




 本文详细介绍了MySQL优化的方法,包括外部缓存技术和内部优化措施。深入探讨了InnoDB、MyISAM和Memory三种存储引擎的特点及适用场景,并提供了索引创建、使用原则等方面的指导。
本文详细介绍了MySQL优化的方法,包括外部缓存技术和内部优化措施。深入探讨了InnoDB、MyISAM和Memory三种存储引擎的特点及适用场景,并提供了索引创建、使用原则等方面的指导。
mysql优化
概述
1.外部优化:
运用缓存技术,减少数据库的查询,如radis,memcache等
2.内部优化:
选用合适的存储引擎,innodb,myisam,memory等
数据表设计满足三范式
数据表字段选择合适的结构,varchar,int,text等
对常用的操作建立存储过程
sql语句优化
建立合适的索引
对于查询和写入频率差距大的数据库,建议读写分离
数据库引擎学习
Innodb
- 存储格式:
每个数据表有单独的“结构文件” *.frm;数据,索引集中存储于同一个表空间文件中ibdata1,这种行为可以通过配置‘innodb_file_per_table’这个变量来改变 set global innodb_file_per_table=1;
- 插入数据会进行默认排序,效率低 (会按主键进行排序)
- 并发性支持较好
- 对事务支持较好
- 行锁 (row-level-locking)与表锁均支持
- 数据备份与还原
不能直接备份,需要通过命令 mysqldump -u用户 -p密码 数据库名 > 备份文件路径名(如:d:/backup.sql)
