







 这篇博客介绍了B站主站技术中心算法开发面试的五个问题,涉及word2vec的负采样细节、fasttext的改进、用rand2实现rand5的方法、Bert模型及其下游任务,以及除Bert之外的预训练模型拓展如RoBERTa。深入探讨了词向量表示、NLP模型和随机数生成策略。
这篇博客介绍了B站主站技术中心算法开发面试的五个问题,涉及word2vec的负采样细节、fasttext的改进、用rand2实现rand5的方法、Bert模型及其下游任务,以及除Bert之外的预训练模型拓展如RoBERTa。深入探讨了词向量表示、NLP模型和随机数生成策略。
问题1:介绍word2vec,负采样的细节
word2vec是google于2013年开源推出的一个词向量表示的工具包,其具体是通过学习文本来用词向量的方式表征词的语义信息,即通过一个低维嵌入空间使得语义上相似的单词在该空间内的距离很近。有两种模型:CBOW和skip-Gram,其中CBOW模型的输入是某一个特征词的上下文固定窗口的词对应的词向量,而输出就是该特定词的词向量;Skip-Gram模型的输入是特定的一个词的词向量,输出就是特定词对应的上下文固定窗口的词向量。
现在我们看下Word2vec如何通过Negative Sampling负采样方法得到neg个负例;如果词汇表的大小为V,那么我们就将一段长度为1的线段分成V份,每份对应词汇表中的一个词。当然每个词对应的线段长度是不一样的,高频词对应的线段长,低频词对应的线段短。
每个词w的线段长度由下式决定︰
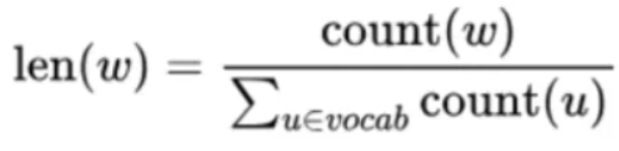
在word2vec中,分子和分母都取了3/4次幂如下:
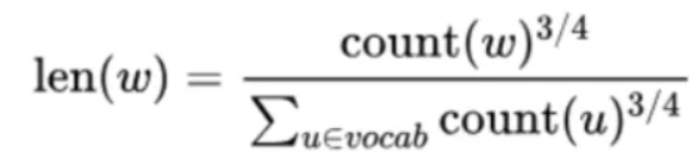
在采样前,我们将这段长度为1的线段划分成M等份,这里M>>V,这样可以保证每个词对应的线段都会划分成对应的小块。而M份中的每一份都会落在某一个词对应的线段上。在采样的时候,我们只需要从M个位置中采样出neg个位置就行,此时采样到的每一个位置对应到的线段所属的词就是我们的负例词。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









