






1.基本思想
每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始(终止)位置,直到全部待排序的 数据元素排完 。
2.直接选择排序
1.思路
假设有一个含有n个元素的待排序数组,遍历一遍待排序数组,找出数组中最大的元素,将其与数组尾元素交换,然后继续遍历数组,这一次遍历(n-1)个元素,然后将最大的元素与数组倒数第二个元素交换,以此类推,直到遍历了n-1遍数组。
2.代码
#include <stdio.h>
void Swap(int* a, int* b)
{
int t = *a;
*a = *b;
*b = t;
}
void SelectSort(int arr[], int n)
{
for (int j = 0; j < n - 1; j++)
{
int maxi = 0;
for (int i = 0; i < n - j; i++)
{
if (arr[i] >= arr[maxi])
{
maxi = i;
}
}
Swap(&arr[maxi], &arr[n - j - 1]);
}
}
int main()
{
int arr[] = { 7, 6, 5, 4, 3, 2, 1, 9, 8 , 0};
int n = sizeof(arr) / sizeof(arr[0]);
for (int i = 0; i < n; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
SelectSort(arr, n);
for (int i = 0; i < n; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
return 0;
}3.优化
上面的直接选择排序,我们每遍历一遍数组,只选出了最大值,下面的代码是,我们遍历一遍数组把最大值和最小值都选出来,最大值与尾元素交换,最小值与首元素交换,以此类推,这样我们就可以只遍历n/2次就把数组排有序,当然每次遍历我们比较的变量多了一个。
#include <stdio.h>
void Swap(int* a, int* b)
{
int t = *a;
*a = *b;
*b = t;
}
void SelectSort(int arr[], int n)
{
int left = 0, right = n - 1;
while (left < right)
{
int mini = left, maxi = left;
for (int i = left + 1; i <= right; i++)
{
if (arr[mini] > arr[i])
{
mini = i;
}
if (arr[maxi] < arr[i])
{
maxi = i;
}
}
Swap(&arr[left], &arr[mini]);
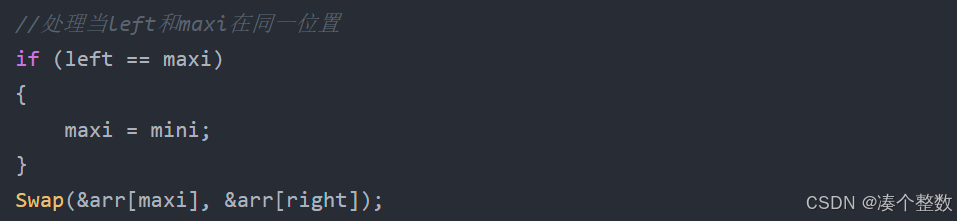
//处理当left和maxi在同一位置
if (left == maxi)
{
maxi = mini;
}
Swap(&arr[maxi], &arr[right]);
right--;
left++;
}
}
int main()
{
int arr[] = { 7, 6, 5, 4, 7, 3, 2, 1, 9, 8, 0};