还原操作:mysql -u用户 -p密码 数据库名 < 备份文件路径名
MyISAM
- 存储方式:
数据,索引,结构分别存储在不同的文件中。每个数据表都有三个文件 *.frm *.MYD *.MYI (表结构,数据文件,索引文件)
- 备份与还原:
数据文件支持物理复制,粘贴操作(直接备份还原)
- 表锁
- 对事务支持性不如innodb
- 所存即所得,插入时不会进行默认排序
Memory (内存存储引擎)
特点: 内部数据运行速度非常快,临时存储一些信息
缺点: 服务器如果断电或者重启,就会清空该存储引擎的全部信息
重启后,数据消失
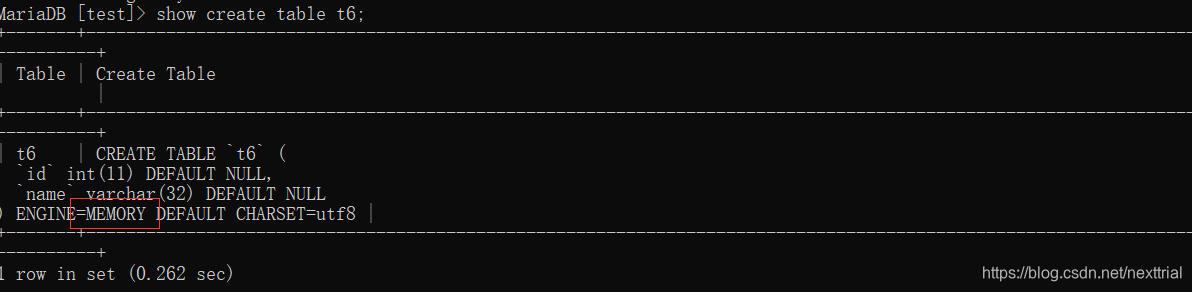
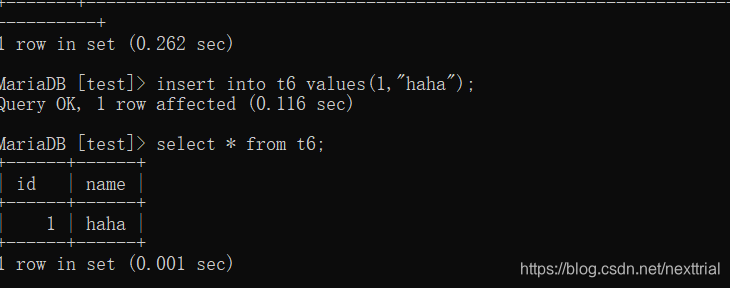
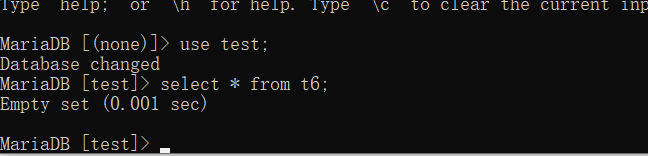
查找需要优化的语句
使用慢查询日志 (记录所有执行时间超过某个时间界限的sql语句)
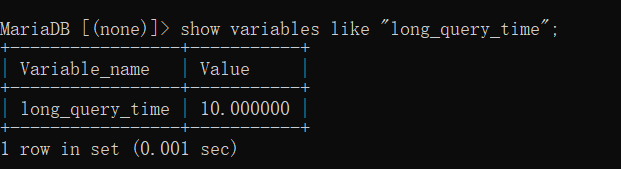
方式一 临时启动慢查询记录日志
bin/mysqld --safe-mode --slow-query-log
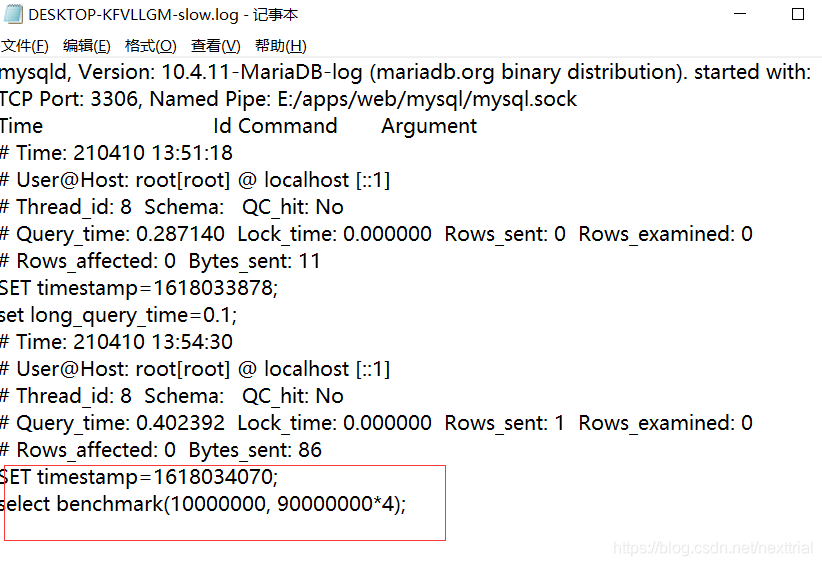
测试:使用benchmark [select benchmark(10000000, 90000000*4)]
