)(Claude 开发平台) | 兼顾推理与性价比的主力型号,长上下文侧重代码与企业文档 |
| Claude Opus 4.1 | 200K(主打推理质量)(IntuitionLabs) | 高端推理任务,成本高但精度优 | |
| 阿里 Qwen 系列 | Qwen3-32B | 原生 32,768 tokens,使用 YaRN 验证到 131,072 tokens(Hugging Face) | 开源 32K 长上下文基线,社区大量二次扩展 |
| Qwen3-Next-80B-A3B | 默认上下文 256K tokens(官方博客)(qwen.ai) | 面向企业 / 云侧推理,强调长上下文与工具调用 | |
| Meta Llama 系列 | Llama 3.1 405B / 70B / 8B | 官方上下文 128K tokens(Meta AI) | 开源阵营主力长上下文模型,生产级 128K |
| Llama3-Gradient(社区) | 通过 RoPE 调参训练,将 8B 上下文扩展到约 1,040K tokens(Ollama) | 展示“极少微调 + RoPE 调整”实现 1M 级上下文的可能性 | |
| DeepSeek 系列 | DeepSeek-V3 / V3.1 / V3.2-Exp | 官方宣称在 NIAH 测试中对 128K 上下文保持良好性能(Hugging Face) | 强调 128K 上下文与极低价格,主攻长上下文 RAG 与推理 |
| 其他 | 如 Jamba、Grok4 等 | 多数在 128K–256K 区间(如 Jamba 使用混合注意力 + 状态空间实现 256K)(hackernoon.com) | 通过架构创新换取更长上下文与更低显存占用 |
从表 1 可以看出,32K 已经只是最低标准,128K 成为“主流水平”,而 1M–2M 则是闭源巨头之间的新高地。更微妙的是,上下文窗口不再只是“一个数字”,背后包含了不同的技术路线:有的通过位置编码外推硬顶到 100 万,有的通过多窗口+缓存+压缩把“逻辑上下文”延伸到远超单窗口的范围。
2.2 长上下文评测基准与实验现状
仅仅把 context_length 参数调大并不意味着模型真的能在长文里“看得见、记得住、用得好”。因此 2023–2025 年间围绕长上下文衍生出了一系列评测基准和实验范式,其中比较有代表性的是:
-
Needle-In-A-Haystack(NIAH):在极长文本中埋入“针”,要求模型在回答问题时准确检索;Google 在 NIAH 上展示了 Gemini 1.5 Pro 在 1M tokens 上仍能保持超过 99.7% 的 needle 召回率。(Google Cloud)
-
NoLiMa:针对 NIAH 的“字面匹配”局限,设计了问题和 needle 之间几乎没有词面重叠、需要模型做语义对齐与推断的长上下文 benchmark,被用来系统比较 128K 以上上下文模型的能力。(arXiv)
-
Many-Shot In-Context Learning:Google 和学界在 many-shot ICL 上系统研究了在长上下文中“塞进几百上千个示例”的效果,发现对于分类与摘要任务,示例数量远大于少样本时能显著提升性能,而对复杂推理和翻译提升有限。(arXiv)
-
长上下文 RAG 基准:如 Databricks 对 Llama 3.1 与其他模型在长文档 RAG 任务上的系统测试,表明即便上下文扩大到 128K,模型在实际检索-推理链路中仍然会受到“位置衰减”和 Prompt 结构的强烈影响。(Databricks)
表 2 代表性长上下文评测基准与关注点
表头:主要长上下文评测基准概览
| 基准 / 论文 | 核心任务设计 | 上下文长度范围 | 主要考察维度 |