int n = sizeof(arr) / sizeof(arr[0]);
for (int i = 0; i < n; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
SelectSort(arr, n);
for (int i = 0; i < n; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
return 0;
}
注意当我们每次遍历同时选出最大值和最小值时,会出现一种情况:maxi和left的位置重合

这时如果我们让mini和left元素交换后,直接继续交换maxi和right,就会出错,因为maxi位置已经不是最大值了
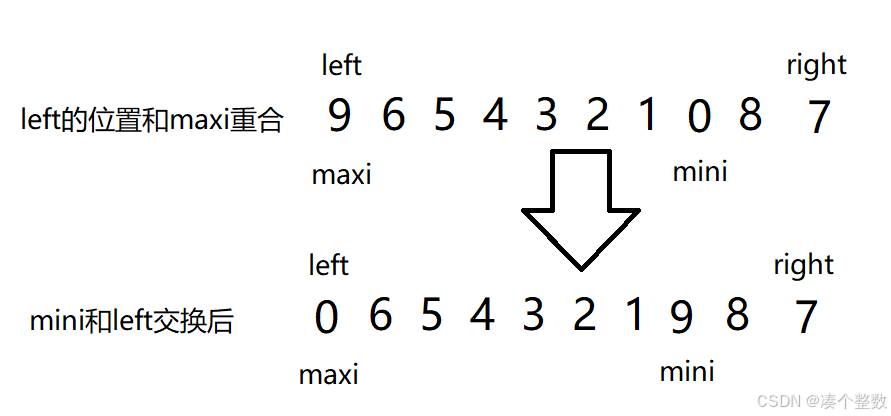
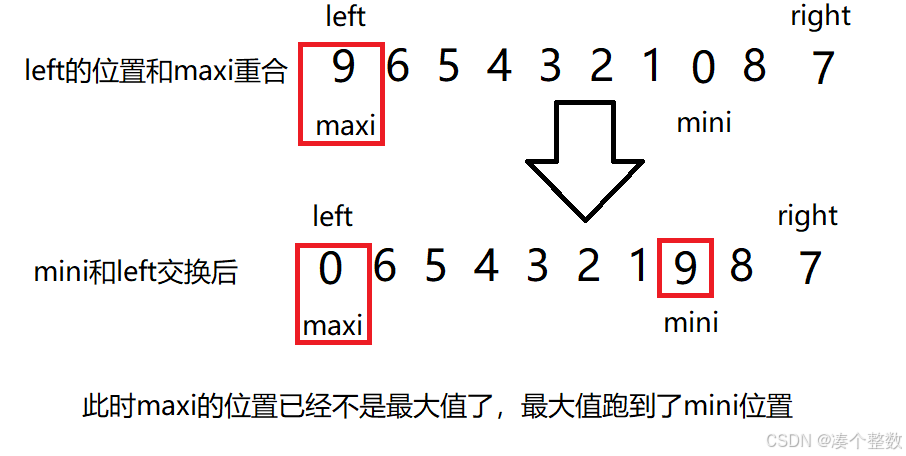
所以我们在交换后,判断left是否等于maxi,如果等于,我们就把mini的值赋给maxi,然后再交换maxi。
3.堆排序
1.定义
堆排序(Heapsort)是指利用堆积树(堆)这种数据结构所设计的一种排序算法,它是选择排序的一种。它是通过堆来进行选择数据。需要注意的是排升序要建大堆,排降序建小堆。
2.思路
首先我们有一个无序数组,在逻辑上我们把它抽象成堆
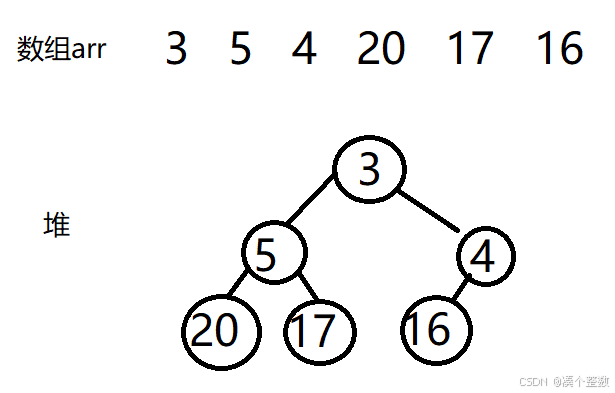
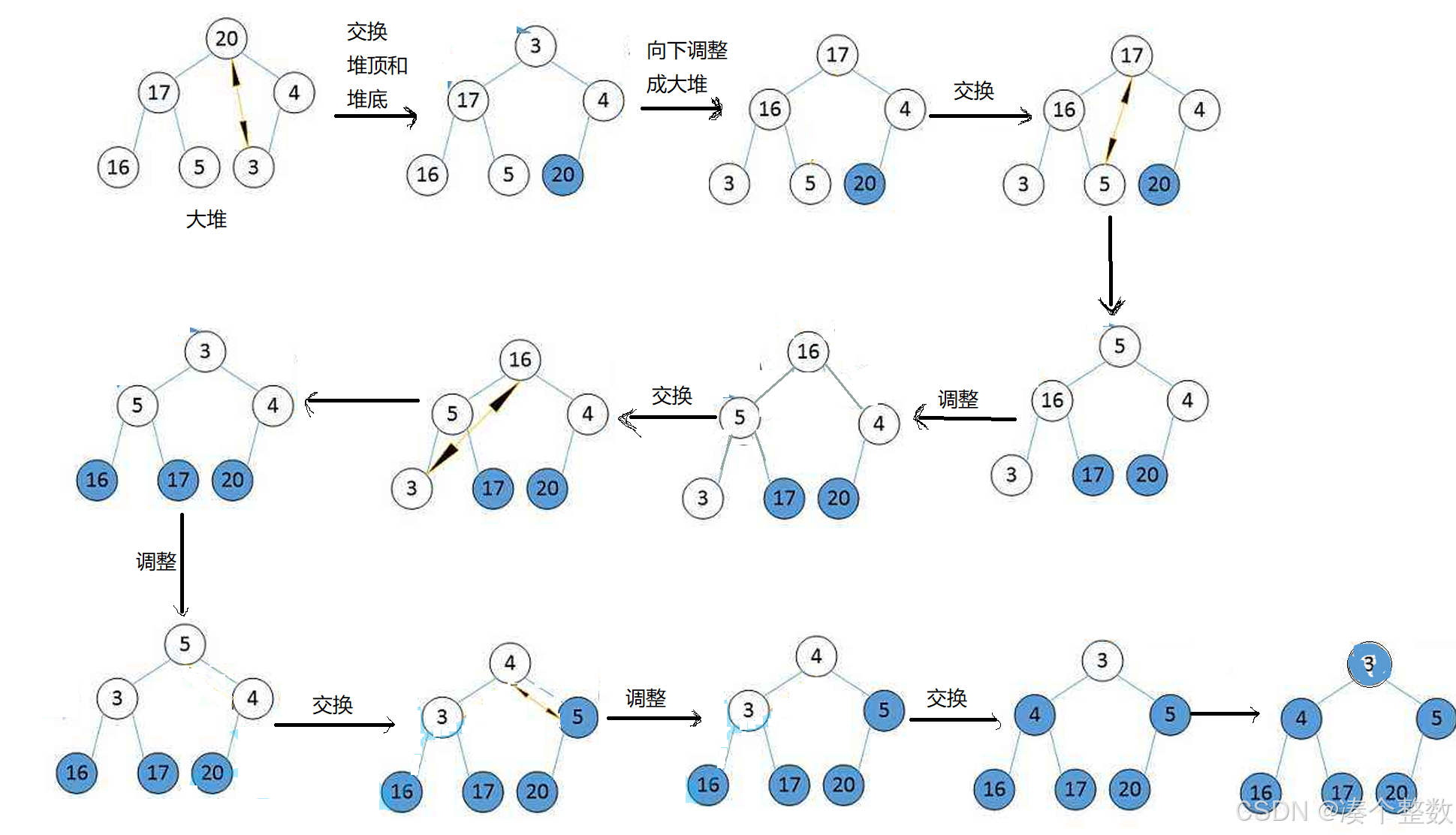