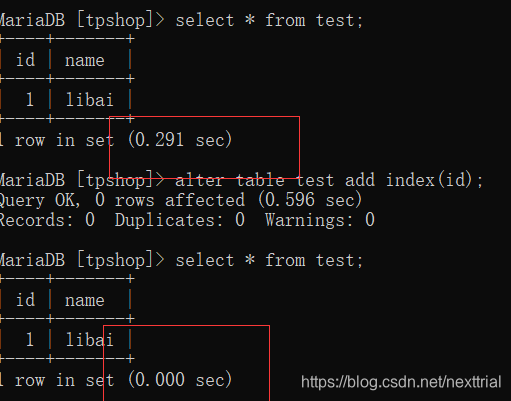
一般情况下,查询慢,是没加索引,添加索引 alter table 表名 add index(索引字段)
方式二 修改配置文件
log-slow-queries=‘e:/slow-log’
long_query_time=0.5
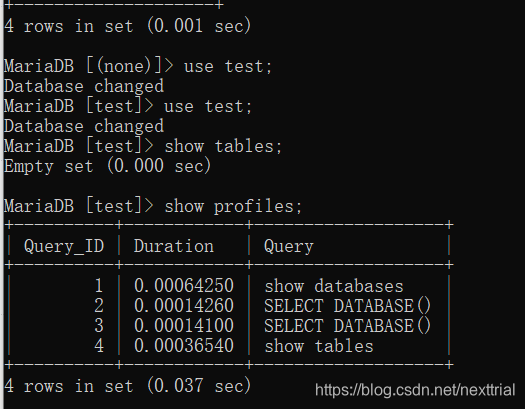
使用profile机制
开启 set profiling=1;
查看
索引讲解
利用关键字,建立与记录位置的一个对应关系。是独立于数据的一种特殊的数据关系。
类型:主键索引(primary key),唯一索引(unique key(字段)),普通索引(index(字段)),全文索引 (fulltext index(intro)),联合索引(index(字段1,字段2))
创建索引:
alter table text2 add index(name), add unique key(age), add fulltext index(intro);
alter table text1 drop index index_name;
去除主键索引时,如果主键id有auto_increment属性,则应当先删除该属性
alter table text modify id int not null;
查看索引
show indexes from table
创建索引注意事项
- 较频繁的作为查询条件的字段应该创建索引
