




1 引言
强人工智能(Artificial General Intelligence,AGI)一直是人工智能领域最具想象力、也最具争议的终极目标之一。与已经在工业界全面落地的弱人工智能相比,强人工智能不再局限于某一个具体任务,而是强调在广泛环境中具备理解、学习、推理和行动的整体能力,这种能力在理想状态下应当可以与人类智能相当甚至超越人类。学术界对“通用智能”的定义并非一开始就清晰,例如 Legg 与 Hutter 提出的“通用智能”形式化定义,就尝试从任意环境下的预期回报最大化角度,给出可度量的机器智能指标,为后续关于 AGI 的讨论奠定了理论基础(arXiv)。与此同时,Goertzel 等人则从工程与认知架构角度,将“Artificial General Intelligence”作为一条与传统“窄 AI”不同的技术路线,强调系统在多任务、多环境中的整体适应性和自我发展能力(Paradigm)。
在过去两年中,大规模预训练模型、开放源代码的基础大模型、以及各种自主智能体框架的爆发式发展,让“强人工智能”从遥远的愿景逐渐变成产业与社会热议的现实议题。GitHub 上专门整理 AGI 相关研究的长期 Survey 仓库显示,AGI 已经从少数研究者的前沿探索,演化为涵盖认知科学、神经科学、哲学、安全治理等多学科交叉的研究方向(GitHub)。同时,产业界与媒体对于“在十到二十年内实现 AGI”的预测也层出不穷,甚至有人提出五年内可以在特定标准下实现“实用意义上的 AGI”,这背后既有技术乐观,也有对通用智能定义本身的差异理解(巴伦周刊)。
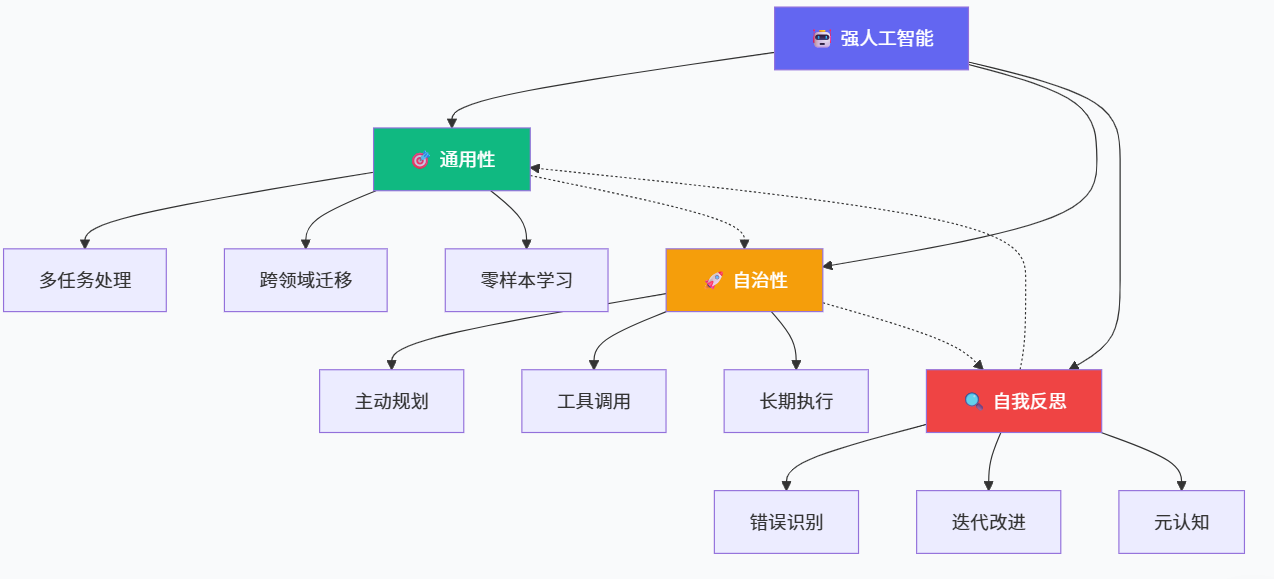
然而,如果只从“参数规模更大”“基准测试得分更高”来理解强人工智能,很容易陷入指标驱动的幻觉。真正具有启发意义的是:在纷乱的技术路线与概念口号之下,强人工智能到底需要哪些本质能力?本文试图站在开源生态与最新研究进展的视角,将“强人工智能”的能力需求抽象为三大核心:通用性(Generality)、自治性(Autonomy)与自我反思(Self-Reflection)。这三种能力之间相互依存:没有通用性,智能体难以在多任务环境中迁移经验;缺乏自治性,系统只能停留在“高级工具”而非“主动体”的层级;缺少自我反思能力,智能体就难以在长期交互中纠正偏差、积累元经验,从而跨越“看似聪明”的统计模式,走向真正稳健、可靠并可持续演化的智能。
1.1 强人工智能与弱人工智能的区分
传统意义上的弱人工智能往往围绕特定任务进行优化,例如图像分类、语音识别、机器翻译、推荐系统等,它们在单一任务上的表现甚至可以远超人类,但一旦任务发生切换,这些系统往往需要重新设计架构与训练流程。强人工智能则强调在开放环境下执行多种任务时的整体表现,这种表现不仅体现在输入输出的准确率上,更体现在面向未见任务的泛化能力、跨模态的理解能力以及在复杂环境中的长期决策与适应能力。
近年来大模型的快速发展,让这种区分开始在工程实践中具有可感知的界限。开源大模型生态中的不少技术报告都强调模型在多任务基准上的“零样本”与“少样本”能力,例如 DeepSeek LLM 在 7B 与 67B 配置下,通过大规模预训练与对齐策略,在代码、数学与推理任务上已经能与甚至超过同尺寸闭源模型,在若干领域实现接近“通用编程助手”的体验(arXiv)。从宏观视角看,这种从“为某个任务训练一个模型”转向“以一个基础模型支撑多个任务”的范式,就是通用性从理念走向工程现实的重要里程碑。
1.2 三大核心能力的提出
在海量技术路线与繁杂指标中,仅仅用“是否达到人类水平”来界定强人工智能显然过于粗糙。更可行的办法,是把“人类式通用智能”的若干关键特征抽象成可工程化的能力维度,并通过开放社区与学术研究不断迭代这些维度的定义。结合 Legg 与 Hutter 的“通用可适应性”思想、AGI Survey 等综述对认知功能的拆解(arXiv),以及大模型与自主智能体近期的开源实践,本文将强人工智能的核心能力概括为三个相互交织的方面。
