




1. 引言:视觉Transformer的新篇章
在深度学习的浪潮中,Transformer架构自2017年提出以来就以其强大的序列建模能力震撼了自然语言处理领域。随着Vision Transformer (ViT)的横空出世,Transformer架构成功跨越了模态边界,在计算机视觉任务中展现出了与卷积神经网络相媲美甚至更优的性能。然而,如何更好地适应视觉数据的特性,充分挖掘图像的层次化信息,仍然是一个值得深入探索的问题。
韩凯等人在2021年NeurIPS会议上提出的Transformer in Transformer (TNT)架构,为这一问题提供了一个创新而优雅的解决方案。TNT不满足于简单地将图像切分成patch进行处理,而是进一步引入了"视觉句子"和"视觉词汇"的概念,通过嵌套的Transformer结构实现了更加细粒度的视觉特征建模。这种设计理念不仅在理论上具有重要意义,在实践中也取得了显著的性能提升。
本文将深入解析TNT架构的核心思想、技术细节和实验结果,探讨其在视觉Transformer发展历程中的重要价值,并分析其对后续研究的启发意义。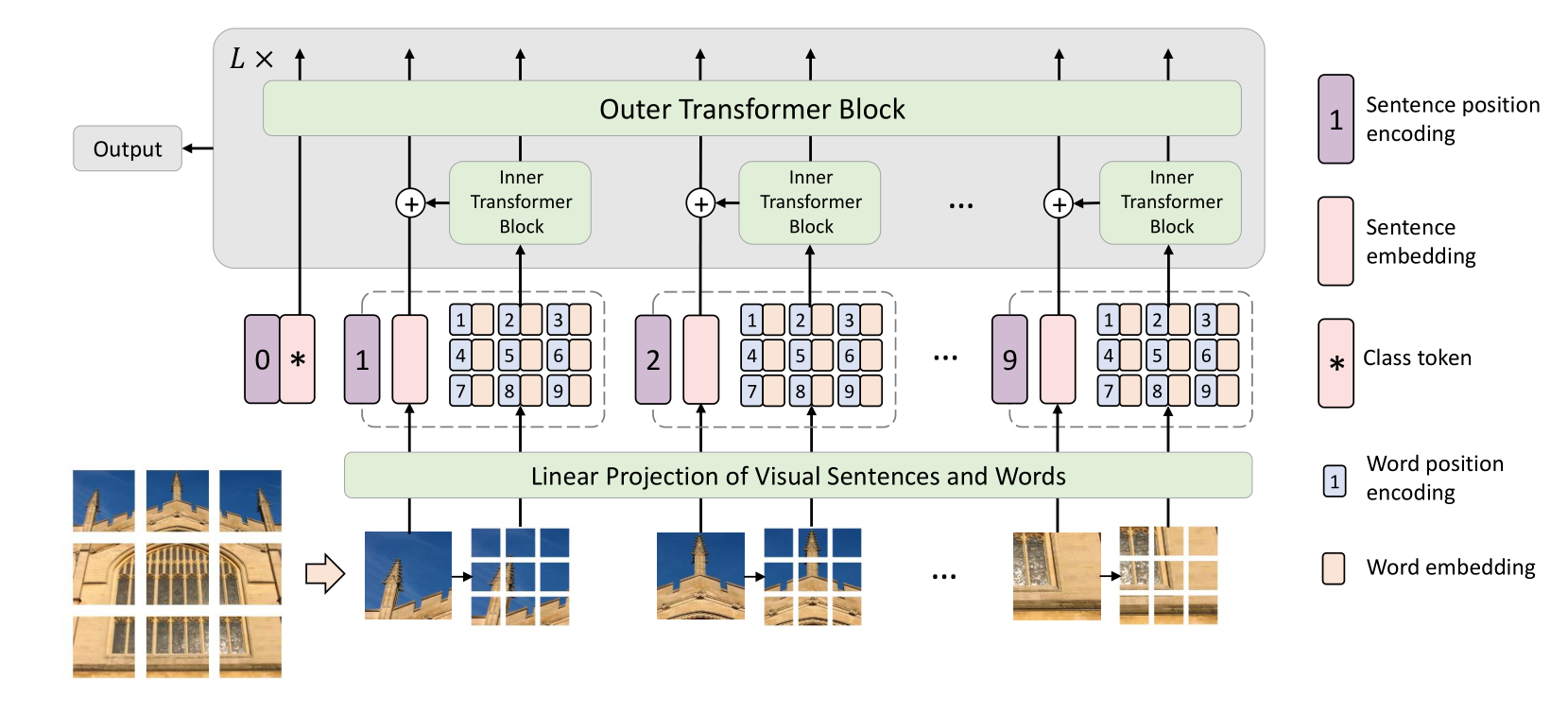
2. TNT架构核心思想:从句子到词汇的层次化建模
2.1 问题动机与设计理念
传统的Vision Transformer采用了相对粗糙的图像表示方法:将输入图像均匀切分成若干个patch(通常为16×16像素),然后将每个patch视为一个token进行处理。这种做法虽然简单有效,但存在一个明显的不足:patch内部的局部结构信息没有得到充分利用。
TNT的核心洞察在于,自然图像具有丰富的层次化结构特征。不同尺度的物体、纹理和细节信息都蕴含着重要的语义。如果能够在patch级别的基础上进一步挖掘更细粒度的特征,就有可能获得更强的表示能力。
受自然语言处理中句子-词汇层次结构的启发,TNT提出了"视觉句子"(Visual Sentences)和"视觉词汇"(Visual Words)的概念:
- 视觉句子:对应传统ViT中的patch(如16×16),代表图像的中等粒度区域
- 视觉词汇:将每个视觉句子进一步细分为更小的sub-patch(如4×4),代表更细粒度的局部特征
2.2 双层Transformer架构设计
基于上述理念,TNT设计了一个创新的双层Transformer架构:
- 内层Transformer(Inner Transformer):专门处理视觉词汇之间的关系,捕获patch内部的局部依赖
- 外层Transformer(Outer Transformer):处理视觉句子之间的关系,建模全局的空间依赖
这种设计的巧妙之处在于,内层Transformer的计算是在每个patch内部独立进行的,因此计算复杂度的增长相对有限,而表示能力却得到了显著提升。
3. TNT网络架构设计
3.1 数学建模与公式推导
TNT的核心计算过程可以通过以下数学公式来描述。
给定输入图像,首先将其分割为n个patch:,其中(p,p)是每个patch的分辨率。
接下来,每个patch 被进一步分割为m个sub-patch(视觉词汇):
其中 是第i个视觉句子中的第j个视觉词汇。
通过线性投影,视觉词汇被转换为词汇嵌入:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 650
650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