|---|---|---|---|
| Needle-In-A-Haystack | 在长文本中埋入单个或多个“针”,问答时需检索 needle | 从 32K 扩展到 1M+,Gemini 等支持 2M 场景(Google Cloud) | 检索精度、位置鲁棒性,对长距离信息的记忆能力 |
| RULER / NIAH 扩展 | 多 needle + 干扰 needle,增加歧义与难度 | 128K–1M | 在复杂检索与对抗 noise 情况下的召回与精度 |
| NoLiMa | 问题与 needle 几乎无词面重叠,需语义推断(arXiv) | 128K+ | 长上下文语义检索与推理能力,而非单纯字符串匹配 |
| Many-Shot ICL 基准 | 在 prompts 中塞入几百-上千个示例,考察 many-shot ICL 效果(arXiv) | 32K–1M | 上下文承载学习的能力、对示例顺序敏感性、长上下文 scaling law |
| 长上下文 RAG 评测 | 大量文档+检索+生成链路的端到端评测(Databricks) | 通常 32K–256K | 检索-阅读链路整体质量、延迟与成本的平衡 |
| 工业 NIAH / N-shot 厂商测试 | 如 Gemini 1.5 Pro 的 1M / 2M NIAH 实验、Claude Sonnet 4 的 1M 报告(Google Cloud Documentation) | 1M–2M | 商业产品在超长上下文下的真实表现 |
综上,社区已经从“能撑多长”转向“在长上下文里能做什么”:能不能 reliably 找到 needle、能不能从上千个示例中学到规律、在 100+ 页 PDF 或一整个代码库上做端到端分析时,是否会出现“context rot”(随着长度增加性能反而下降)等问题。(Medium)
3 基础知识与原理
3.1 上下文窗口、本质瓶颈与成本
在标准 Transformer 里,注意力复杂度是 O(n²),上下文长度从 32K 拉到 1M,理论上算力需求是 1000² / 32² 级别的爆炸式增长,这也是为何长上下文很长时间只是“小规模实验证明可行”,而难以真正商用。
另一方面,从业务视角看,上下文长度不仅是算力问题,更是钱的问题:以 2025 年公开的主流 API 定价为例,IntuitionLabs 对 OpenAI、Gemini、Claude、Grok、DeepSeek 等模型的 2025 年价格做了系统对比,其中 GPT-5 类模型在高性能配置下的输出价格可以到每百万 token 10 美元,而 Gemini 2.5 Pro 的价格区间在每百万输入 1.25–2.5 美元、输出 10–15 美元之间;Anthropic 的 Claude Opus 4.1 输入 15 美元 / 1M、输出 75 美元 / 1M,Sonnet 4 级别则在 3 / 15 美元;DeepSeek V3.2-Exp 则把 128K 上下文模型的价格压到输入 0.28 / 输出 0.42 美元 / 1M。(IntuitionLabs)
如果你把 100 万 tokens 的上下文 + 10 万 tokens 的输出塞给 Opus 或 GPT-5.1-Codex,一次调用的成本可以轻松到几美元甚至几十美元;而在 DeepSeek、Gemini Flash 或 GPT-5 nano 上则可能不到 1 美元甚至几美分,这直接决定了哪些方案只适合“科研 demo”,哪些可以跑进生产。
因此,一切关于长上下文的技术讨论,本质都要回到两个问题:
-
如何在计算上可承受(通过结构、算法和系统层优化,避免纯粹 n² 爆炸);
-
如何在经济上可承受(在给定预算下,选哪种模型、用多大的窗口,才是“够用又不浪费”的点)。
3.2 长上下文建模的技术挑战
