







项目地址:https://github.com/Tsinghua-MARS-Lab/futr3d
论文地址:https://arxiv.org/abs/2203.10642
环境:Linux、cuda 11.1、python 3.8
1.创建虚拟环境futr
conda create -n futr python=3.8 -y
conda activate futr
2.安装pytorch的GPU版本,在这里我选择了离线安装,直接下载whl文件,然后pip安装。whl官方的地址是whl传送门,或者另一个传送门。
pip install torch-1.9.0+cu111-cp38-cp38-linux_x86_64.whl torchvision-0.10.0+cu111-cp38-cp38-linux_x86_64.whl torchaudio-0.9.0-cp38-cp38-linux_x86_64.whl
也可以用官方命令安装(你连了外网的情况下)
pip install torch==1.9.0+cu111 torchvision==0.10.0+cu111 torchaudio==0.9.0 -f https://download.pytorch.org/whl/torch_stable.html
3.准备mmcv-full 1.6.0、mmdet、mmsegmentation、nuscenes-devkit
pip install mmcv-full==1.6.0 -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.9.0/index.html
pip install mmdet==2.24.0 mmsegmentation==0.29.1 nuscenes-devkit
4.clone项目并完成项目安装。
git clone https://github.com/Tsinghua-MARS-Lab/futr3d.git
cd futr3d
pip3 install -v -e .
下一步是准备数据集。
5.获取Nuscenes数据集,代码学习可以下载mini版本。下载地址:https://www.nuscenes.org/download(需要登录,没账号就注册一个),下载解压后放到data目录下,改名为nuscenes,这里用mini版本。
再次之前需要一点改动,xxx/futr3d/tools/create_data.py 第90行的部分修改为
#原代码为:create_groundtruth_database(dataset_name, root_path, info_prefix,
# 'data/nusc_new/nuscenes_infos_train.pkl')
create_groundtruth_database(dataset_name, root_path, info_prefix,'data/nuscenes/nuscenes_infos_train.pkl')
第249行的注释取消掉,如下图:
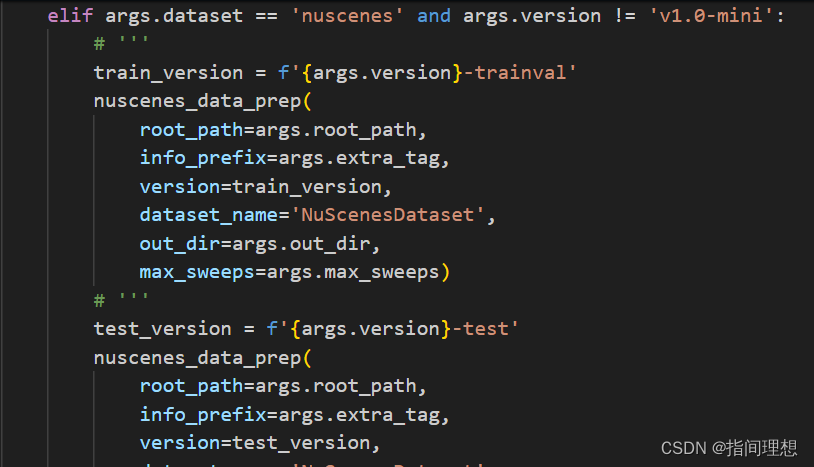
一开始我没读这块代码,后面发现处理后数据只有test,又回来改。实在是太折腾了,建议还是直接用mmdetection3d官方的代码了(我真不明白作者改来改去为什么会连跑都跑不通,故意的还是什么情况,GitHub好多人的issue也没回答,大佬真不是我能猜透的)。修改后运行:
python tools/create_data.py nuscenes --root-path ./data/nuscenes --out-dir ./data/nuscenes --extra-tag nuscenes --version v1.0-mini
如果是完全版数据集去掉–version v1.0-mini即可,如下:
python tools/create_data.py nuscenes --root-path ./data/nuscenes --out-dir ./data/nuscenes --extra-tag nuscenes
运行后会在nuscenes下多出几个pkl文件
如果报错:“SystemError: initialization of _internal failed without raising an exception”参考这篇文章解决办法,直接运行
pip install numpy==1.23.5
获取pkl文件后,这里想要进行Lidar+cam的训练,需要先运行lidar only和camera only获取两种模型,用tools/fuse_model.py合并后作为预训练模型再去训练lidar、camera融合的方法。
6.测试项目
先尝试训练Lidar-only,看看代码能否跑通:
修改几个地方:
- plugin/futr3d/configs/lidar_only/lidar_0075v_900q.py中_base_中,为_base_中三个路径在前面多加一个../
- 在plugin/futr3d/models/detectors/futr3d.py、plugin/futr3d/models/head/futr3d_head.py、plugin/futr3d/datasets/loading.py三个文件中,依次把import部分的from plugin.fudet.models.utils.grid_mask import GridMask改为from plugin.futr3d.models.utils.grid_mask import GridMask(我也不懂为什么官方给的代码还有BUG)
