







 本文介绍了CVPR2019的Recurrent Back-Projection Network(RBPN)用于视频超分辨率。先总结主流Deep VSR做法,包括Temporal Concatenation、Temporal Aggregation、RNNs等。RBPN基于当前帧和邻居帧生成单帧SR图像,与DBPN思想相似,核心是残差学习。实验采用L1 Loss,分析多帧重建效果,不过模型运行较慢。
本文介绍了CVPR2019的Recurrent Back-Projection Network(RBPN)用于视频超分辨率。先总结主流Deep VSR做法,包括Temporal Concatenation、Temporal Aggregation、RNNs等。RBPN基于当前帧和邻居帧生成单帧SR图像,与DBPN思想相似,核心是残差学习。实验采用L1 Loss,分析多帧重建效果,不过模型运行较慢。
Recurrent Back-Projection Network for Video Super-Resolution - CVPR2019
1. Related Work
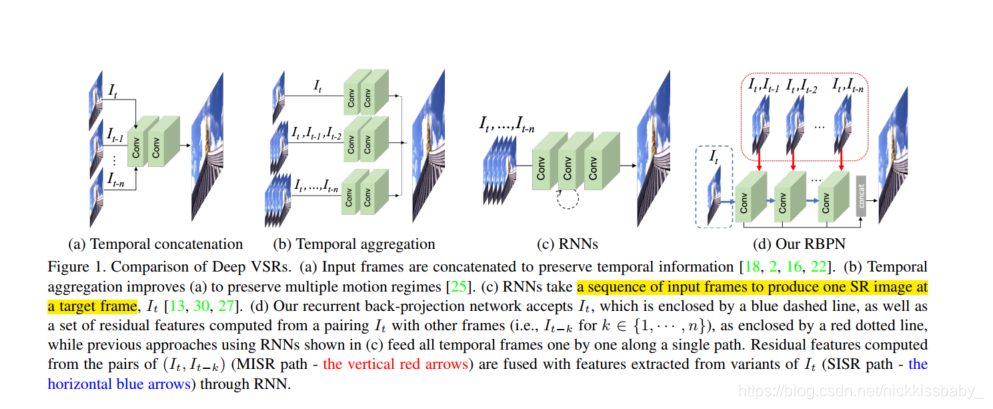
- 与DBPN论文一样,都是先总结并分类当前主流的SR做法。
- 主流的Deep VSR(video super-resolution)分为以下四种:
- Temporal Concatenation:送入网络前将frames直接concat起来
- Temporal Aggregation:将不同数量的帧(有些分路包含更多的邻居frame)丢进网络分路,最后输出前concat起来
- RNNs:frames迭代式地进入RNN,最后输出当前这一帧的输出
- 本文提出的RBPN
2. Method
- 首先RBPN是根据当前帧以及多个邻居帧生成当前帧的SR图像(multi frame->single frame),并不是multi frame -> multi frame
- RBPN与本文的兄弟paper图像超分辨率网络DBPN思想比较相似,核心都是残差学习。DBPN是根据浅层的特征来学习残差,RBPN是根据邻居帧以及两者的optical flow来学习残差
2.1 Network Architecture
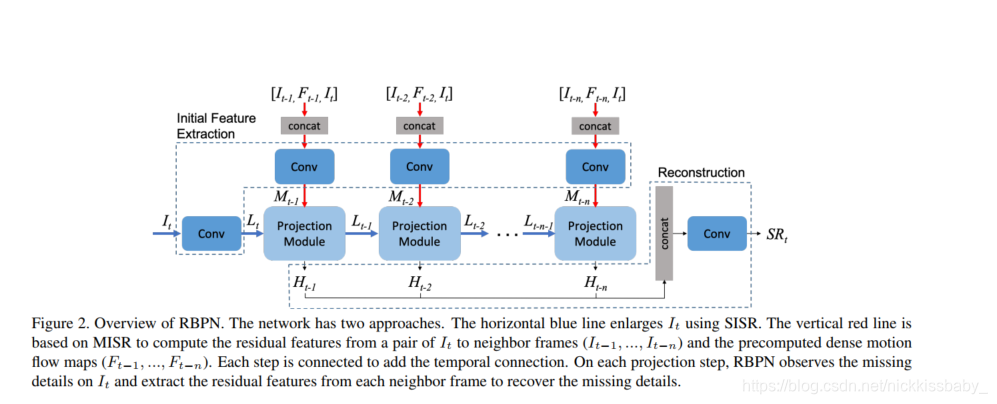
- 与DBPN类似,RBPN同样划分为三个stages:
- Initial Feature Extraction:对当前帧采用卷积层 I t I_t It进行特征提取,得到LR特征 L t L_t Lt。并concat当前帧 I t I_t It、邻居帧 I t − i I_{t-i} It−i、两者之间的optical flow图 F t − i F_{t-i} Ft−i,然后对concat起来的输入使用卷积层进行特征提取,得到Multi-frame特征 M t − i M_{t-i} Mt−i。其中 i = 1 , 2 , . . . , n i = {1, 2, ... , n} i=1,2,...,n。 n n n是一个超参数。上图中最后一个Projection Module的输入 L t − n − 1 L_{t-n-1} Lt−n−1应该写错了,应该是 L t − n + 1 L_{t-n+1} Lt−n+1,是t-n帧的后一帧t-n+1帧对应的Projection Module的输出 L t − n + 1 L_{t-n+1} Lt−n+1。