长上下文带来的挑战可以 roughly 拆成三类:
-
数值与泛化问题:标准的绝对位置编码 / RoPE 等在预训练长度之外容易出现数值振荡或“感知失真”,导致模型虽然理论上能接受长序列,却在远端位置几乎“不认得”内容。相关工作提出了 NTK-aware RoPE scaling、Position Interpolation、YaRN 等方法试图在频域或几何空间上对位置信息做平滑外推。(arXiv)
-
计算与内存问题:当长度从 32K 拉到 1M 时,即便使用 FlashAttention、MQA / GQA,在单卡内存和延迟上的压力仍然巨大,这推动了如混合注意力 + 状态空间(如 Jamba)、压缩注意力、Block-wise Attention 等架构的出现。(hackernoon.com)
-
行为与评测问题:长上下文下模型容易出现“近因偏置”(偏向最近的信息)、“context rot”(随着长度增加,性能先升后降)、以及对 needle 位置、顺序的过高敏感等现象,这些问题在 NoLiMa、many-shot ICL 等基准中被系统分析。(arXiv)
3.3 技术路线总体分类
综合 2024–2025 年的 survey 和工程实践,长上下文技术大致可以归为四条主线:(IJCAI)
表 3 长上下文技术路线与代表方法
表头:长上下文技术路线分类
| 技术路线 | 代表方法 / 系统 | 核心思路(极简概括) | 典型代表模型 / 论文 |
|---|---|---|---|
| 长度外推(Position / RoPE) | RoPE scaling、NTK-aware RoPE、Position Interpolation、YaRN、Cable 等 | 不改架构,通过重标定 / 插值位置编码,让模型在远超预训练长度上保持数值稳定与语义一致 | Llama3-Gradient 1M+、Qwen3 YaRN 实验、Cable(Context-aware Biases)、“Extending Context Up to 3M Tokens”等(Ollama) |
| 注意力近似与低秩结构 | Sparse / Local Attention、Linear Attention、Longformer / BigBird 系列 | 通过稀疏、低秩或核方法降低复杂度,使长上下文推理可行,多见于专用长文模型 | 早期长文 BERT / Longformer 系列,部分混合架构模型综述(IJCAI) |
| 混合架构(Attention + SSM / Memory) | Mamba、Jamba 混合模型 | 将部分层替换为状态空间层或记忆模块,利用线性复杂度处理长序列,再与注意力层结合 | Jamba 256K 上下文工程实践、Mamba 系列工作(hackernoon.com) |
| 系统层与外部记忆 | RAG、Context Caching、Compaction、Memory KV Store | 接受上下文窗口有限这一现实,通过向量检索、缓存、自动裁剪等手段在“逻辑层面”延长模型记忆 | GPT-5.1-Codex-Max 的 compaction、Claude / Gemini / DeepSeek 的缓存与 RAG 实践(OpenAI) |
后面几章会围绕这四条路线展开更细的工程分析。
4 从 32K 到百万 token:位置编码与长度外推
4.1 RoPE 与长度外推的演化
自从旋转位置编码(RoPE)成为主流 LLM 标配之后,几乎所有 2023–2025 年的长上下文工作都绕不开“如何把 RoPE 用到超长序列”这个问题。RoPE 在频域上给位置编码赋予了“相对位移可计算”的优点,但在超过训练长度太多时,旋转频率会导致不同位置的向量在高频区域不断绕圈,产生 aliasing。这时简单把最大长度从 8K 改到 1M 是没有意义的,模型会“数值晕车”。