- 如果你显存够大,忽略这步(比如40G或者是80G显存)。在/futr3d/plugin/futr3d/configs/lidar_only/lidar_0075v_900q.py中,为data的构造添加batch限制,具体如下(添加注释掉的部分代码,这里只是为了方便展示添加的代码所以故意注释掉了,batchsize根据个人情况改):
data = dict(
# samples_per_gpu=1,# batch size
# workers_per_gpu=0,
train=dict(
type='CBGSDataset',
dataset=dict(
type=dataset_type,
data_root=data_root,
ann_file=data_root + 'nuscenes_infos_train.pkl',
pipeline=train_pipeline,
classes=class_names,
test_mode=False,
use_valid_flag=True,
# we use box_type_3d='LiDAR' in kitti and nuscenes dataset
# and box_type_3d='Depth' in sunrgbd and scannet dataset.
box_type_3d='LiDAR')),
val=dict(pipeline=test_pipeline, classes=class_names, ann_file=data_root + 'nuscenes_infos_val.pkl'),
test=dict(pipeline=test_pipeline, classes=class_names, ann_file=data_root + 'nuscenes_infos_val.pkl'))
运行下面代码开始训练(dist_train.sh也有问题,这里用train.py直接启动训练,如果你是想用多卡尝试跑出论文效果,在第7部分有dist_train.sh的修改方案)
python tools/train.py plugin/futr3d/configs/lidar_only/lidar_0075v_900q.py --gpu-id 1 --autoscale-lr
如果报错TypeError: FormatCode() got an unexpected keyword argument ‘verify‘,yapf包的版本降低为yapf==0.40.1(pip install就行,不单独列个命令了)。我这里指定了用显卡1训练,只是为了测试项目是否能跑通。
上面说得是仅用lidar训练,现在,利用lidar预训练模型和image预训练模型经过合并后进行lidar+image的融合训练。具体在图像预训练(被我更新为backbone是resnet的模型了,具体原因可以看文章后面的两个更新部分),Lidar预训练两个地方下载模型(如果你想直接跟着我的代码运行,下载两个文件到:/futr3d/lidar-cam-pretrain/目录下),然后修改tools/fuse_model.py这个文件如下(把两个模型文件的路径换成你自己的):
import torch
img_ckpt = torch.load('./lidar-cam-pretrain/detr3d_vovnet_trainval.pth')
state_dict1 = img_ckpt['state_dict']
pts_ckpt = torch.load('./lidar-cam-pretrain/lidar_0075_900q.pth')
state_dict2 = pts_ckpt['state_dict']
# pts_head in camera checkpoint will be overwrite by lidar checkpoint
state_dict1.update(state_dict2)
merged_state_dict = state_dict1
save_checkpoint = {'state_dict':merged_state_dict }
torch.save(save_checkpoint, './checkpoint/lidar_vov_trainval.pth')
在futr3d创建checkpoint目录,然后执行该文件:
python tools/fuse_model.py
这下你的主目录下checkpoint里会多出一个权重文件,这就是融合模型训练需要的预训练模型。
下一步修改xxx/futr3d/plugin/futr3d/configs/lidar_cam/lidar_0075v_cam_vov.py模型里workers_per_gpu=0,samples_per_gpu=1,显存够大也可以把samples_per_gpu改高点,再将最后一行load_from改为’checkpoint/lidar_vov_trainval.pth’。
接下来运行
python tools/train.py plugin/futr3d/configs/lidar_cam/lidar_0075v_cam_vov.py --gpu-id 2 --autoscale-lr
其中gpu-id表示gpu序号,这里指定了第2张GPU训练。注意了,这个项目代码里有.cuda()的操作,这个操作默认会在第一张显卡进行,所以最好是空出第一块显卡,要不然代码跑到这会因为张量在不同显卡上报错(心累,还得找到有BUG的地方,把tensor移到统一显卡上,还好,我只发现了一个这样的问题,不过在80G显存上跑可以完全忽略这个问题,显存大就是任性),训练时batch设成了1,大概占用10G显存。