- 唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件
- 更新非常频繁的字段不适合创建索引
- 不会出现在WHERE子句中的字段不该创建索引
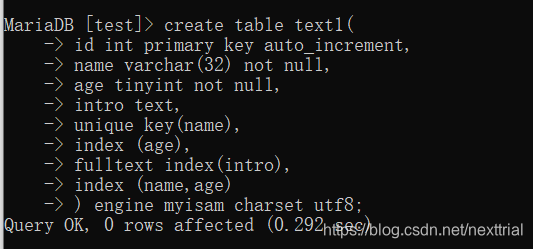

索引的数据结构
1.myisam的存储引擎索引结构
索引的节点中存储的是数据的物理地址(磁道和扇区)
2.innodb的存储引擎的索引结构
innodb的主键索引文件上,直接存放该行数据,称为聚簇索引,非主键索引指向对主键的引用(非主键索引的节点存储的是主键的id)
索引覆盖
就是说如果查询的列恰好是索引的一部分,那么查询只需要在索引区上进行,不需要到数据区再找数据,这种查询速度非常快。
负面影响,增加了索引的尺寸;
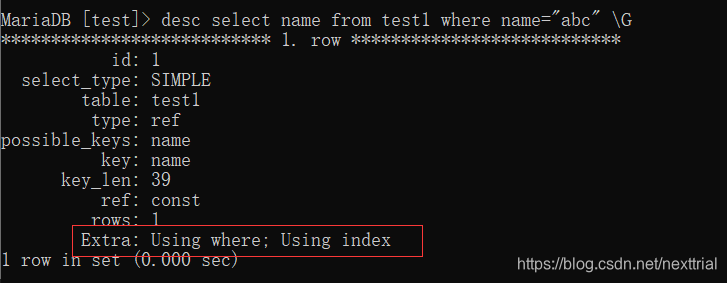
索引的使用原则
1.列独立性原则:索引字段在=号左右单独存在 如 where age-1 = 10; 就违背了列独立性原则,不会使用到索引
2.like查询时, 以%开头的like查询不会使用到索引
%在右边时,会使用到索引
3. or 运算 需要or两边的字段都具有索引,才会使用到索引
而当使用id与name时,因为两个字段都有索引,所以在查询中使用了索引
4.复合索引 当查询时,使用了最左边的字段是,就会使用到索引,for example:
test1表中有复合索引index(name,age), name在最左边,当只使用age来查询时
当使用name来查询时,使用到了索引