如果我们想把数组排为升序,那么我们需要先建个大堆,当它是大堆时,那么堆顶元素就是这组数据中的最大值,然后我们把堆顶元素和堆底最后的元素交换,堆在逻辑上是一个树形结构,但是它的本质还是数组,堆顶就是数组首元素,堆底最后元素就是数组尾元素,然后从上到下从左到右依次是数组的每个元素。当我们把堆顶元素和堆底最后的元素交换后,我们就是将数组最大值放到了数组的末尾位置,然后现在我们还要保证现在的堆是大堆,我们就要让堆顶元素向下调整,调整后我们得到大堆,然后再把堆顶元素和堆底元素交换,但是这次与堆底元素的交换,堆底元素不能是上一次得到的堆底元素,而是它的前一个元素。
3.代码
#include <stdio.h>
void Swap(int* a, int* b)
{
int t = *a;
*a = *b;
*b = t;
}
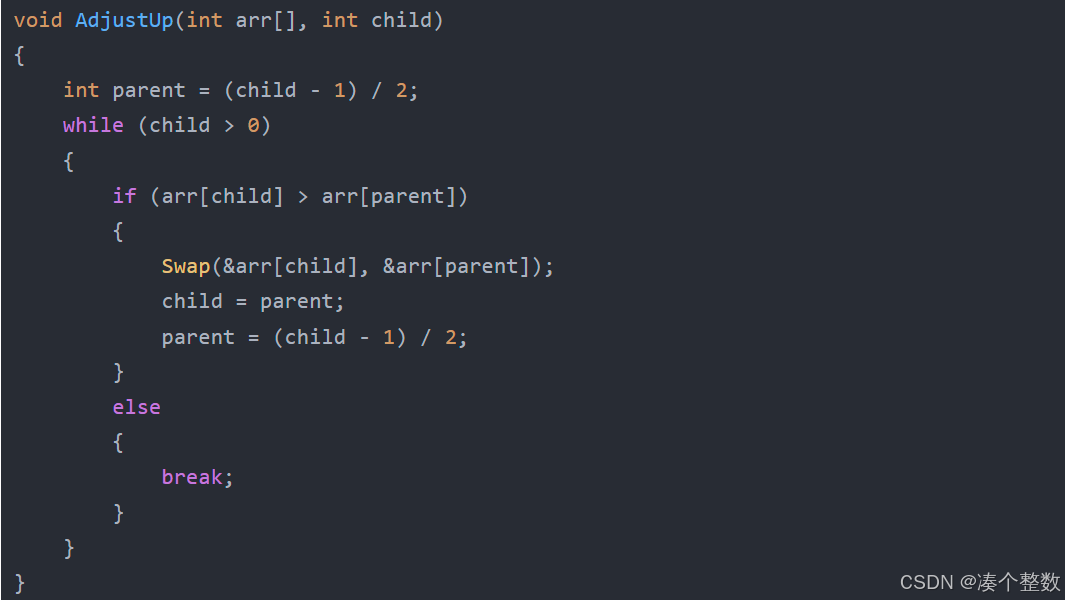
void AdjustUp(int arr[], int child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (arr[child] > arr[parent])
{
Swap(&arr[child], &arr[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
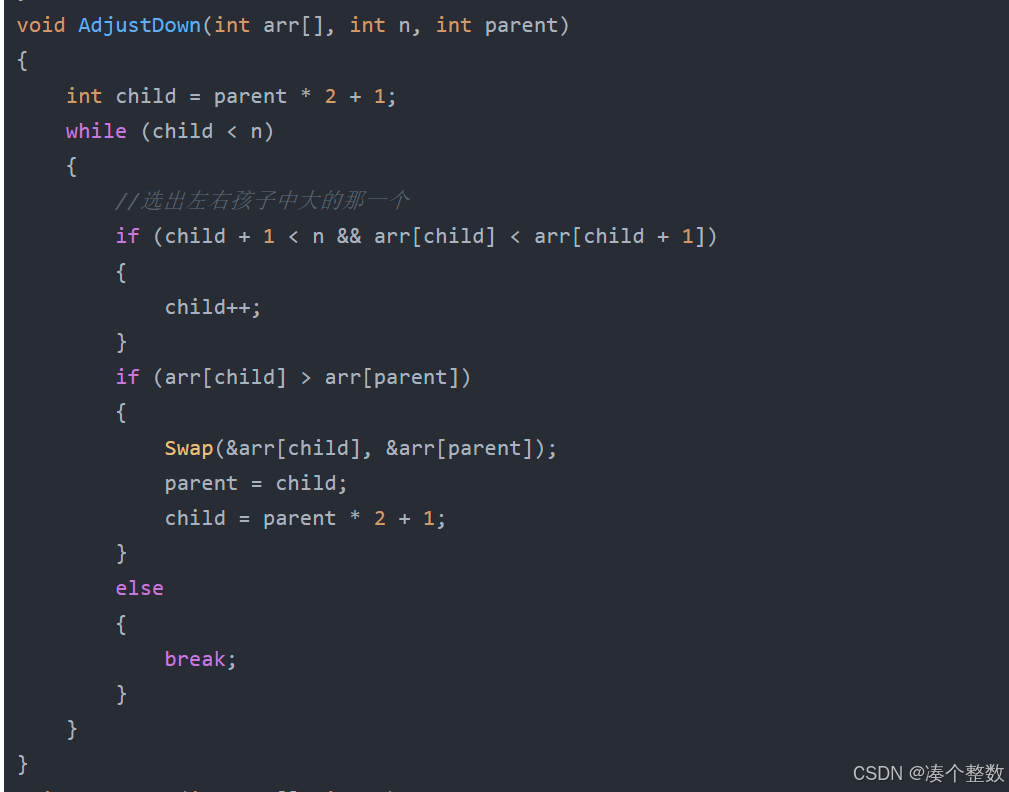
void AdjustDown(int arr[], int n, int parent)
{
int child = parent * 2 + 1;
while (child < n)
{
//选出左右孩子中大的那一个
