



关于网络层
ip协议
地址管理
数据链路层
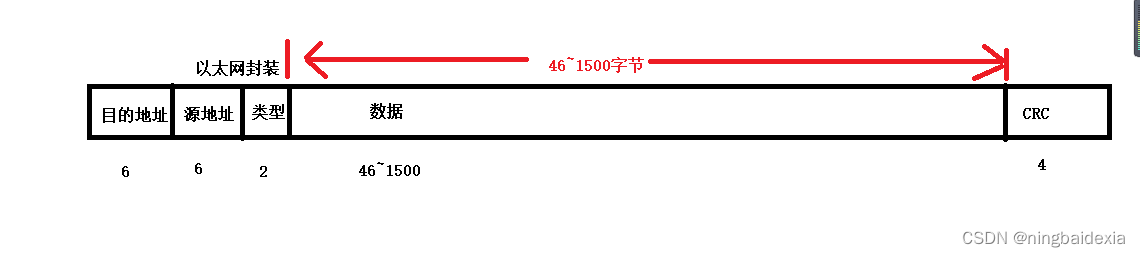
6个字节的地址包含 物理地址/mac地址
为什么已经有ip地址还要设计mac地址?
这是因为历史问题 ip地址和mac地址 被各自独立设计出来了
ip地址 负责网络层转发 整体的转发过程
mac地址 负责数据链路层转发 局部相邻设备转发的过程
例如:从北京去往深圳 中途经过上海
1.北京->上海

2.上海->深圳
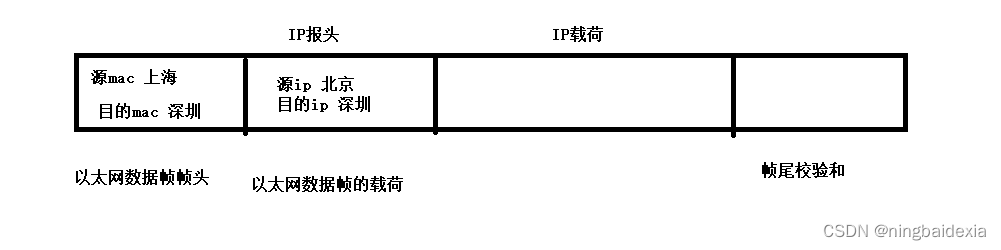
实际上mac地址(6个字节) IP地址(4个字节)
一个主机既有ip也有mac
(mac地址是6个字节表示的范围比ipv4的地址大很多 42亿*6w5k 所以当前的mac地址都是网卡出厂的时候就写死了
可以保证每个设备的网卡都有独立的mac地址 所以mac地址也就成了互联网上一种身份标识的方式)
以太网数据帧的载荷可以有多种形式
根据前面两字节的类型区分
以太网的数据帧body部分最大长度1500字节(差不多1kb 受限于硬件)
DNS(域名解析系统)