NTK-aware RoPE scaling 通过分析 Transformer 与无限宽网络的等价关系,在频域上重新标定 RoPE 的频率,使得在更长的序列上依然能保持稳定的注意力模式;Position Interpolation 则通过将长序列坐标压缩映射到训练区间,从而以非线性方式“挤进”原有位置编码里;YaRN 等方法更进一步,将 RoPE 的半径与频率动态调整,试图在不同层、不同头上采用分段的扩展策略。(arXiv)
Qwen3-32B 与 Llama3-Gradient 等模型的实验表明,在只用极少量额外训练(不到总预训练数据 0.01%)的情况下,配合合适的 RoPE 调整,可以把原本 8K–32K 的模型可靠地推到 100K–1M 上下文,并在 NIAH 等任务上保持相当不错的 needle recall。这种“轻微再训练 + RoPE 重标定”的路线,是目前开源社区把主流模型向 1M 逼近的主流手法。(Hugging Face)
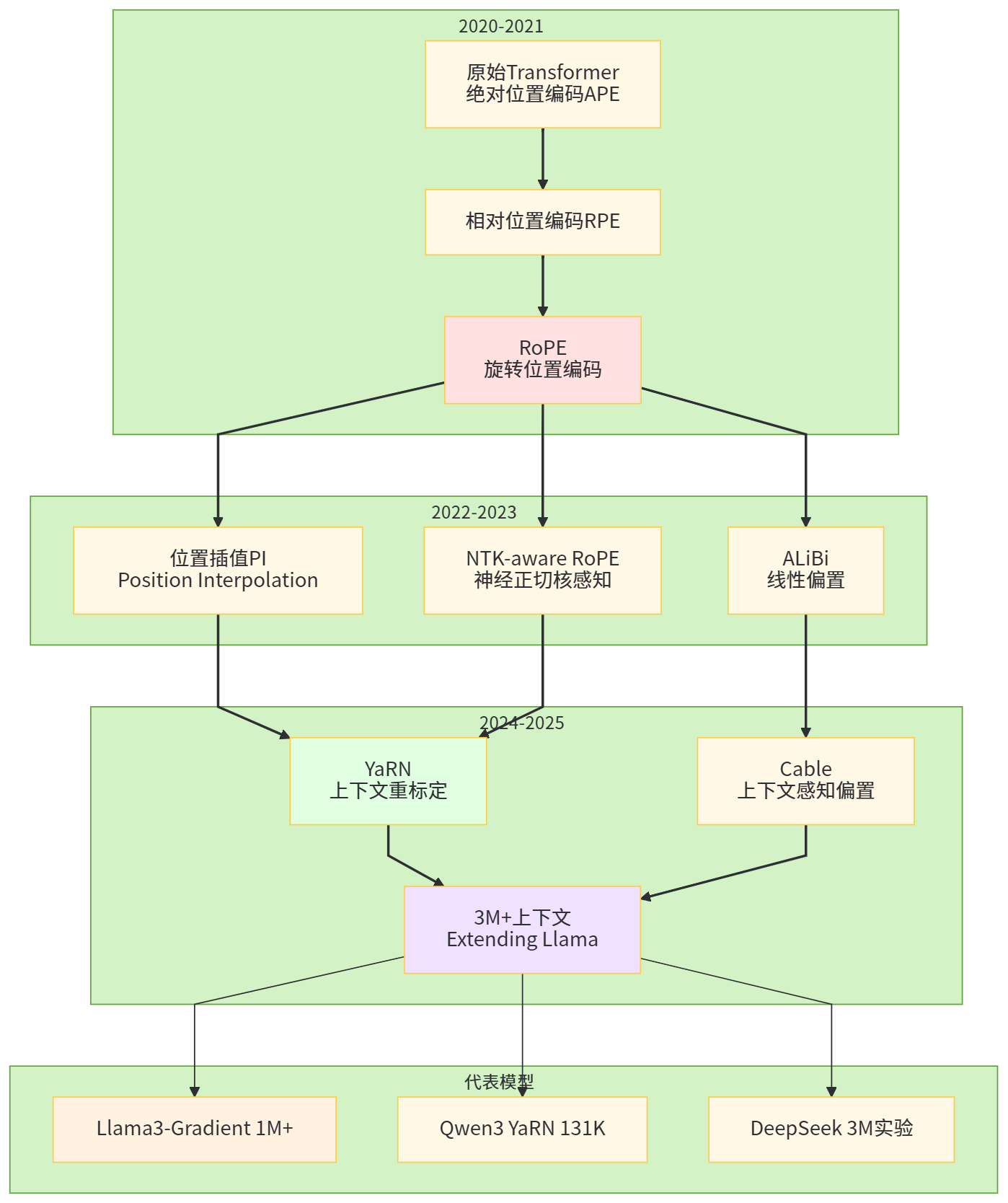
图 1 长度外推技术演化示意图
4.2 Cable 等新一代长度外推方法
2025 年出现的 Cable(Context-aware Biases for Length Extrapolation)在 ALiBi 的基础上提出对不同注意力头学习不同的长度偏置斜率,而不是用固定线性函数,这提供了一种“在训练中主动学会如何外推”的思路。相比于纯手工设定的线性偏置,Cable 让模型在训练中自动为不同 heads 建立对长程依赖的偏好,从而在 4–8 倍于训练长度时仍能保持较好的性能。(arXiv)
与此同时,像《Extending Language Model Context Up to 3 Million Tokens》这样的工作,尝试把 Llama3.2 这类 128K 预训练上下文的模型,通过分阶段的 RoPE 调整和少量再训练,将有效上下文扩展到 256K 乃至 3M tokens,并通过注意力矩阵可视化展示在不同调整策略下模型注意力模式的变化。(arXiv)
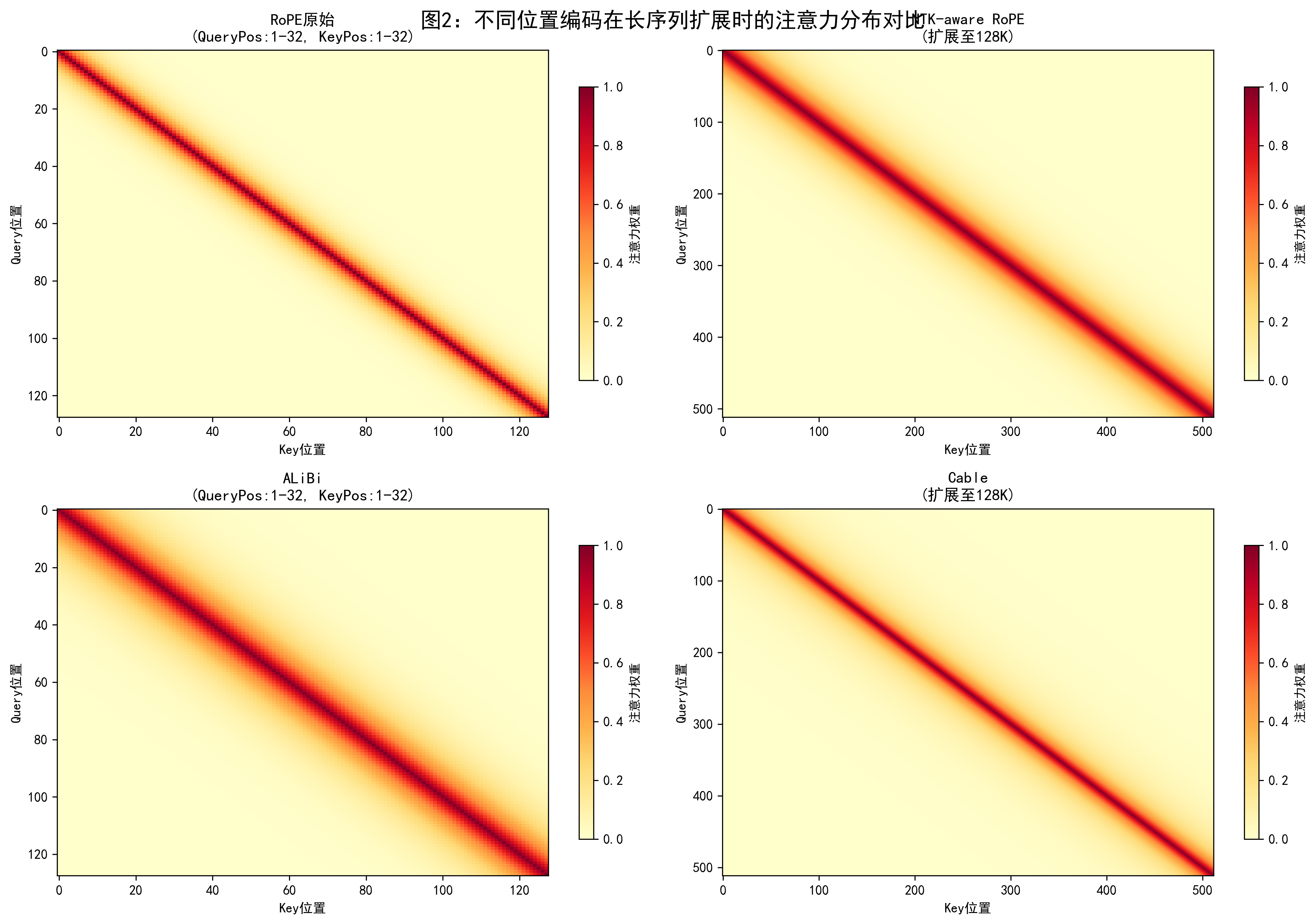
图 2 RoPE / ALiBi / Cable 等方法在长序列上的注意力分布可视化
5 多模型对比:长上下文能力的“军备竞赛”
5.1 上下文窗口与价格:谁在卷长,谁在卷便宜
基于前面的数据和公开定价,可以从“长度”和“价格”两个维度粗略看一下目前头部模型在长上下文上的竞争格局。
表 4 长上下文模型在长度与价格维度的对比(粗粒度,基于公开定价)
表头:长上下文模型长度与定价对比
| 模型 | 最大上下文窗口 | 输入 / 输出价格(USD / 百万 tokens,典型档位) | 长上下文性价比(定性) |
|---|---|---|---|
| GPT-5.1 Chat / Thinking | 128K | 约 $1.25 / $10(与 GPT-5 同档)(zapier.com) | 中高价,128K 长度偏中,重在推理与生态 |
| GPT-5.1-Codex / Codex-Max | 400K(单窗口)+ compaction 逻辑无限 | 类似 GPT-5.1 Codex,工程向 | 适合极长代码 / Agent 场景,成本较高但可替代人工工程师 |
| Gemini 1.5 / 2.5 Pro | 1M–2M | $1.25–2.5 / $10–15(Pro),Flash 更便宜(Google Cloud Documentation) | 在“真百万上下文”中性价比较高,适合需要超长会话或视频的场景 |