if (child + 1 < n && arr[child] < arr[child + 1])
{
child++;
}
if (arr[child] > arr[parent])
{
Swap(&arr[child], &arr[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
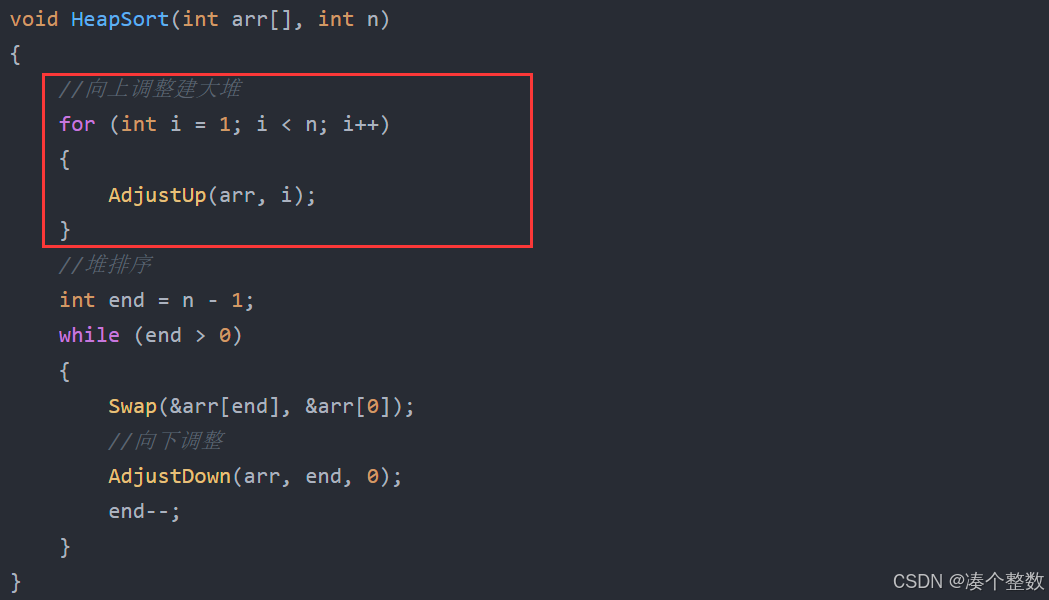
void HeapSort(int arr[], int n)
{
//向上调整建大堆
for (int i = 1; i < n; i++)
{
AdjustUp(arr, i);
}
//堆排序
int end = n - 1;
while (end > 0)
{
Swap(&arr[end], &arr[0]);
//向下调整
AdjustDown(arr, end, 0);
end--;
}
}
int main()
{
int arr[] = { 20, 4, 17, 3, 16 ,5 };
int n = sizeof(arr) / sizeof(arr[0]);
for (int i = 0; i < n; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
HeapSort(arr, n);
for (int i = 0; i < n; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
return 0;
}4.代码分析
1.向上调整建堆
首先在堆里有parent和child的概念,顾名思义,child就是parent的孩子
