






导语
大家好,我是智能仓储物流技术研习社的社长,老K。
在做自动化立体仓库设计的时候,需要给土建设计院提供货架对地面的载荷要求。有些朋友碰到这个问题时不知道该如何计算,经常会求助于货架厂家,当然一般靠谱一些的货架厂家都能够提供相应的数据,但是一方面响应速度比较慢,无法及时的应答业主的问题;另一方面,如果不清楚计算方法也就无法评判拿到的数据有没有问题,心里始终没底。下面介绍一种简易的计算方法,只需要一个计算器就可以搞定了。
一般情况下,需要提出货架对地面的载荷有集中载荷和平均载荷两项:集中载荷是指每根立柱对地面的集中力,一般单位用吨来表示;平均载荷是指货架区单位面积内的承载力,一般用吨每平方米来表示。下面以最常见的横梁式货架为例介绍,托盘货物在货架上布置如下图所示:
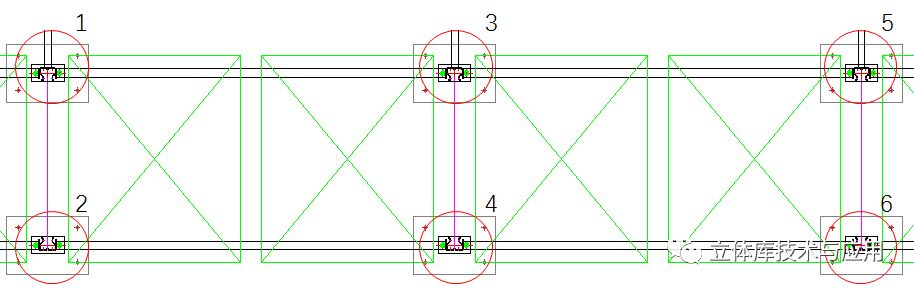
为了便于理解,图中截取了其中一层货架相邻两个货格的布置情况,每个货格放置两个托盘的货物。单元托盘货物的重量用D表示,两盘货物的重量就是D*2。以左边的货格为例,两盘货物的重量平均分摊到1、2、3、4四个立柱之上,因此每个立柱分摊的重量就是D*2/4=0.5D,然后我们再以3号立柱为例,除了左侧货格外,3号立柱与4、5、6一起还需要平均分摊右侧货格的两个托盘的重量,计算方法与左侧货格一致,分摊重量也是0.5D,因此3号立柱在这一层上的承载可以简化为一个托盘的重量。之后再数一下货架一共有几层,用单个托盘的重量乘以层数就是货架立柱的集中载荷了。
另外,除了货物重量外,货架自身也是有一定的重量的,这个可以根据经验值进行估算。一般标准托盘货架可以按照每个货位40kg估算,计算式用单个托盘的重量加上单个货位货架自重后再乘以层数就可以了。例如单元货物重700kg,货架总共有9层,那么每个立柱的集中载荷为(700+40)*9/1000=6.66t。
介绍完集中载荷后再来看平均载荷,我们划定某一个货格的投影区域如下图所示,区域长度和宽度分别用L和W表示。
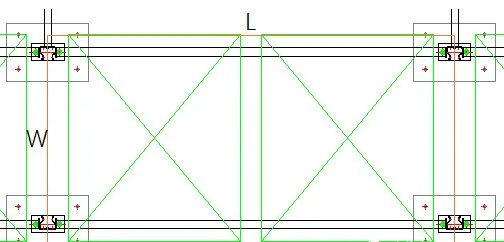
在投影面积之内每层货架上都有两个托盘的货物,再考虑上货架自身的重量,那么平均载荷就可以用两个托盘的重量加上两个货位货架的自重后乘以层数,然后除以投影面积即可。仍然按照单元货物700kg,货架9层为例,图中投影区域长度L按2.4m,W按1.2米计算,则平均载荷为((700+40)*2*9/1000)/(2.4*1.2)=4.625t/m2。
节选自立体库技术与应用,赵岩

智能仓储物流技术研习社
长按识别别关注

围绕厂内物流Intralogisitics,分享仓储物流自动化技术、设备、系统等知识,畅谈智能仓储物流的未来和去向。专栏包括智能仓储物流自动化规划设计,自动化立体库、智能机器人,自动化拣选系统,仓储管理软件WMS,AGV应用等等一系列热点内容。
您也可以扫描如下与社长老King取得联系。























 4279
4279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