第一是通用性,即系统在多环境、多任务、多模态条件下保持稳定表现与可迁移性的能力,它对应着“在哪里、做什么都不会完全陌生”的特质。第二是自治性,即系统在复杂任务和不完全信息环境中,能够主动制定目标、分解任务、调用工具并进行长期规划的能力,它决定了系统是“被动响应的工具”还是“主动执行任务的智能体”。第三是自我反思,即系统在交互过程中能够识别自身错误与局限,基于反馈进行自我评估与迭代,从而持续提升决策与生成质量的能力。近期出现的 Reflexion 与 Self-Refine 等框架,正是朝着这一方向探索如何让语言模型在推理过程中具备“内在反省”的能力(arXiv)。
下面我们将依次围绕通用性、自治性与自我反思展开,尝试梳理这三大核心能力的概念内涵、开源实践与工程实现路径,并在最后讨论其对安全、治理及未来强人工智能体系构建的启示。
2 通用性:从专用模型到通用智能
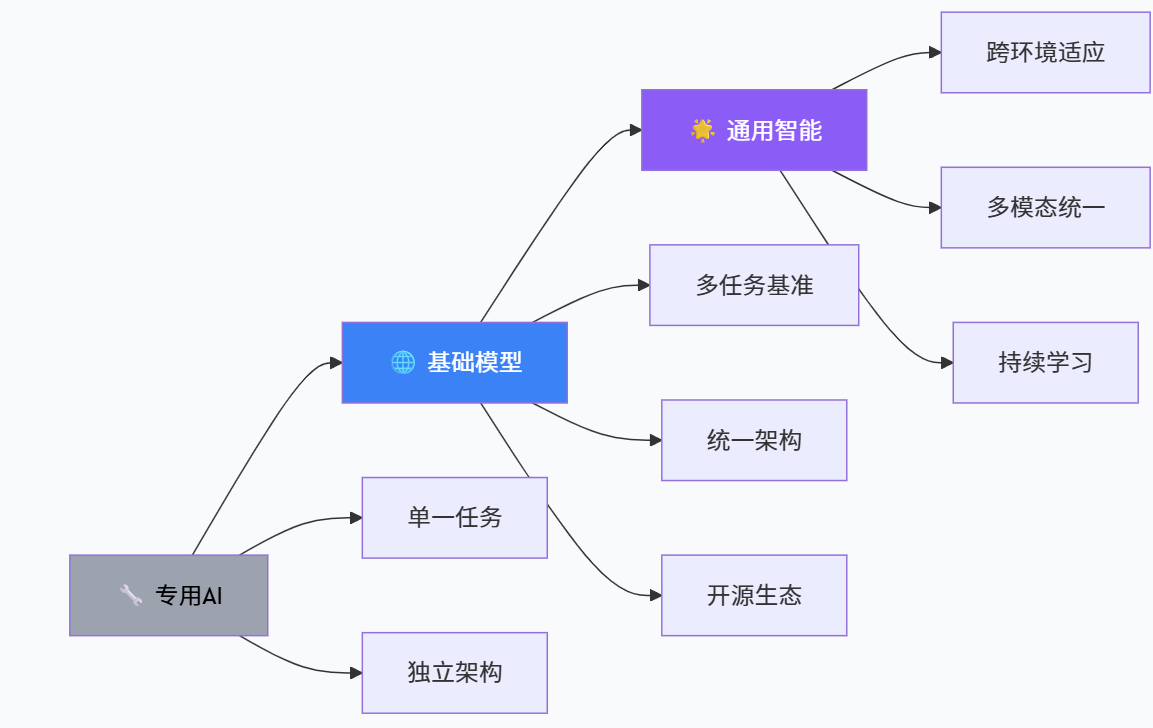
通用性是强人工智能得以成立的必要前提。如果一个系统只能在设计者预先设定的少数场景中工作,那么无论它在这些场景中表现多么卓越,都难以被称为“强”。在开源生态中,通用性最直观的载体就是所谓的“基础模型”(Foundation Models)与“大语言模型”(LLM),它们通过大规模、广覆盖的数据进行预训练,再通过少量下游适配即可服务于多种任务。
2.1 通用性的理论基础与工程指标
在理论层面,通用性可以被视作“跨环境、跨任务的期望收益”这一数学定义在工程世界中的投影。Legg 与 Hutter 提出的“通用智能”度量中,将智能体视为在无限多种可能环境上求和的加权期望,强调智能体在广泛环境中的适应性与学习能力(arXiv)。虽然该度量在实践上难以直接计算,但它清晰揭示了通用性不应仅仅依赖单一基准,而是与环境多样性、任务不确定性紧密相关。
在工程实践中,人们往往采用多维度的指标体系来近似通用性,例如多任务基准测试覆盖的任务类型数量、零样本与少样本表现差异、任务间微调的“可重用性”,以及在多模态输入下的统一表现等。最新的基础模型综述指出,机器人领域正在尝试使用统一的视觉语言动作模型,构建“通用机器人”架构,通过对不同任务和环境的统一建模来提升通用性(arXiv)。在大语言模型领域,则有大量工作通过横跨对话、编程、推理、工具调用等多个任务的综合基准来评估模型的通用能力。
为了便于理解,我们可以从弱人工智能与强人工智能的对比中观察通用性在多个维度上的表现差异。
表 2-1 强人工智能与弱人工智能在通用性维度的对比
| 维度 | 弱人工智能(窄 AI) | 强人工智能(理想形态) |
|---|---|---|
| 任务范围 | 通常面向单一或少量预定义任务 | 面向开放任务集,能够快速适配未见任务 |
| 数据分布假设 | 训练与推理通常在相似数据分布下 | 能够在分布偏移、场景变化时保持稳健 |
| 模型架构 | 针对任务定制,难以跨任务重用 | 统一的基础架构,通过少量适配支持多任务 |
| 迁移与持续学习能力 | 任务间迁移弱,更新往往意味着重新训练 | 支持跨任务迁移与持续学习,历史经验可迁移到新场景 |
| 多模态与跨模态理解 | 常用多独立模型分别处理不同模态 | 倾向于在统一表示空间中处理文本、图像、代码、动作等多种模态 |
| 工程运维与生态影响 | 系统碎片化严重,难以统一治理与优化 | 体系更趋统一,有利于构建通用平台与生态 |
从表中的对比可以看到,通用性不仅是“模型变大”或“任务数量变多”的问题,而是涉及到体系结构、训练数据、学习策略乃至运维方式的系统性演化。
2.2 开源大模型推动的通用性实践
开源基础大模型是今日讨论强人工智能时绕不过去的主角。一方面,开源模型的出现极大降低了研究者与开发者试验新想法的门槛;另一方面,多家机构在开源技术报告中非常坦率地披露数据构成、训练策略与评测指标,这让我们能够从更透明的角度理解通用性是如何在工程上被“制造”出来的。