| Claude Sonnet 4 / 4.5 | 标准 200K,beta 1M | 输入 $3 / 输出 $15(Anthropic) | 侧重安全与代码质量,长上下文成本略高 |
| Llama 3.1 405B 等 | 128K(开源) | 自部署成本取决于算力,云端 API 多为中档价位(Meta AI) | 适合作为 128K 开源基础,易二次开发 |
| Qwen3-Next-80B | 256K | 国内云厂商价格通常低于闭源巨头,尚无统一公开汇总 | 适合中文 / 多语言长上下文企业应用 |
| DeepSeek-V3.2-Exp | 128K | 输入 $0.28 / 输出 $0.42(cache-miss);输入 $0.028 / 输出 $0.42(cache-hit)(IntuitionLabs) | 目前公开 API 中几乎最低价的 128K 长上下文模型,极具成本优势 |
从表 4 可以看到两个明显趋势:其一,“真正支持 1M–2M 的模型”目前主要集中在 Gemini 系列和部分 GPT-4.1 / Claude Sonnet 4 的 beta 配置上,而 GPT-5.1 与大部分开源模型则更多停留在 128K–400K 区间;其二,“越长越贵”仍然是硬规律,尤其当你跨过 200K 或 512K 的分界时,Anthropic 等会采用不同的定价策略(如长上下文加价、启用批处理 / 缓存优惠等),开发者在设计系统时必须把成本纳入架构考虑。(IntuitionLabs)
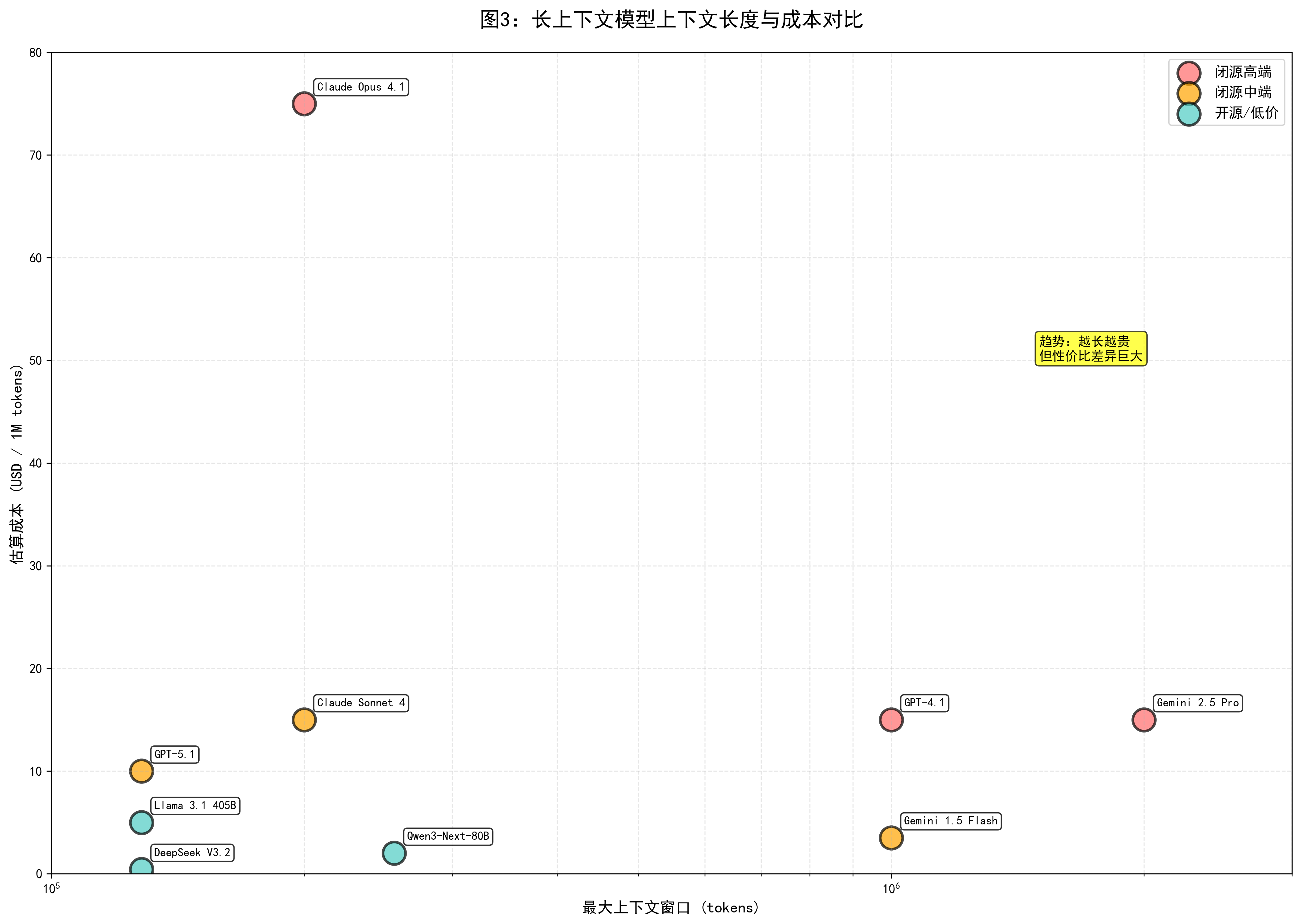
图 3 模型上下文长度与价格的二维散点图
5.2 长上下文评测结果与模型行为差异
在公开的长上下文评测中,可以观察到不同模型在“记忆能力”和“推理能力”上的不同倾向。以 NIAH / NoLiMa / many-shot ICL 与大规模 RAG 评测为例,综合已有结果与分析:(Google Cloud)
-
Gemini 1.5 Pro / 2.5 Pro:在 NIAH 上对 1M tokens 的 needle 检索接近完美,且在 many-shot ICL 场景中依托 1M–2M 上下文显著提升了分类与摘要任务的性能;
-
Claude Sonnet 4:在 1M tokens 上下文模式中更偏向“大代码库 + 文档分析”场景,其官方 / 合作博客的案例多集中在代码库重构和长合同分析,并通过 API 提供长上下文特定价位;
-
GPT-4.1 / GPT-5.1:虽然公开的长上下文 demo 多集中在 1M(4.1)和 128K–400K(5.1 系列),但凭借更强的推理能力,在 many-shot ICL 与复杂链式推理任务上往往能以更短上下文匹敌甚至超过部分超长模型;
-
Llama 3.1 / Qwen3 / DeepSeek-V3.1:在 128K–256K 区间表现良好,在开源和低价 API 场景中成为“够长 + 便宜”的主力选择,但在真正 1M 级任务上仍需配合 RAG、分页 / 切片与系统级缓存。
这种“长而不一定聪明 vs 聪明但不一定特别长”的张力,推动一线系统在工程实践中普遍采用混合策略:对于结构化事实检索,尽可能利用 RAG 将窗口缩短;对于需要 many-shot ICL 的任务,则才会把百万上下文模型当作“知识黑板”,一次性塞进大量示例进行在上下文中的“软细调”。
6 应用范式:从 RAG 到 Many-Shot ICL 与 Agent
6.1 RAG:长上下文与检索的再平衡
早期 RAG 的主要动机是“上下文太小,只能把相关文档切片后按需塞给模型”,在 2K–8K 上下文时代几乎是唯一方式。随着 32K–128K 模型普及,再到 1M–2M 模型出现,RAG 的角色开始发生改变:
-
一方面,长上下文使得“暴力塞文档”成为可能,例如把整个知识库直接扔给 Gemini 2.5 或 GPT-4.1 做 summarization 或全局分析;