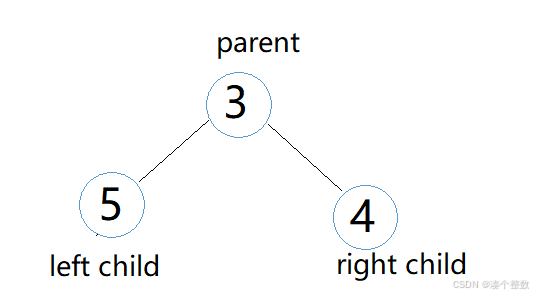
下面我们主要用到left child,所以我们直接把left child 称为child,然后我们来分析向上调整,假设有个数组:3,5,4,20,17,16。它的堆型结构如下
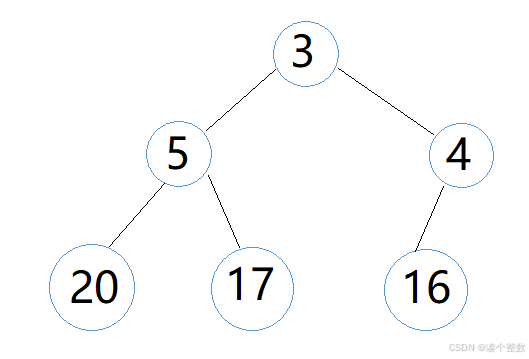
我们从这个堆的第二个元素开始,即‘5’要向上调整,此时‘5’就是child就,‘3’就是它的parent,然后比较child和parent的大小,如果child大于parent,我们就把child和parent交换,交换完成后,我们就对下一个元素进行向上调整,‘4’和‘3’元素同理,到‘20’时此时堆的结构如下
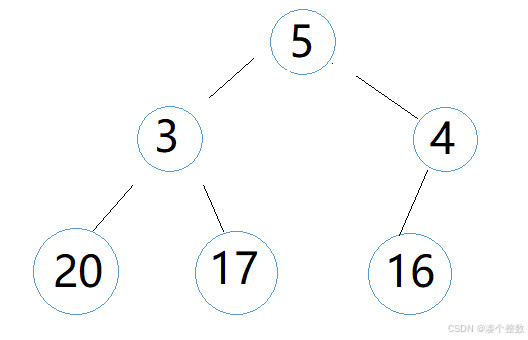
‘20’的parent是‘3’,‘20’>‘3’,交换‘20’和‘3’,交换后,注意此次向上调整还没结束,交换后的‘20’还要和新的parent比较,即‘20’和‘5’比较,‘20’>‘5’,交换‘20’和‘5’,这次交换后,元素‘20’的向上调整才结束,因为‘20’已经没有新parent,此时堆结果如下
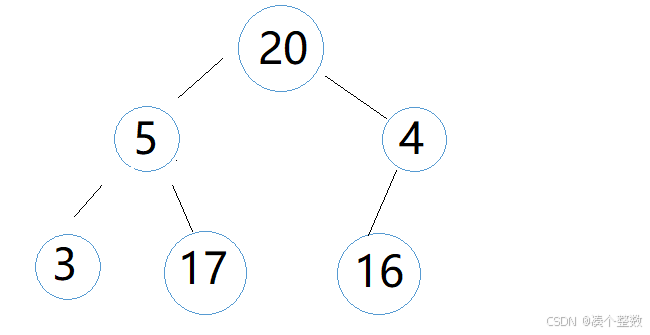
’20‘调整之后,轮到’17‘调整,以此类推,直到所有元素被调整一遍。
所有元素调整一遍后,此时的堆就成了大堆。
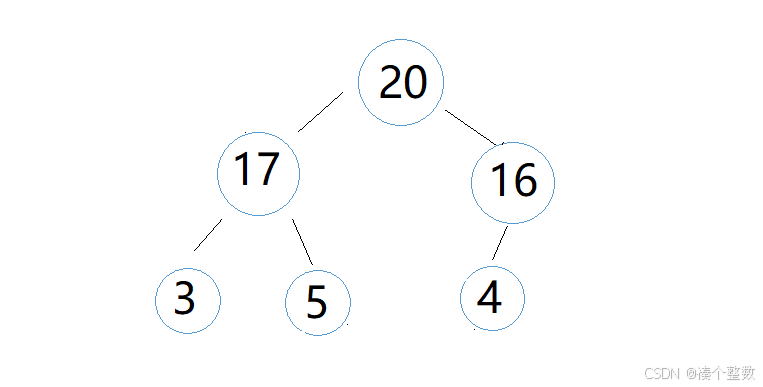
2.向下调整,调整堆
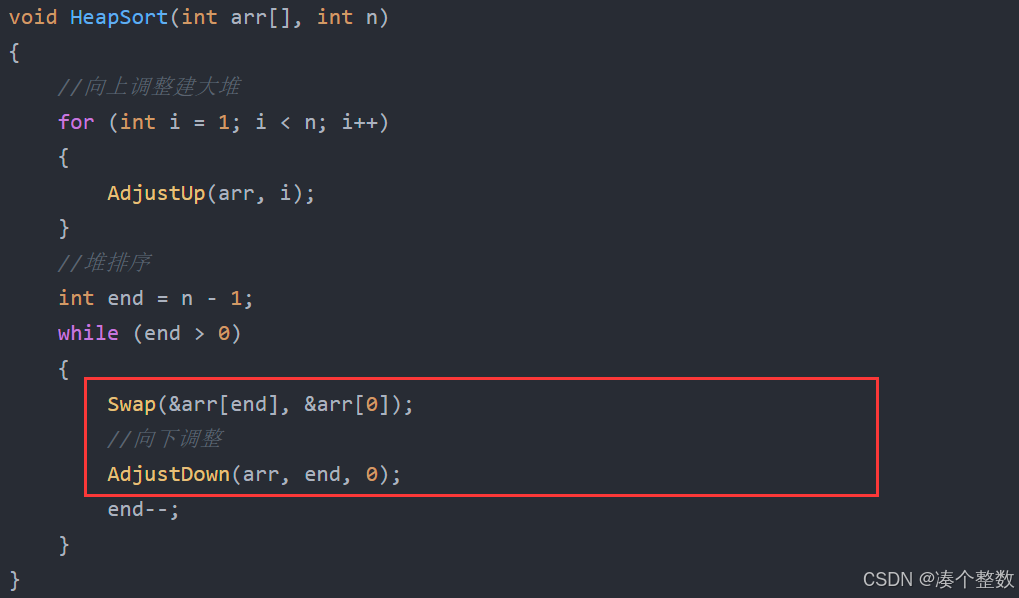