以 DeepSeek LLM 为例,其技术报告强调了在 7B 和 67B 尺度上,通过精心构造的两万亿 Token 预训练语料、结合指令微调与偏好优化(例如 DPO)策略,使得开源模型在泛化能力上接近甚至超过部分闭源系统,尤其在代码、数学推理等需要“结构化知识与逻辑”的任务上展现出较强的通用性(arXiv)。类似地,关于国产开源大模型的比较研究指出,Qwen、LLaMA、Yi、GLM 等模型在分词策略、网络结构、激活函数与归一化方法上做出了不同的权衡,而这些设计最终体现在多语言、多任务基准上的性能差异上(53ai.com)。这类工作从工程细节层面印证了一个朴素但重要的事实:通用性从来不是“自然涌现”的魔法,而是数据覆盖、模型架构与训练策略共同作用的结果。
值得注意的是,最新关于国内开源大模型的发展综述将 2023 到 2024 年视作“快速发展与走向成熟”的阶段,指出开源大模型已经从早期的“参数竞赛”转向更注重对齐质量、多模态支持与领域落地能力,这也意味着通用性不再只是“横向做得更宽”,而是需要在“纵向做得更深”的同时保持整体一致性(科学直通车)。
为了更直观地理解开源大模型在通用性上的差异,我们可以构造一个简化的比较表格,抽象不同开源模型在一些关键指标上的倾向。
表 2-2 部分开源大模型在通用性相关维度上的抽象比较(概念化示例)
| 模型家族 | 预训练数据覆盖面(语言与领域) | 多任务基准表现倾向 | 代码与数学能力 | 多模态扩展潜力 |
|---|---|---|---|---|
| LLaMA 系列 | 英文与多语种,通用领域偏多 | 通用 NLP 与推理表现均衡 | 早期版本较弱,新版本增强 | 依赖外部多模态适配 |
| Qwen 系列 | 中文与多语种并重,技术文献较多 | 中文任务与工具调用突出 | 代码能力优秀 | 已有图像、语音扩展 |
| DeepSeek | 多源技术内容,高比例代码与推理 | 推理类任务表现突出 | 代码与数学强 | 处于快速演进阶段 |
| GLM/ChatGLM | 中文 NLU 与对话任务优势明显 | 对话与知识问答优势 | 代码能力中等 | 有多模态探索 |
该表格并非严格评测结果,而是帮助读者从宏观层面理解不同开源大模型在通用性塑造上的差异路径:有的偏向“多语言多领域的广覆盖”,有的偏向“特定领域的深耕”;有的先做强文本再扩展多模态,有的则一开始就将多模态纳入基础架构设计。
3 自治性:从工具到智能体
如果说通用性回答了“会不会做很多事”的问题,那么自治性则回答“是谁在主动做这些事”。在传统软件范式中,系统通常被设计为被动响应用户请求的工具,而在强人工智能愿景中,系统被期望拥有一定程度的自主决策与持续执行能力,从而在复杂任务中真正承担“代理人”的角色。
3.1 自治性的内涵与层次
自治性并不意味着“无限制的自由”,而是指在一定目标与约束下,系统能够主动规划、执行与调整行为,而无需人类针对每一步细节进行显式指令。AGI 相关文献中时常将智能体视为一个感知、记忆、规划与行动的统一体,并通过环境—智能体交互来定义其行为策略(Paradigm)。在大模型时代,自治性的载体逐渐从强化学习中的“虚拟机器人”,转向由 LLM 驱动的通用软件智能体。
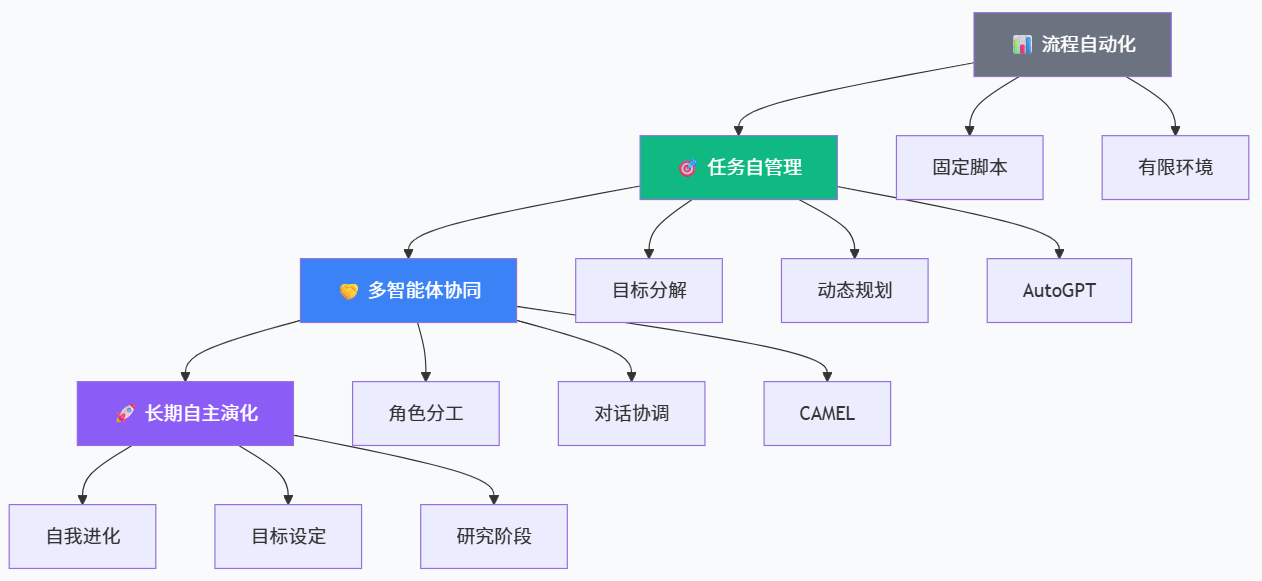
开源社区中,自主智能体框架的快速涌现为自治性提供了极好的实验平台。例如 AutoGPT 与 BabyAGI 这类项目,通常通过“循环任务执行”的设计,让 LLM 在每一轮循环中根据目标与环境状态生成下一步行动,包括分解子任务、调用外部工具、更新记忆,并以此实现端到端的自主演化过程。有分析指出,AutoGPT 强调插件化与工具调用能力,而 BabyAGI 则通过“任务创建—优先级排序—执行”三个核心组件构建了精简而高效的自治循环,两者共同标志着“AI Agent 技术从概念走向工程实践”的关键转折点(阿里云开发者社区)。
从工程视角看,自治性至少包含几个递进层次:最基础的是在固定任务中实现“自动完成多步流程”,例如自动化数据分析脚本;更进一步是在模糊目标下能够自我分解任务并选择合适工具;最高层则是在长期环境中主动提出目标、协调多个智能体协同并在不确定反馈下持续修正策略。当前开源 Agent 框架多处于第二个层级,但部分多智能体系统(如 CAMEL、HuggingGPT 等)已经开始探索第三个层级的雏形(知乎专栏)。