注:在多列查询中,如果有多个查询条件,要想查询效率比较高, 要保证最左边的列用到索引
mysql会智能选择,如果使用索引会比实地查询慢,则mysql会放弃使用索引。
5. 优化group by语句
mysql默认会对group by查询结果排序
这会增加开销,如不想让其排序,在语句后加order by null;
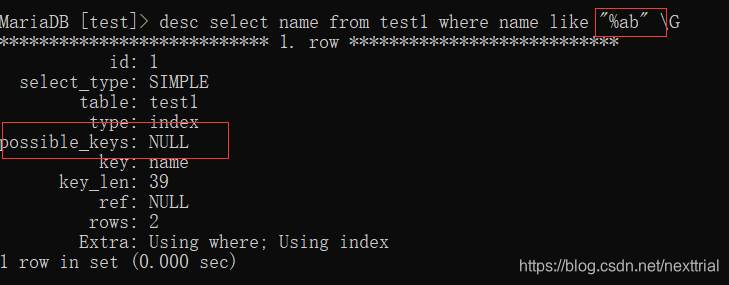
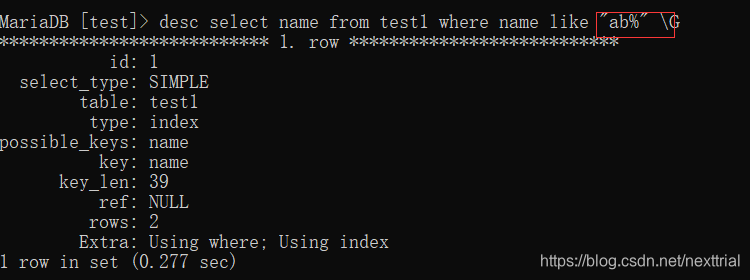
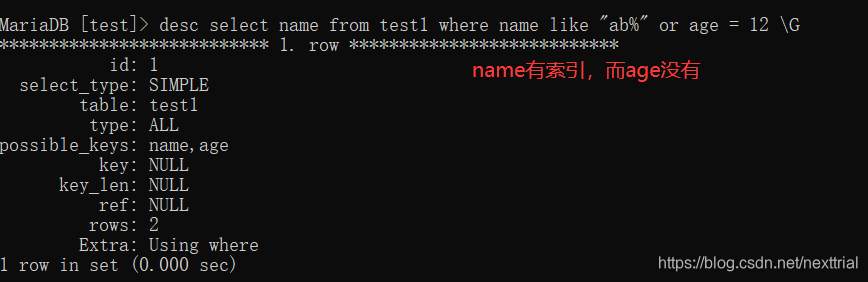
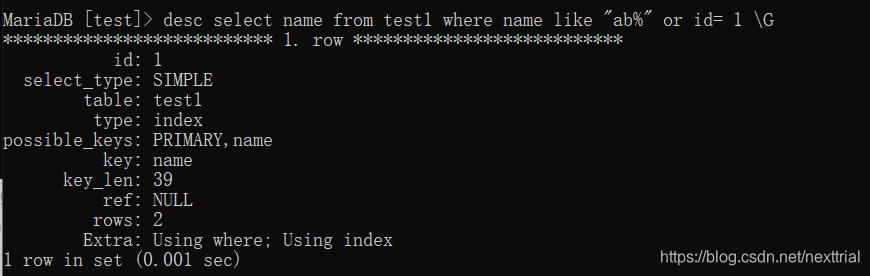
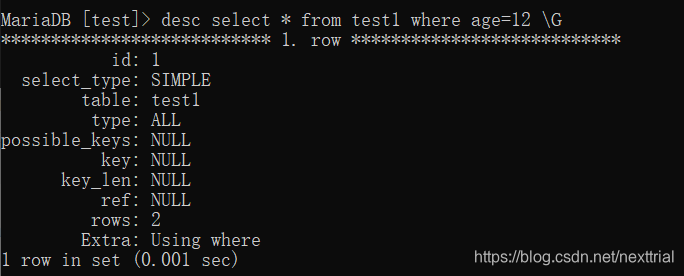
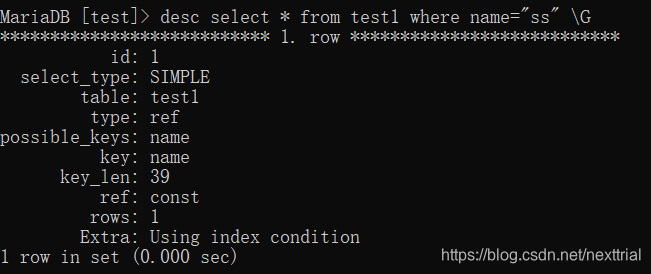
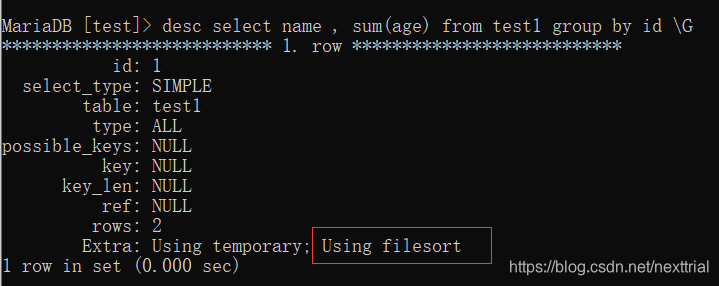
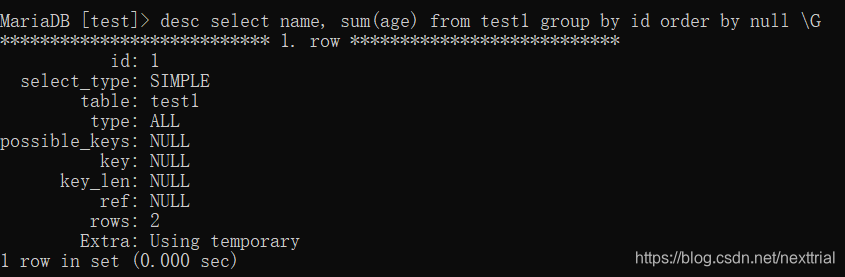
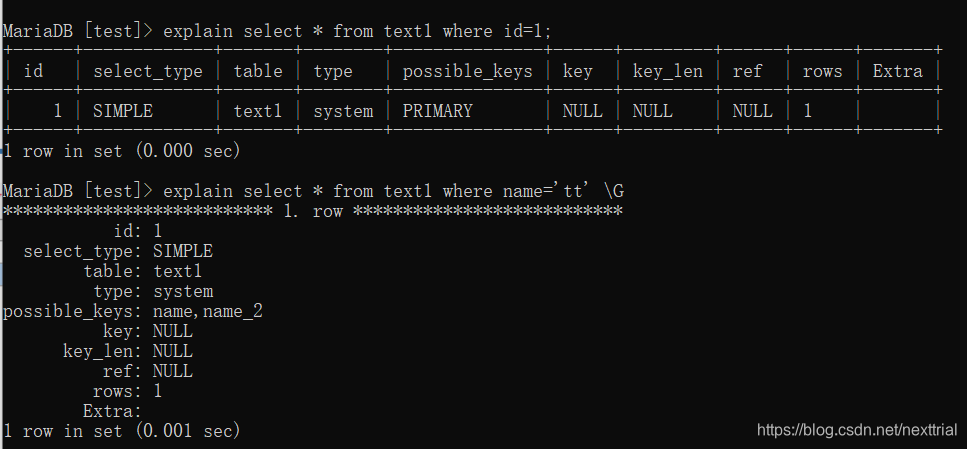
执行计划 【查看索引的使用情况】
explain sql语句 \G (行列转换)

















 2192
2192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