- Multiple Projections
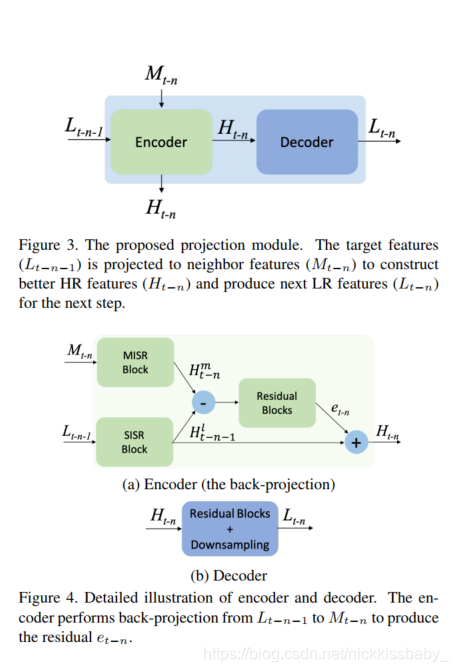
Multiple Projections 是一个Encoder-Decoder结构的Module。Encoder负责上采样,Decoder负责下采样。- Encoder:输入是 L t − n + 1 L_{t-n+1} Lt−n+1(图应该画错了)。 L t − n + 1 L_{t-n+1} Lt−n+1是上一个Projection Module的输出,结合了t-n+1 ~ t-1 帧以及他们与当前帧的optical flow,产生的LR特征图。通过对 L t − n + 1 L_{t-n+1} Lt−n+1使用SISR网络(single image super-resolution)产生HR特征原型 H t − n + 1 t H_{t-n+1}^t Ht−n+1t,然后使用Multi-Frame特征 M t − n M_{t-n} Mt−n产生multi-frame的HR特征 H t − n m H^m_{t-n} Ht−nm,两者相减得到残差,残差经过Residual Block得到学习后的残差 e t − n e_{t-n} et−n,与LR特征原型 L t − n + 1 L_{t-n+1} Lt−n+1相加,得出Encoder的输出HR特征 H t − n H_{t-n} Ht−n
- 为了利用更前一帧t-n-1与当前帧的Multi-Frame特征(LR的特征),需要将Encoder的输出HR特征 H t − n H_{t-n} Ht−n下采样得到LR特征 L t − n L_{t-n} Lt−n。这里使用了一个Residual Block以及下采样模块(我看得源码采用了max-pooling进行下采样)
- Resconstruction:把Projection Module中Encoder每次迭代中输出的HR特征全部concat起来,经过卷积层得出最终的SR图像
- 网络图中的Projection Module实际上只有一个,循环利用。每次向同一个Projection Module输入LR特征以及Multi-Frame的特征

3. Experiment
- 采用L1 Loss
- 分析采用多少帧过去的帧进行SR重建

可以看出,显然用更多帧进行预测时效果更好。
然而,我在跑这个模型的时候发现,这个模型非常的慢…6frame跑不起跑不起…3frame都难

















 2051
2051

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