-
另一方面,纯暴力塞入会带来严重的成本与性能问题,且“context rot”现象表明模型未必能在超长上下文中保持稳定性能,因此 RAG 仍然需要作为“前置过滤器”存在,只是粒度从“按页切块”变成“按章节、按主题切块”。(Google Cloud Documentation)
表 5 典型应用场景下的上下文模式与推荐窗口
表头:不同应用场景的上下文模式建议
| 场景 | 主要上下文模式 | 推荐窗口规模 | 代表模型组合(示例) |
|---|---|---|---|
| 法务 / 合同审查 | 少量合同 + 深度逐条分析 | 32K–128K 即可,配合 RAG 定位条款 | GPT-5.1 + RAG;Claude Sonnet 4 200K 模式 |
| 大型代码库 refactor | 整个 repo 上下文 + 工具调用 | 128K–400K 或 1M,配合多轮工具 | GPT-5.1-Codex-Max;Claude Sonnet 4 1M;Gemini 2.5 Pro |
| 多年聊天 / 日志分析 | 全量日志 + 高维聚类与摘要 | 1M–2M,或分批 + RAG | Gemini 1.5/2.5 Pro;DeepSeek-V3.2-Exp 128K + 分批 |
| 学术知识库问答 | 多学科知识库 + Q&A | 128K–256K + RAG 为主,偶尔用 1M 做全局总结 | Llama 3.1 / Qwen3 + 向量检索;Gemini 2.5 Pro 用于一键总结 |
| 超长视频 / 播客理解 | 音频 / 视频转写 + 多轮问答 | 1M–2M,长上下文多模态 | Gemini 1.5 / 2.5 Pro(19 小时音频);Claude / GPT-4.1 用于短视频(Google Cloud Documentation) |
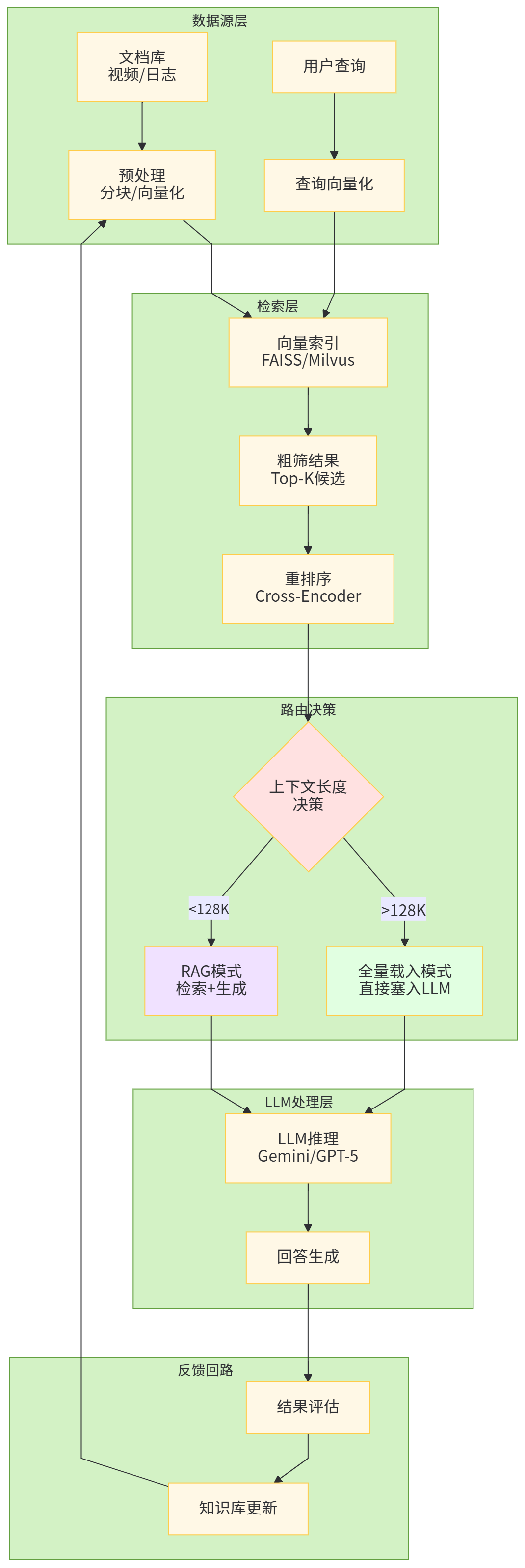
图 4 长上下文 RAG 典型系统架构
6.2 Many-Shot ICL 与 Context Engineering
当上下文到达 128K 乃至 1M 之后,研究者发现一个重要现象:如果把大量示例塞进上下文,让模型在推理时“当场学习”,很多任务的表现可以显著提升,甚至接近专门微调模型,这就是 many-shot in-context learning。(arXiv)
最新的 survey 提出“Context Engineering 的概念,认为 prompt 设计已经不只是写几句自然语言,而是要系统地规划哪些信息以什么结构放进上下文,包括:示例选取、排序、压缩与重写、分层组织、缓存策略等。长上下文在这里提供的不是“把一切都塞进去”的自由,而是一块可以系统优化的信息平面。(arXiv)
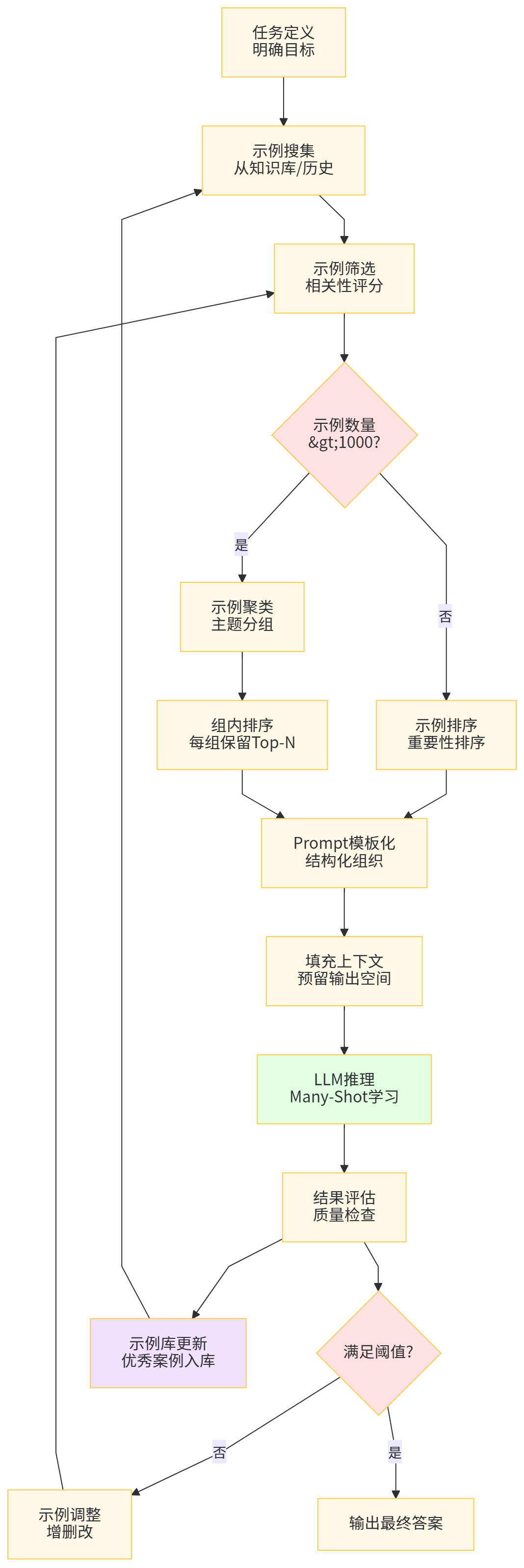
图 5 Many-Shot ICL 流程图
7 工程实践:如何用好百万级上下文
7.1 不要盲目追求“越长越好”
无论是学术 benchmark 还是工业实践,都在反复强调:上下文越长并不必然意味着效果越好。在某些任务上,增加示例数量和上下文长度的收益会逐渐降低,甚至在超过某个临界点后开始下降(典型的 context rot 现象),这在 long-context RAG 与 NoLiMa 基准的实验中都被观察到。(Medium)
因此在工程落地时,更合理的策略是:
-
为每个业务场景确定“有效上下文带宽”,例如代码审查一般不必一次性塞入整个 monorepo,而是按模块 / 依赖关系逐步载入;
-
利用 RAG 与自监督摘要在系统层主动控制输入体积,把窗口用在“真正需要记住的内容”上,而不是无差别堆砌;
-
