






LangChain 中处理文档的完整流程(Load → Embed → Document Transform → Vector Store → Retriever)。这些步骤构成了基于文档的检索增强生成(RAG, Retrieval-Augmented Generation)系统的核心。下面将逐一解释每个概念,并提供详细的代码示例。
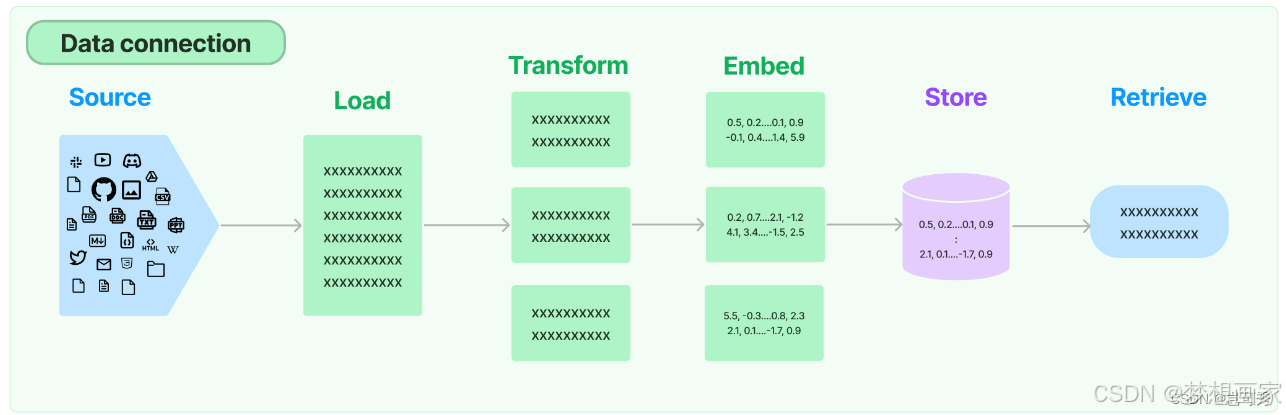
1. Load(加载文档)
定义:
Load 是指从不同来源(如本地文件、网页、数据库等)加载原始文档到 LangChain 中。LangChain 提供了多种 Document Loader 来支持这一过程。

示例:
使用 TextLoader 加载本地文本文件,或使用 WebBaseLoader 加载网页内容。
from langchain.document_loaders import TextLoader, WebBaseLoader
# 示例1:加载本地文本文件
local_loader = TextLoader("example.txt")
local_docs = local_loader.load()
# 示例2:加载网页内容
web_loader = WebBaseLoader(["https://example.com"])
web_docs = web_loader.load()
print("Loaded documents:", local_docs[0].page_content[:100] + "...")
2. Embed(嵌入)
定义:
Embed 是将文本转换为高维向量(Embedding Vector)的过程,以便后续的语义搜索。LangChain 支持多种嵌入模型(如 OpenAI、Hugging Face 等)。
示例:
使用 OpenAI 的嵌入模型将文本转换为向量。
from langchain.embeddings import OpenAIEmbeddings
# 初始化嵌入模型
embeddings = OpenAIEmbeddings()
# 将单条文本转换为向量
text = "Hello, world!"
embedding_vector = embeddings.embed_query(text)
print("Embedding shape:", len(embedding_vector)) # 输出向量维度(例如 1536)
# 批量转换文档
doc_texts = [doc.page_content for doc in local_docs]
doc_embeddings = embeddings.embed_documents(doc_texts)
3. Document Transform(文档转换)
定义:
Document Transform 是对原始文档进行预处理,例如分割长文本为短块(chunks)、过滤无关内容等。常用工具是文本分割器(Text Splitter)。
示例:
使用 RecursiveCharacterTextSplitter 分割文档。
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 定义文本分割器
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 每个块的最大长度
chunk_overlap=50 # 块之间的重叠长度
)
# 分割文档
split_docs = text_splitter.split_documents(local_docs)
print("Number of chunks:", len(split_docs))
print("First chunk:", split_docs[0].page_content[:100] + "...")
4. Vector Store(向量存储)
定义:
Vector Store 是将嵌入后的向量存储到数据库中,支持高效的相似性搜索。常见的向量数据库包括 FAISS、Chroma、Pinecone 等。
示例:
使用 FAISS 存储向量并检索。
from langchain.vectorstores import FAISS
# 将分割后的文档转换为向量并存储
vector_store = FAISS.from_documents(
documents=split_docs,
embedding=embeddings
)
# 保存向量库到本地(可选)
vector_store.save_local("faiss_index")
5. Retriever(检索器)
定义:
Retriever 是从向量库中检索与输入查询最相关的文档片段的核心组件。它基于语义相似性(向量距离)进行搜索。
示例:
使用检索器查找相关文档。
# 从向量库创建检索器
retriever = vector_store.as_retriever(
search_type="similarity", # 搜索类型("similarity" 或 "mmr")
search_kwargs={"k": 3} # 返回前3个结果
)
# 执行检索
query = "What is the main topic of the document?"
relevant_docs = retriever.get_relevant_documents(query)
print("Retrieved documents:")
for doc in relevant_docs:
print(doc.page_content[:100] + "...")
完整流程示例
将以上步骤整合为一个完整的 RAG 流程:
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
# 1. 加载文档
loader = TextLoader("example.txt")
docs = loader.load()
# 2. 文档转换(分割)
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
split_docs = text_splitter.split_documents(docs)
# 3. 嵌入
embeddings = OpenAIEmbeddings()
# 4. 向量存储
vector_store = FAISS.from_documents(split_docs, embeddings)
# 5. 检索器
retriever = vector_store.as_retriever(search_kwargs={"k": 2})
# 检索测试
query = "What is the key message?"
results = retriever.invoke(query)
print("Top 2 results:", results)
最后总结
- Load:从多种来源加载原始文档。
- Embed:将文本转换为向量表示。
- Document Transform:预处理文档(如分割)。
- Vector Store:存储向量以实现高效检索。
- Retriever:根据查询检索相关文档。
这些步骤构成了 LangChain 中处理文档的核心流程,广泛应用于问答系统、知识库搜索等场景。

















 1750
1750

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