表 3-1 可以帮助我们从工程角度梳理自治性的层次。
表 3-1 自治性在工程实现中的层次划分(概念性)
| 自治性层次 | 系统典型行为描述 | 代表性开源实践示例 |
|---|---|---|
| 流程自动化层 | 按预定义脚本或流程执行多步任务,环境变化小 | 传统 RPA、简单 ChatGPT + 脚本 |
| 任务自管理层 | 在给定总体目标下,自行分解任务、调用工具、调整计划 | AutoGPT、BabyAGI 等单智能体框架 |
| 多智能体协同层 | 多个智能体分工协作,通过对话协调达成复杂目标 | CAMEL、HuggingGPT 等多智能体系统 |
| 长期自主演化层 | 在开放环境中持续设定目标、反思与进化,具备长期记忆与自我模型(仍在探索中) | 研究性原型与理论工作,尚无成熟开源工业系统 |
这一层次划分并非严格标准,但可以帮助我们理解:今天我们看到的“自治 Agent 热潮”,更多是位于任务自管理层与多智能体协同层,其自治性仍然受到工具调用能力、记忆设计、以及对人类安全约束的多重限制。真正达到“长期自主演化”的系统还主要存在于理论探索与小规模实验中。
3.2 Agent 框架:自治性的开源实验场
近两年,围绕“LLM Agent”的研究和工程框架几乎形成了一条独立的生态链。从开源社区整理的“AI Agents 清单”可以看到,AutoGPT、BabyAGI、CAMEL、AgentGPT、Godmode 乃至各种行业垂直 Agent 架构层出不穷,它们共同尝试回答这样一个问题:如果把大语言模型视为“通用决策与生成核心”,如何通过记忆、工具、环境接口和调度机制,将其包装成具有自治性的整体系统(知乎专栏)。
以 AutoGPT 为例,其核心设计是将 LLM 置于一个“思考—批评—执行”的闭环之中:在每一轮循环中,模型先对目标进行思考,提出计划,再对计划进行自我批评与调整,最终生成需要调用的具体工具或执行命令;执行结果又会写入记忆系统,为下一轮思考提供上下文。BabyAGI 则更加轻量,通过三类子 Agent 来分别负责生成新任务、为任务排序以及执行任务,形成一个高度模块化且易于扩展的自治循环(阿里云开发者社区)。
值得注意的是,这些框架往往是开源社区在极短时间内快速迭代的成果,有些项目从 GitHub 初次开源到获得上十万 Star 只用了几个星期。这种超高速演化既展示了大模型驱动自治 Agent 的巨大吸引力,也暴露出工程不成熟与安全性不足的问题:许多 Agent 框架在设计之初并未深度考虑资源消耗控制、异常情况处理、目标对齐与滥用风险等关键议题,这也给强人工智能的安全发展敲响了警钟(The Millennium Project)。
3.3 通用性与自治性的交互
通用性与自治性之间并非简单叠加关系。理论上,一个高度通用但完全被动的模型仍然只是“万能工具箱”,而一个自治性很强但能力狭窄的系统则容易在复杂环境中犯下系统性错误。真正面向强人工智能的系统,需要在两者之间形成良性反馈:通用性为自治性提供足够丰富的认知与行为基础,而自治性又通过主动探索与环境交互,为系统积累新的经验与数据,从而进一步扩展通用性。
例如,在机器人领域使用基础模型构建通用机器人时,研究者往往希望机器人不仅能够理解多种指令、识别多类物体,还能在长时间任务中自主规划路径与策略,这就要求基础模型的表征能力与规划模块的自治性紧密耦合(arXiv)。在软件智能体世界,AutoGPT 类框架依赖于强大的语言模型才能在信息检索、代码生成、文档撰写等多任务上获得高质量行为;反过来,Agent 的长期运行轨迹又可以作为高价值数据,用于微调模型,使其更适应真实任务场景。
4 自我反思:从一次性输出到持续改进
在人类认知中,自我反思能力常被视为“元认知”的关键组成部分,它让个体能够评估自己的行为、识别错误、总结经验并在之后的情境中做出更好的决策。对强人工智能而言,自我反思是使系统在长期运行中保持可持续进步与稳健性的关键能力,同时也是降低幻觉、偏见与错误风险的重要机制。
4.1 自我反思的概念与必要性