对长上下文模型的输出进行分段校验与回滚,避免一次性长会话引入不可控的推理偏移。
7.2 缓存、压缩与 Session 管理
OpenAI 在 GPT-5.1-Codex-Max 中引入的 compaction 机制,提供了一种新的工程范式:当对话历史接近上下文上限时,模型会自动对历史进行“信息压缩”,保留关键状态并丢弃冗余细节,相当于在 session 内部自带一个“总结 + 重新开局”的流程。(OpenAI)
Anthropic 与 Google 则通过 Prompt Caching(缓存)和“长上下文加价区间”的设定,把“重复输入”与“增量输入”区分开来;DeepSeek 则通过极低价格和缓存折扣大胆鼓励用户多用长上下文,把“长上下文 + 低价”作为差异化竞争武器。(IntuitionLabs)
表 6 工程层面的长上下文管理手段
表头:长上下文工程管理手段示例
| 手段 | 主要思想 | 代表实现 | 适用场景 |
|---|---|---|---|
| Session Compaction | 在接近上下文上限时自动压缩历史,仅保留关键状态 | GPT-5.1-Codex-Max 内置 compaction(OpenAI) | 长时 Agent、连续多小时代码重构 |
| Prompt Caching | 对重复输入做缓存,后续请求按极低价格读取 | Claude Cache、DeepSeek Cache、Gemini Context Caching(IntuitionLabs) | 文档门户、固定知识库问答 |
| 分层上下文设计 | 将上下文拆成“全局摘要 + 局部细节 + 当前问题”三层 | 各家 RAG + 长上下文混合实践 | 文档 / 法务 / 数据分析 |
| 动态窗口调整 | 根据任务复杂度与预算动态调整使用的上下文窗口 | 企业侧 API 调度层 | 成本敏感的多业务平台 |
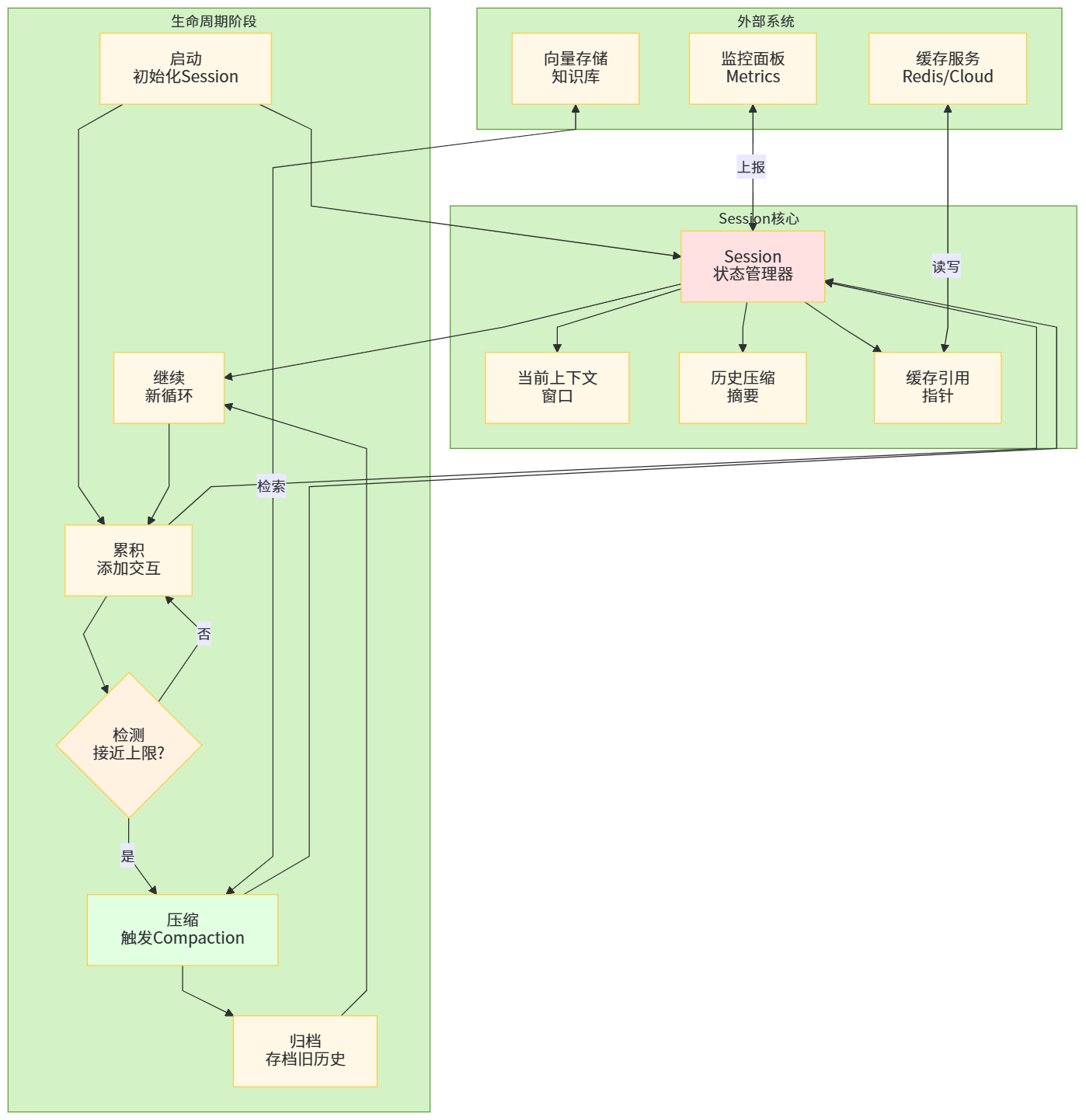
图 6 长上下文系统中 Session 生命周期管理框架图
8 未来趋势与研究方向
展望 2026 年之后,长上下文的发展大概率会沿着以下几条线继续推进:
-
从“长度竞赛”转向“上下文质量竞赛”:随着 1M–2M 成为可商用现实,单纯比谁更长已没有太大意义,更多关注点会转向如何通过 better context engineering、自动示例选择、结构化上下文表示(如 program-of-thought、graph-of-thought)在给定窗口内塞入更有用的信息。(arXiv)
-
长上下文与多模态的深度融合:Gemini 已经展示了在 2M tokens 窗口内处理 19 小时音频、长视频的能力,之后多模态长上下文应该会成为视频理解、监控分析、数字人等场景的基础设施,而不仅仅是文本问题。(Google Cloud Documentation)
-
架构创新:超越纯注意力 Transformer:Jamba 等混合架构表明,将状态空间模型(SSM)与注意力层结合,可以在不牺牲太多性能的前提下把上下文拉到 256K 甚至更高,未来可能出现更多“注意力 + 记忆 + SSM”三者混合的架构。(hackernoon.com)
-
长上下文评测的进一步系统化:NoLiMa、many-shot ICL、长上下文 RAG 只是一个开端,新的评测会更加关注真实业务工作流而非纯 toy benchmark,比如“在一整个公司 Git 仓库 + 文档上完成某个开发任务”这种 end-to-end 工作流。(arXiv)
-
模型与系统协同层面的研究:如 GPT-5.1-Codex-Max 的 compaction、DeepSeek 的缓存与极低成本、Claude 的长上下文缓存与批处理,这些都表明“长上下文”不只是模型能力,而是模型+缓存系统+调度策略共同作用的结果,这方面的理论和工程经验还有巨大空白。(OpenAI)