上网 访问服务器要知道服务器的ip地址
ip地址 是一串数字 但这串数字就算使用点分十进制 仍然不方便我们记忆 所以我们会使用单词来代替IP地址
使用baidu sogou jingdong的单词代替IP地址
这样的单词就称位域名 实践中为了保证域名的唯一性域名往往是分级的
www.sogou.com
.com一级
.com(公司) .cn(中国) .edu(教育组织)
.sogou二级
www三级
www.sogou.com 这是给人们使用的 但机器不认识 所以有一套系统把域名自动翻译成ip地址DNS
最早的DNS是一个文件(hosts文件)
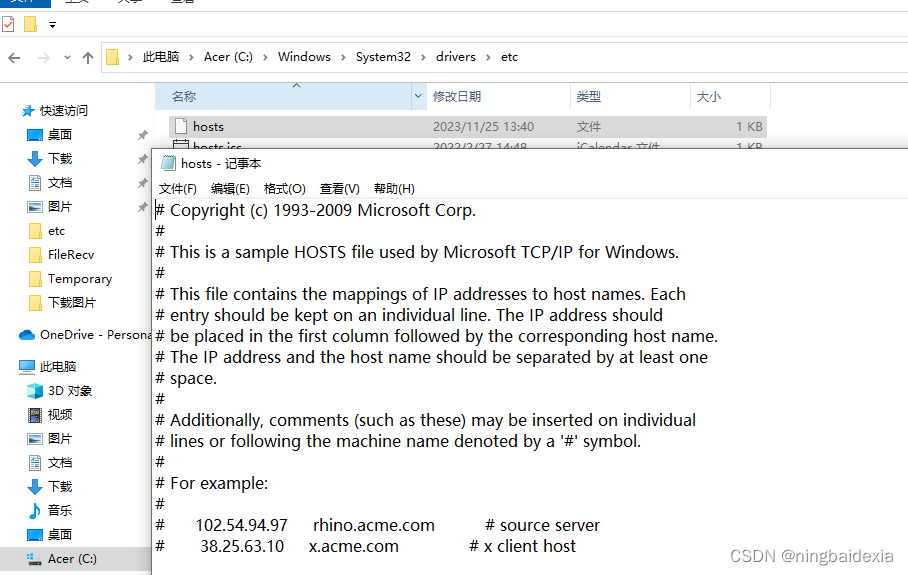
每一个域名对应一个IP地址 又有这么多网站
一旦新的网站出现 或者旧的网站下线 这里就需要修改 这显然是不可能的 所以有大佬专门把这些内容拿到专门的服务器里 把hosts文件装进去有新的网站注册 或者旧的网站注销都要去这里报备 这个服务器负责更新维护 在上网时 访问某个域名就会先访问到DNS服务器再获取到域名对应的ip
思考:全世界这么多主机上网 此时DNS服务器能承担这么高的并发吗?