传统机器学习模型往往采用“训练期—推理期”严格分离的范式:在训练期通过梯度下降等方法更新参数,在推理期仅进行前向计算,几乎没有在线修正的能力。大模型时代虽然引入了“Chain-of-Thought”等显式推理策略,但多数系统仍然是“一次性生成答案”,缺乏系统性的自我评估与修正机制。
随着智能体在开放环境中的应用增多,研究者意识到,仅仅依赖训练期的优化很难应对复杂环境下的长尾情况。Reflexion 这一工作提出了一个有趣而有效的思路:不再通过梯度更新模型参数,而是让语言智能体在任务后对自己的行为进行“语言化反思”,将反思结果存入记忆,供后续尝试参考。通过这种“口头自省”的方式,智能体能够在多次尝试中逐渐总结“哪些策略有效、哪些错误需要避免”,从而在无需额外训练的情况下显著提升性能(arXiv)。研究表明,在 HumanEval 等基准上,加入 Reflexion 机制的智能体可以在多轮尝试中获得远超单轮生成的成功率(知乎专栏)。
Self-Refine 则从另一条路径将自我反思引入大模型应用场景。该方法首先让模型生成初始输出,然后再让同一个模型对这份输出进行点评与反馈,最后根据反馈对输出进行若干轮改写。整个过程无需额外监督数据与训练,仅依靠“生成—评价—改写”的循环就能在对话生成、数学推理等多种任务上带来显著提升(arXiv)。这项工作清晰展示了一个事实:即便是当前已非常强大的大模型,其一次性输出仍有大量改进空间,而自我反馈与迭代机制能极大释放模型潜力。
4.2 Reflection 模式与 Agent 框架的融合
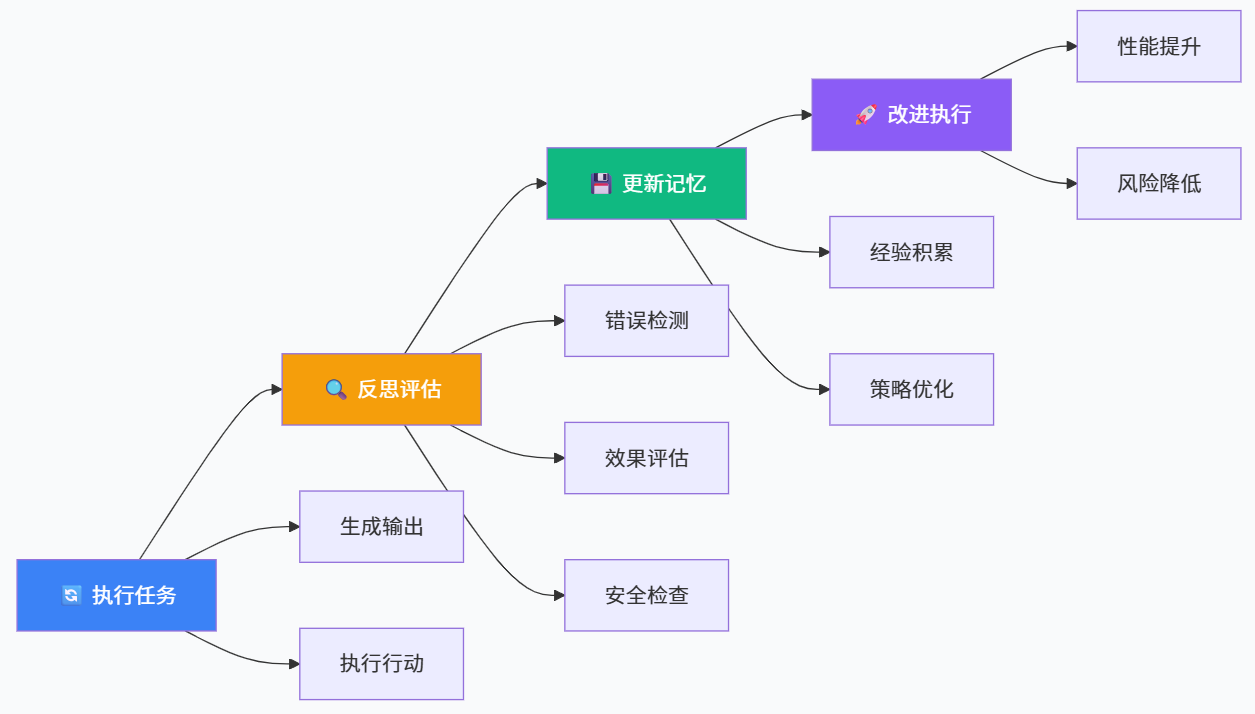
在工程实践中,自我反思往往并不是独立存在的模块,而是与自治 Agent 的循环流程紧密结合。很多关于“Agentic LLM 模式”的总结都将 Reflection 视作与 ReAct、Tool Use 等模式并列的关键模式之一,即通过显式反思步骤,让智能体在每一次行动之后对自身决策做“复盘”(优快云)。
在典型的 Agent 循环中,自我反思可以以多种形式出现。最简单的形式是对失败案例进行反思:当智能体某次尝试未能完成任务时,它将失败原因口头化,例如“我误解了题目中变量的含义”或“我调用的 API 返回格式与预期不符”,然后将这些反思写入长期记忆,供下一轮尝试参考。更复杂的设计则会在每一轮成功或失败后都进行反思,从而让智能体在“成功经验与失败教训的混合记忆”中不断更新“策略偏好”。
在开源社区中,已经有不少 Agent 框架将 Reflexion 或 Self-Refine 思路整合进自身循环,例如在任务执行循环中插入一个显式的“点评与复盘”步骤,或者在生成代码后自动生成测试用例并根据测试结果进行多轮修正。这些实践说明,自我反思并不是一个抽象的哲学概念,而是可以通过简单而有效的工程手段融入智能体系统中,从而大幅提升系统的鲁棒性与可靠性(优快云)。
4.3 自我反思与安全、可信度
从强人工智能安全的视角来看,自我反思能力具有重要的缓冲作用。一方面,反思机制可以帮助系统在检测到与训练分布偏离的情况时发出“自我不确定信号”,从而主动降低输出的自信程度或者请求人类介入;另一方面,反思日志本身可以成为极有价值的审计与分析材料,为后续的安全治理与责任追踪提供依据。
未来关于 AGI 治理的研究中,越来越多的论文强调在技术架构中内嵌“可解释性与可审计性”,而自我反思日志正是这种内嵌机制的重要候选载体(The Millennium Project)。一个真正面向社会大规模部署的强人工智能系统,不应仅仅追求“输出正确答案”,更应在可能造成高风险后果的场景中主动进行自我检视,明确标注自身的不确定性与潜在缺陷。
5 三大核心能力视角下的开源实践地图
从通用性、自治性与自我反思这三大核心能力出发,我们可以构造出一张“强人工智能能力—开源实践”的映射图,用于帮助开发者在众多开源项目中找到定位与组合方式。
5.1 开源生态中的能力分工
在开源世界中,很少有单一项目试图“从零到一”实现完整的强人工智能体系,相反,大部分项目都在某个能力维度上深耕,然后与其他项目通过接口、协议与框架层面相互组合。以当前生态为例,大致可以看到这样一种“能力分工”格局。