9 小结
这一次我们基于最新公开资料,把 GPT-5.1、Gemini 3、Qwen3、Llama 3.1、Claude Sonnet 4 / 4.5、DeepSeek-V3.1 / V3.2 等当前主流长上下文模型的上下文能力、评测表现和价格拉到一张图里,并从 长度外推、注意力近似、混合架构、系统层优化 四条主线分析了从 32K 到百万 token 的技术路径。
参考文献与资料
-
X. Wang et al. A Survey of Techniques to Extend the Context Length in Large Language Models. IJCAI, 2024.(IJCAI)
-
J. Liu et al. A Comprehensive Survey on Long Context Language Models. arXiv:2503.17407, 2025.(arXiv)
-
R. Agarwal et al. Many-Shot In-Context Learning. NeurIPS, 2024.(arXiv)
-
K. Zou et al. On Many-Shot In-Context Learning for Long-Context Language Models. ACL, 2025.(ACL Anthology)
-
L. Mei et al. A Survey of Context Engineering for Large Language Models. arXiv:2507.13334, 2025.(arXiv)
-
Google Cloud. Long context | Generative AI on Vertex AI 与 Gemini long context docs.(Google Cloud Documentation)
-
Google DeepMind. A new era of intelligence with Gemini 3. Official blog, Nov 2025.(blog.google)
-
OpenAI. GPT-5.1 and GPT-5.1-Codex model docs & release notes.(OpenAI 平台)
-
Anthropic. Claude 3.5 Sonnet Pricing & Context Window Docs; Claude Sonnet 4 1M Context Window.(Anthropic)
-
Qwen 团队. Qwen3: Think Deeper, Act Faster 与 GitHub Qwen3 仓库与 HuggingFace 模型卡。(Qwen)
-
Meta AI. Introducing Llama 3.1 与相关长上下文实践博客。(Meta AI)
-
DeepSeek 官方文档与第三方评测:DeepSeek-V3 / V3.1 / V3.2-Exp 模型卡与价格说明。(Hugging Face)
-
IntuitionLabs. LLM API Pricing Comparison (2025): OpenAI, Gemini, Claude, Grok, DeepSeek.(IntuitionLabs)
-
NIAH / NoLiMa / 长上下文评测相关工程和博客。(nrehiew.github.io)
-
Jamba、长上下文混合架构与 256K 上下文的技术解析。(hackernoon.com)


















 1301
1301

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