两个原则
1.每个电脑上进行域名解析的时候 都会有缓存访问十次百度 只有第一次DNS 后面9次不一定访问
2.全世界会搭建很多NDS镜像服务器(一般是大厂或者运营商)此时访问镜像和访问别人的DNS服务器效果一样此时就把请求压力分摊开了 如果根域名服务器被破坏 就会让镜像服务器失效 直接上不了网
应用层 一方面需要自定义协议 一方面会用到一些现成的协议 HTTP就是最常用到的应用层协议
HTTP协议
现在最新时http3.0但是现在网络上仍然时1.1版本 2.0都少见
http超文本传输协议
文本 字符串
超文本(除了传输字符串还要图片视频音频)
http协议的工作过程
当我们在浏览器输入一个网址 此时浏览器就会给对应的服务器发送一个HTTP请求对方服务器收到请求之后 经过计算处理就会返回一个HTTP响应
HTTP响应 :这个响应的内容往往就是一个html内容 一个网站=前端(网页)+后端(HTTP服务器)
网页(HTML CSS JavaScipt)
网页都是在访问服务器的时候 从服务器下载到浏览器上然后才显示执行 其他应用程序一般都是先下载按照才能使用 网页时随时用随时下载
使用网页优势 服务器跟新用户就能用上新版本
劣势 性能有限很难提供一些复杂操作
学习HTTP协议格式 需要用到抓包工具(本质上是一个代理)
抓包工具就可以获取浏览器和服务器之间的交互细节(也就可以拿到http请求 和http响应中的具体细节) 抓包工具 是一种代理
代理不仅仅是抓包工具
vpn本质上也是代理
打游戏开加速器也是代理
还有代理程序代理服务器称为反向代理
代理客户端叫正向代理
代理服务器叫反向代理
抓包工具 wireshark 、fiddler
安装fiddler
当前机器上有哪些http数据报在交互
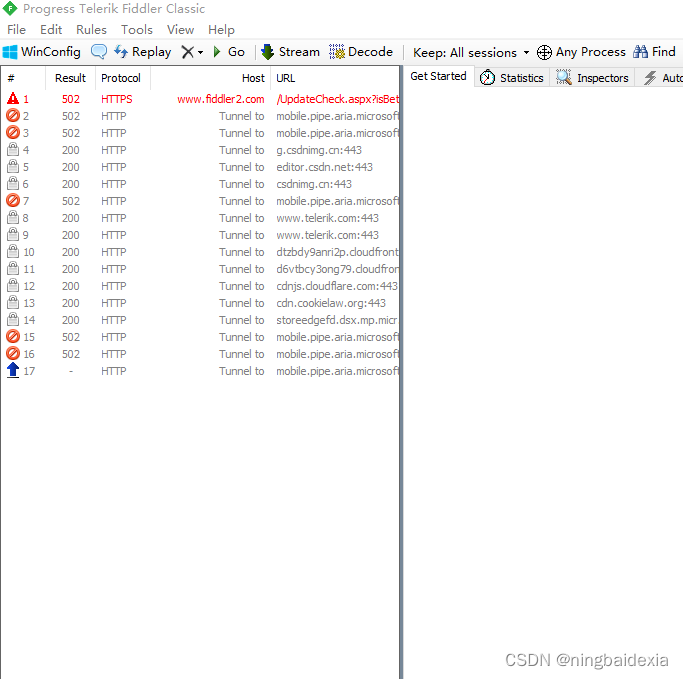
选中某个数据后右侧就能显示详细信息
右上角显示的是请求的详情
右下角显示的是响应的详情
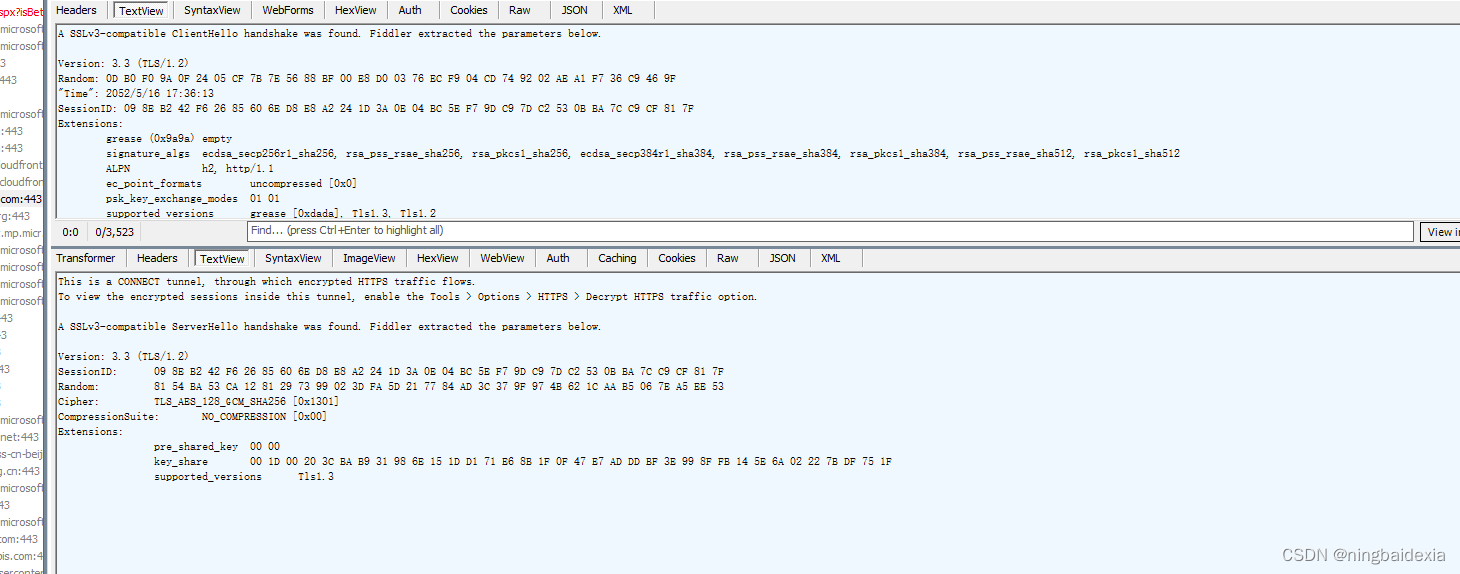
刚装好fiddler之后默认只能抓到http的数据抓不到https 所以我们要设置
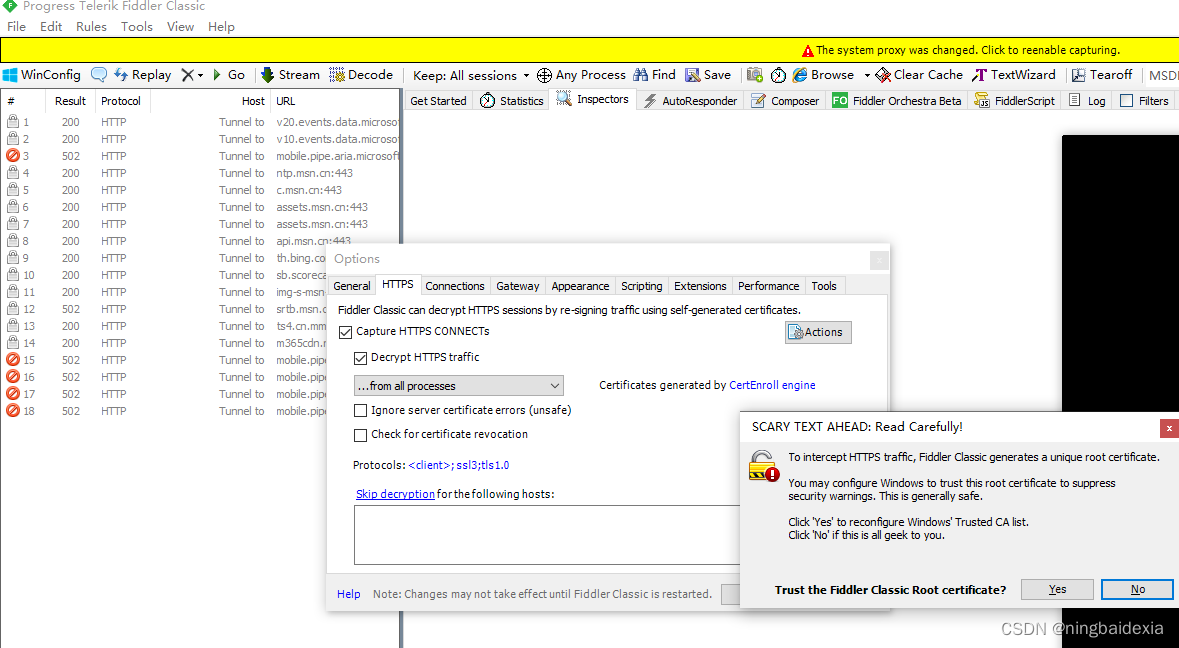
一路yes