基础大模型项目(如 LLaMA、Qwen、DeepSeek 等)主要聚焦于通用性的构建,它们通过大规模多领域数据预训练和多任务评测来保证模型在广泛任务上的基本能力(arXiv)。自主 Agent 框架(如 AutoGPT、BabyAGI、CAMEL 等)主要关注自治性的实现,通过任务循环、工具调用、记忆管理和多智能体协同来赋予系统长期执行复杂任务的能力(阿里云开发者社区)。而自反思相关框架(如 Reflexion、Self-Refine)则重点突破自我反思这一维度,通过引入语言化反馈与迭代改进机制,提升智能体在长期运行中的表现与稳定性(arXiv)。
基于这一视角,我们可以构造一个简化的“开源实践地图”,用表格来呈现不同项目在三大能力维度上的侧重点。
表 5-1 三大核心能力与代表性开源实践的概念性映射
| 能力维度 | 代表性项目或技术路线 | 核心贡献抽象 |
|---|---|---|
| 通用性 | LLaMA、Qwen、DeepSeek 等开源大模型 | 提供强大的跨任务语言理解和生成能力,多语言、多领域的知识基础 |
| 自治性 | AutoGPT、BabyAGI、CAMEL、HuggingGPT | 通过 Agent 循环、工具调用、多智能体协作赋予系统长期任务执行与管理能力 |
| 自我反思 | Reflexion、Self-Refine、Agent Reflection 模式 | 引入语言化反思与迭代改进机制,提升决策质量、降低错误和幻觉风险 |
需要强调的是,这种映射并非绝对界限。很多最新的开源项目正在尝试在单一系统中同时引入三种能力,例如在一个统一的 Agent 框架中加载多模态大模型作为通用能力核心,同时配备完善的任务循环与长期记忆,并在每轮任务执行后自动记录和利用反思日志。
5.2 从能力到架构:构建强人工智能系统的工程路径
对于工程团队而言,如何从“能力维度”的抽象概念落地到具体系统架构,是实现强人工智能愿景时必须面对的问题。基于当前开源生态,我们可以构想一种分层架构,将通用性、自治性与自我反思以相对解耦的方式整合在一起。
在最底层,基础大模型作为“普适认知引擎”,负责处理文本、代码以及潜在的多模态输入输出,提供统一的表示与生成能力。在中间层,Agent 框架通过对话管理、工具调用、任务调度和记忆系统,将大模型包装为可以在外部环境中持续执行任务的自治智能体。在顶层,自我反思与安全治理组件对 Agent 的行为进行监控与评估,记录日志、识别异常、执行策略修正,并在必要时触发人类介入或策略重设。
这种分层架构的优势在于,每一层都可以依托开源项目进行替换与升级,而不会彻底破坏整体系统。例如,团队可以在不改动 Agent 框架的前提下,从 LLaMA 切换到 Qwen 或 DeepSeek,从而提升中文或特定领域任务表现;也可以在不动基础模型的情况下,为 Agent 增加新的工具插件和记忆策略,以提升自治性;进一步,还可以在不改变底层智能能力的前提下,引入更为严格和透明的自我反思与审计机制,以应对更高风险的应用场景。
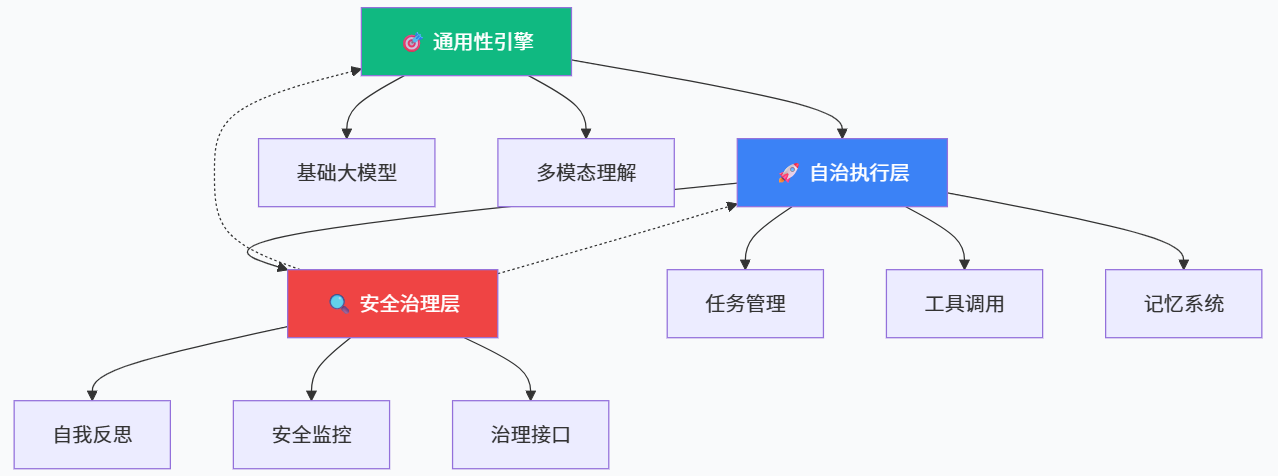
5.3 能力权衡与领域落地
在具体领域落地时,三大核心能力之间往往需要做权衡。某些对安全性要求极高且任务范围相对稳定的场景(如某些工业控制、人身安全相关系统)可能不适合追求过度的自治性,而是必须在强监管与强约束下运作;某些创意类应用则可以在相对安全的上下文中允许较大的自治空间,甚至鼓励系统自行探索多种路径。
领域化落地的调研指出,在金融、医疗等领域引入开源大模型时,往往更看重模型对领域知识的适配能力与可控性,而不是简单的通用性指标;在对话客服、智能文档处理等场景中,则更希望系统拥有基本自治性,可以根据用户的模糊需求进行主动引导和信息补全,但同时要配备清晰的审计与反馈渠道(科学直通车)。这意味着在工程实践中,团队需要根据业务风险和收益,把通用性、自治性与自我反思能力的“旋钮”调到合适的位置,而不是一味追求“最强”。
6 安全、治理与未来展望