每次排好大堆交换堆顶和堆底元素后,堆就不再是大堆,但是它基本还是大堆,只是堆顶元素不满足大堆的条件,于是我们对堆顶元素进行向下调整
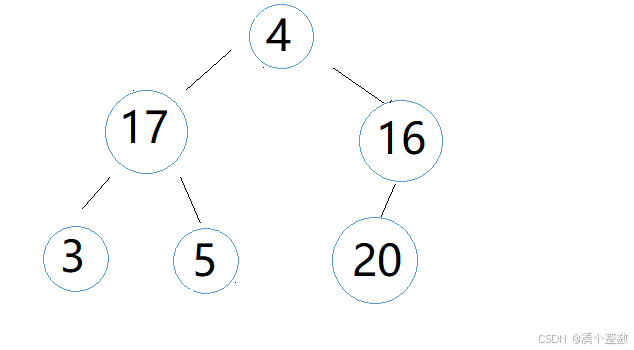
此时’4‘作为parent要和‘17’leftchild和‘16’rightchild比较,‘17’>'4',‘16’ > '4',那我们就把‘17’和‘4’交换,交换后,向下调整还没有结束,此时‘4’有新的child,我们还要把‘4’和新的孩子比较,即‘4’和‘3’leftchild和‘5’rightchild,因为‘4’<'5', '4' > '3',所以‘4’和‘5’交换,此时‘4’的向下调整结束,此时堆又变成大堆。堆结构如下
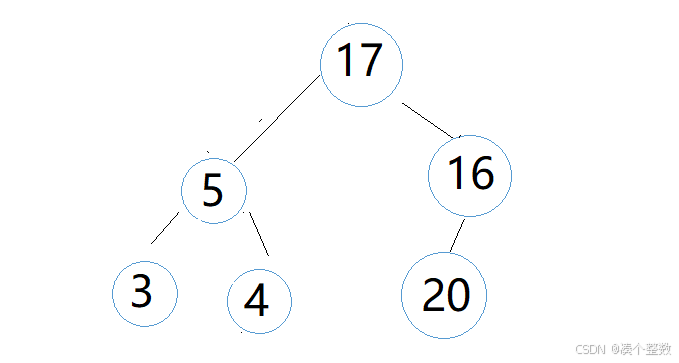
然后我们再将堆顶数据和堆底交换,循环往复,直到堆只有一个数据,此时就排好序了。
5.时间空间复杂度和稳定性
1.直接选择排序
1.时间复杂度:O(n^2)
普通的直接选择排序,一共要遍历n-1次,第一次遍历n个元素,第二次n-1个元素,第三次n-2等等等,最后求和为(n^2+n-2)/2,所以时间复杂度为O(n^2)
2.空间复杂度:O(1)
在直接选择排序中,随着数据规模的不断变大,交换的次数也会变多,Swap函数调用产生的t变量次数也会增加,但是,每次调用完Swap后t变量的空间都会被释放,然后下一次再重新定义t,每次调用完都会被释放,所以虽然调用的多,但是被释放了。所以空间复杂度为O(1)。
3.稳定性:不稳定
按理来说:在每次遍历选取最大值时,如果遇到相等的值,会选着靠后的,所以直接选择排序不会改变值相等的元素在初始数组的相对位置。