https是加密的想要显示https的信息就需要对https进行解密操作 想要解密就需要fiddler提供的 “根证书”
我们就能抓取https的网站了
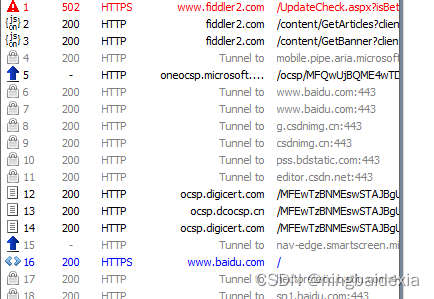
抓取百度主页的交互过程

主要使用的方式

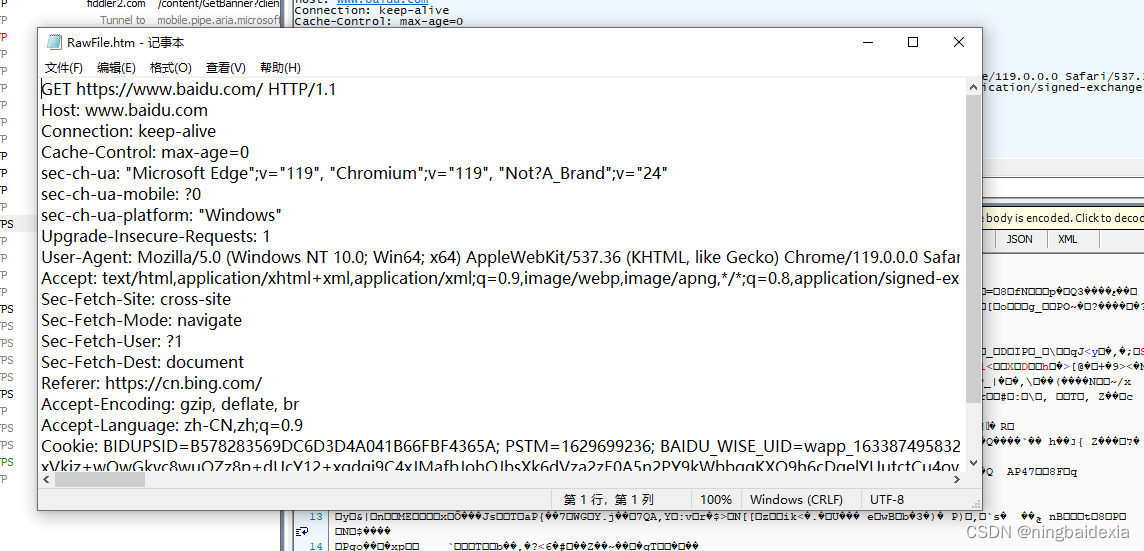
https请求详情
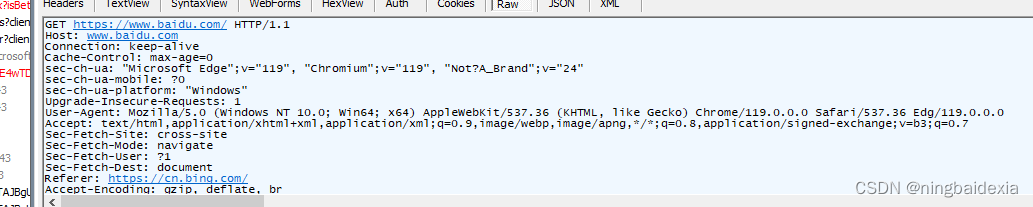
http是文本型 ip tcp udp是二进制型
可以用文本打开
响应详情
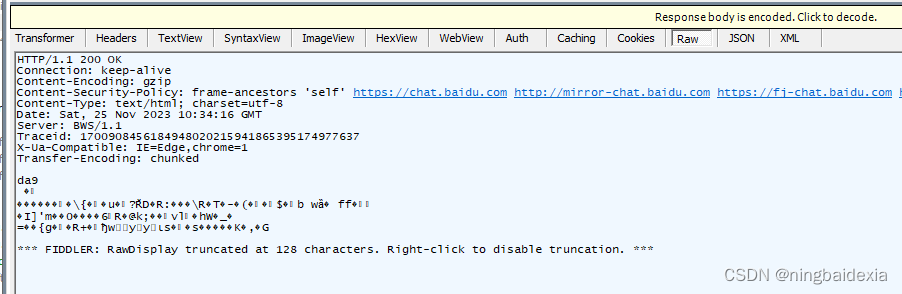
当前http的响应经常会进行压缩(节省带宽)响应可能会很大
所以下面会是乱码
点解解压就好了
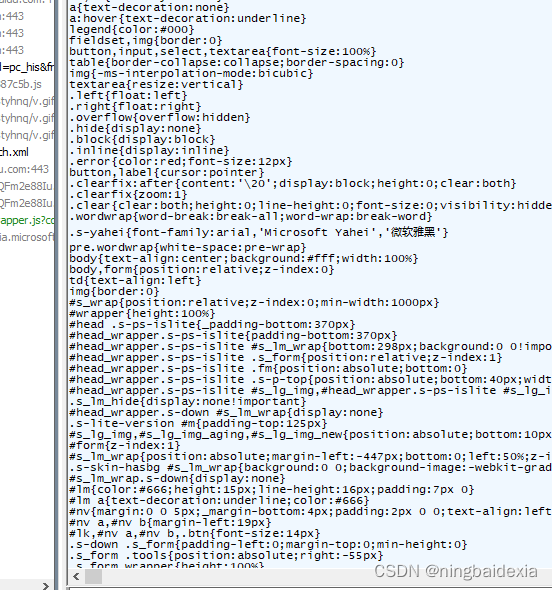
http响应的内容就是html css js

















 2571
2571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