随着通用性、自治性与自我反思三大能力在开源生态中的不断增强,强人工智能已经不再是纯粹的学术议题,而是逐渐演变为技术、安全与社会治理的综合挑战。不少国际机构与智库已经开始讨论 AGI 带来的系统性风险,包括失控行为、价值观偏移、大规模失业甚至潜在的生存风险(The Millennium Project)。
6.1 能力提升与风险放大的并行
通用性越强,系统能介入的领域越多,其错误影响范围也越广;自治性越强,系统在无人监督下能够做出的行动越多,一旦价值对齐出现偏差,风险也会被放大;自我反思能力若被错误设计,甚至可能被用于“掩饰错误”或“优化欺骗策略”。因此,强人工智能的三大核心能力在带来巨大潜力的同时,也在安全维度引入了新的复杂性。
未来关于 AGI 安全与治理的研究已经提出,需要从系统设计阶段就考虑约束机制,例如将自我反思框架与“可解释性日志”“合规性检查”深度结合,让系统不仅在内部进行反思,也能以合适粒度向外部监管者公开自身行为决策的依据(The Millennium Project)。同样地,在自治性层面,如何限制 Agent 的资源访问范围、对关键操作设置多重确认乃至强制人类在环,都是防止自治性滑向“失控”的关键技术问题。
6.2 开源与闭源在强人工智能路径上的互补
开源生态在推动通用性、自治性与自我反思等能力的快速发展方面发挥了巨大作用,但也引发了关于“开放是否会加剧风险扩散”的争论。一方面,开源项目为全球研究者与开发者提供了共同的实验平台,大大加快了创新速度;另一方面,高性能开源模型与 Agent 框架的滥用风险也不容忽视。
一些 AGI 治理的研究建议采用“责任分层”的方式,即在基础能力层面鼓励开放与共享,以便更多研究者进行安全性测试和方法改进;而在高风险领域的具体应用与部署层面,则通过法规、行业标准与审计机制进行严格管控(The Millennium Project)。从能力视角看,通用性的研究更适合借助开源模型进行广泛验证,自我反思与安全机制的设计也受益于社区的审查与改进;而高度自治的任务执行系统则可能需要更严格的访问控制与分级授权。
6.3 面向未来的研究与工程议程
综合上述讨论,可以看到,强人工智能的三大核心能力并非孤立存在,而是和数据、架构、训练、治理、社会接受度等多维因素交织在一起。未来几年,围绕这些能力的研究与工程实践很可能沿着几个方向推进。
其一,在通用性方面,更强的多模态与跨模态能力将成为重要趋势,机器人、虚拟环境与现实世界传感器数据会更多地纳入基础模型训练之中,使模型不仅理解语言和代码,也能在视觉、动作乃至物理世界中形成统一的抽象表征(arXiv)。
其二,在自治性方面,会有更多工作探索“可控自治”,即在保证安全和合规的前提下,赋予智能体足够的决策自由度,使其能够在大规模复杂系统中替代人类处理繁琐与高频任务,而关键决策仍由人类掌控。
其三,在自我反思方面,研究者可能会从当前基于语言的反思机制逐步推进到更深层的“自我模型”,即让系统对自己的能力边界与行为后果形成更系统化的内部表征,从而在不确定情境下做出更谨慎且可解释的行为选择(arXiv)。
7 结语:以三大核心能力重塑强人工智能叙事
在关于强人工智能的讨论中,人们往往容易被“是否超过人类”“何时到来 AGI”这类宏大问题所吸引,而忽略了那些真正可以在当下工程实践中推进的关键能力。本文尝试从通用性、自治性与自我反思三大核心能力出发,结合近期开源大模型、Agent 框架以及自反思机制等方面的研究与实践,构建出一幅相对清晰的能力地图。
通用性让智能体能够在多任务、多模态、多场景中保持一致而稳健的表现,是强人工智能的“地基”;自治性让智能体从被动工具转变为主动执行者,是强人工智能“活起来”的关键;自我反思则让智能体在长期运行中能够持续纠正错误、积累经验并提高可信度,是强人工智能“可持续、安全发展”的保障。三者之间的相互作用,构成了从开源大模型到面向未来 AGI 系统的一条现实可行的演化路径。
可以预见,未来的强人工智能系统不一定会是单一庞大的“超级模型”,而更可能是由多个具有不同侧重的能力模块构成的复杂系统:底层是通用的大模型,负责表征与生成;中层是自治的 Agent 网络,负责任务规划与执行;上层是自我反思与安全治理机制,负责评估、纠偏与对齐。开源生态在这条道路上已经迈出了坚实步伐,也为研究者和工程师提供了前所未有的实验场。
