




 本文介绍了MySQL中的锁机制,包括读锁与写锁的特点及应用,行锁与表锁的区别,以及如何添加和释放锁。此外,还探讨了查询缓存的使用方法,以及分区技术的基本概念与语法。
本文介绍了MySQL中的锁机制,包括读锁与写锁的特点及应用,行锁与表锁的区别,以及如何添加和释放锁。此外,还探讨了查询缓存的使用方法,以及分区技术的基本概念与语法。
锁
分类
按操作分类
1.读锁:也叫共享锁,S-lock。特征是所有人都只可以读,只有释放锁之后才可以写。
2.写锁:也叫独占锁,X-lock。特征,只有锁表的客户可以操作这个表,其他客户不能操作(包括读)
按锁定粒度
1.表级锁:开销小,加锁快,发生锁冲突的概率最高,并发度最低
2.行级锁:开销大,加锁慢,发生锁冲突的概率最低,并发度也最高
添加锁与释放锁(表锁)
添加
lock table table_name1 read | write, table_name2 read | write

释放
unlock tables
? 为何释放锁是用unlock tables;
注:添加表的锁定后,针对锁表的用户,只能操作锁定的表,不能操作没有锁定的表。
行锁
innodb 存储引擎是通过给索引上的索引项加锁来实现的,这就意味着:只有通过索引条件检索数据,innodb才会使用行级锁,否则,innodb使用表锁
语法:begin; 执行语句; commit;
非索引执行过程中,innodb会使用表锁,另一端无法写入


mysql中的锁不好用,如果某个进程挂了,锁没有及时释放,会导致其他人的使用
使用php测试下 用flock加锁
public function test1(){
$file_path = $_SERVER["DOCUMENT_ROOT"] . "/sys.log";
$handler = fopen($file_path,'w');
flock($handler, LOCK_EX);
$res = DB::select("select id from t1");
$id = $res[0]->id;
$id++;
DB::update("update t1 set id = ?", [$id]);
flock($handler, LOCK_UN);
}
ab -n 50 -c 50 http://www.laravel.com/test1
查询缓存的使用
mysql服务器提供的,用于缓存select 语句结果的一种内部缓存系统
如果开启了查询缓存 ,将所有的查询结果,都缓存起来,使用同样的select语句,再次查询时,直接返回缓存的结果即可
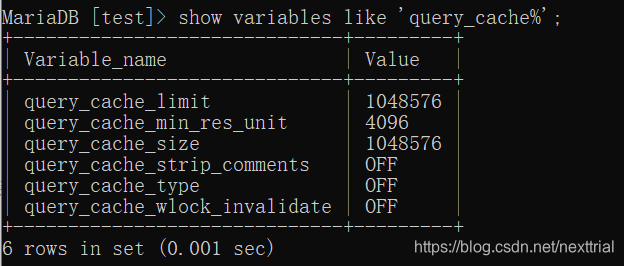
show variables like ‘query_cache%’ //查看缓存使用情况
query_cache_type :是否开启缓存
在mysql.ini中配置
query_cache_type=1
show status like ‘Qcache%’ //查看缓存空间使用情况
只要对应数据有变化,缓存就会失效
当sql语句中有变化语句时,就不会使用缓存,如:select name, now() as time from test where id = 1; select * from emp order by rand() limit 4;注:生成缓存的sql语句对大小写,空格敏感,会认为是不同的sql语句,生成的缓存也不同。
如:select * from t1 where id = 1; 与 select * from t1 WHERE id=1
禁用缓存
select sql_no_cache * from emp where empno = 1;表示当前查询不使用缓存

分区技术
基本概念
把一个表,从逻辑上分成多个区域,便于存储数据。采用分区的前提,数据量非常大。
查看当前mysql软件是否支持分区
show variables like “%partition%” 或 show plugins;
语法
注:如果表中有主键或唯一索引,分区字段必须是主键或唯一索引的一部分
create table table_name(
字段信息,
索引
) engine engine_name charset charset_type
partition by 分区算法 (分区字段)(
分区选项
);
分区算法:
1.list分区(条件值为一个数据列表)
如一个学生信息表,表中有班级号class_id作为外键。有东南西北4栋教学楼,则可根据每栋楼所含的班级号列表,对学生表进行分区。说白了,就是针对某个字段,进行分类。每一个类别中涵盖这个字段的一系列数值。
create table students (
id int,
name varchar(32),
class_id int
)engine myisam charset utf8
partition by list (class_id) (
partition c_north values in (1,4,6,7,9),
partition c_east values in (2,8,11,14),
partition c_south values in (3,5,10,12,13),
partition c_west values in (15,16,17,18,19)
);

注:在使用分区时,where后面的字段必须是分区字段,才能使用到分区(效率更高)
2. range分区

create table p_range(
id int,
name varchar(32),
birthday date
) engine myisam charset utf8
partition by range (month(birthday)) (
partition p_1 values less than (4),
partition p_2 values less than (7),
partition p_3 values less than (10),
partition p_4 values less than MAXVALUE
);
注:less than 小于 MAXVALUE 可能的最大值 range比之list ,就是字段分类的方式不一样
3. hash分区create table p_hash( id int, name varchar(20), birthday date ) engine myisam charset utf8 partition by hash (month(birthday)) partitions 5;4.key (键值)同hash,是hash的一种延伸
分区管理
- 删除分区
在key/hash领域不会造成数据丢失(删除分区后数据会重新整合到剩余的分区去)
alter table 表名 coalesce partition 数量 【表示删除多少个分区】
注:剩余一个分区的时候,就禁止删除了,但是可以drop掉整个数据表
在range/list领域会造成数据丢失
alter table 表名 drop partition 分区名称
- 增加分区
key/hash :
alter table 表名 add partition partitions 数量range/list:
alter table 表名 add partition( partition partition_name values less than (常量) 或 partition partition_name values in (n1,n2,n3,...,)

















 546
546

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