但是下面这种情况,当我们选出小的‘1’时,我们与序列第一个‘2’交换位置,交换后,序列中两个而得相对位置就发生了改变,所以在这种情况下,选择排序不稳定。
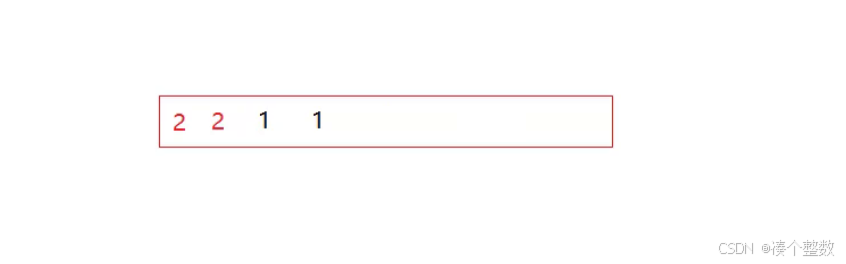
2.堆排序
1.时间复杂度:O(nlogn)
首先堆排序,最开始建堆需要消耗时间,如果我们用向上调整建堆,那么建堆消耗时间为:(n*logn)。
建完堆后,后面我们每次将堆顶与堆底元素交换后,都要进行一次向下调整,每次向下调整的最多(最差情况)次数,就是logn,换句话说,最差的情况是,有几层我们就要将这个元素向下换几次位置。然后我们要将堆顶和堆底数据交换(n-1)次,每次交换后都要向下调整建堆,所以消耗时间为:(n-1)logn
总的时间为(n*logn)+(n-1)logn,所以时间为:2*nlogn,所以时间复杂度为O(nlogn).
如果我们建堆时用向下调整建堆,那么建堆消耗的时间为:N - logn,但最后整个堆排序的时间复杂度是一样的,都是:O(nlogn)
2.空间复杂度:O(1)
堆排序过程中,随着数据量的增大,建堆或调整堆时,调用Swap函数的次数增多,但是每次调用完后,都释放了,所以总的来开,堆排序中,的空间消耗,就是几个固定的循环变量,和交换时用到的t,虽然会多次创建,但每次交换完后就会立马被销毁,所以空间的消耗是常量级的,即O(1)。
3.稳定性:不稳定
堆排序时,值相等的数据,在一次又一次交换中,他们的相对位置会改变。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