对每一位从业者来说,理解并善用这三大核心能力,既是参与强人工智能时代建设的重要前提,也是避免被“参数规模”与“营销话术”迷惑的理性武器。当我们将通用性、自治性与自我反思真正落到系统设计、代码实现与部署治理之中时,“强人工智能”这个曾经遥远而模糊的概念,才会逐步从科幻想象走向可控、可用且可被社会信任的技术现实。
参考资料
[1] Shane Legg, Marcus Hutter. Universal Intelligence: A Definition of Machine Intelligence. Artificial General Intelligence, 2007. (arXiv)
[2] Ben Goertzel. Artificial General Intelligence: Concept, State of the Art, and Future Prospects. Journal of Artificial General Intelligence, 2014. (Paradigm)
[3] Bowen Xu et al. AGI-Survey: An Ongoing Survey of Artificial General Intelligence (GitHub Repository). (GitHub)
[4] Fei Xia et al. Toward General-Purpose Robots via Foundation Models: A Survey and Meta-Analysis. 2023. (arXiv)
[5] DeepSeek-AI. DeepSeek LLM: Scaling Open-Source Language Models with Longtermism. 2024. (arXiv)
[6] Comparative Analysis of Domestic Open-Source Large Language Models. Procedia Computer Science, 2025. (科学直通车)
[7] 不同开源大模型对比及领域落地选型考虑(Qwen2、LLaMA、GLM4 等),53AI 知识库技术文章,2024. (53ai.com)
[8] Noah Shinn et al. Reflexion: Language Agents with Verbal Reinforcement Learning. arXiv:2303.11366, 2023. (arXiv)
[9] Aman Madaan et al. Self-Refine: Iterative Refinement with Self-Feedback. arXiv:2303.17651, 2023. (arXiv)
[10] 自动代理机器人:BabyAGI,Auto-GPT,CAMEL 等,知乎专栏文章,2023. (知乎专栏)
[11] AutoGPT vs BabyAGI:自主任务执行框架对比与选型深度分析,阿里云开发者社区文章,2025. (阿里云开发者社区)
[12] LLM agentic 模式之 Reflection:SELF-REFINE、Reflexion 等,优快云 技术博客文章,2024. (优快云)
[13] Future of Life Institute. Artificial General Intelligence Governance and Safety Reports, 2023–2024. (The Millennium Project)
[14] Towards Artificial General or Personalized Intelligence? A Survey on Personalized Federated Intelligence. arXiv:2505.06907, 2025. (arXiv)




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