针对上面说的.cuda()问题,修改:plugin/futr3d/models/utils/grid_mask.py,修改如下(可以直接搜索代码定位到具体位置):
mask = torch.from_numpy(mask).float().cuda(x.device) # 指定为x同设备
修改完后再次运行代码训练即可。
如果运行代码报错AttributeError: module ‘distutils’ has no attribute ‘version’,执行
pip install setuptools==59.5.0
可能会遇到的错:RuntimeError: /tmp/mmcv/mmcv/ops/csrc/pytorch/cuda/sparse_indice.cu 123
cuda execution failed with error 2
解决方法,执行(这里cu111是我的cuda版本,如果你是其他版本换对应版本号就行,比如10.2换成cu102)
pip install spconv-cu111
7.多模态融合训练
这里我只进行Lidar+camera的融合,并且预训练权重获取方式在第6节的后半部分有说,这里不再赘述。
如果想要多卡训练,需要用dist_train.sh训练,但是官方给的代码里似乎有不知名换行符,所以修改tools/dist_train.sh内容如下:
CONFIG=$1
GPUS=$2
NNODES=${NNODES:-1}
NODE_RANK=${NODE_RANK:-0}
PORT=${PORT:-29500}
MASTER_ADDR=${MASTER_ADDR:-"127.0.0.1"}
PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
python -m torch.distributed.launch \
--nnodes=$NNODES \
--node_rank=$NODE_RANK \
--master_addr=$MASTER_ADDR \
--nproc_per_node=$GPUS \
--master_port=$PORT \
$(dirname "$0")/train.py \
$CONFIG \
--seed 0 \
--launcher pytorch ${@:3}
修改这个代码后,之前说的 grid_mask.py里的修改可以恢复回来,训练可以直接运行
sh tools/dist_train.sh plugin/futr3d/configs/lidar_cam/lidar_0075v_cam_vov.py 2
如果图像分支用resnet则运行:
sh tools/dist_train.sh plugin/futr3d/configs/lidar_cam/lidar_0075v_cam_res101.py 2
如果上面的命令报错则改成(具体细节可以百度了解,sh和bash启动主要是bash和dash的区别):
bash tools/dist_train.sh plugin/futr3d/configs/lidar_cam/lidar_0075v_cam_vov.py 2
bash tools/dist_train.sh plugin/futr3d/configs/lidar_cam/lidar_0075v_cam_res101.py 2
其中2表示两张GPU进行训练。如果你是要调试学习代码,也可以用之前 python train.py的方式启动训练过程。如果训练不小心中断了,只需要使用--resume from参数,就可以恢复之前的状态继续训练,如下所示:
bash tools/dist_train.sh plugin/futr3d/configs/lidar_cam/lidar_0075v_cam_vov.py 2 --resume-from work_dirs/xxx/latest.pth
如果你的显卡不连续,需要指定某几张显卡进行训练,在命令前添CUDA_VISIBLE_DEVICES=0,1,2,3,其中0,1,2,3表示这4张显卡可用,例如,使用第1张和第三张显卡训练运行(序号从0开始计算):
CUDA_VISIBLE_DEVICES=0,2 bash tools/dist_train.sh plugin/futr3d/configs/lidar_cam/lidar_0075v_cam_vov.py 2 --resume-from work_dirs/xxx/latest.pth
8.推理
推理时,老规矩,修改tools/dist_test.sh 如下:
CONFIG=$1
CHECKPOINT=$2
GPUS=$3
NNODES=${NNODES:-1}
NODE_RANK=${NODE_RANK:-0}
PORT=${PORT:-29500}
MASTER_ADDR=${MASTER_ADDR:-"127.0.0.1"}
PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
python -m torch.distributed.launch \
--nnodes=$NNODES \
--node_rank=$NODE_RANK \
--master_addr=$MASTER_ADDR \
--nproc_per_node=$GPUS \
--master_port=$PORT \
$(dirname "$0")/test.py \
$CONFIG \
$CHECKPOINT \
--launcher pytorch \
${@:4}
运行命令:
sh tools/dist_test.sh plugin/futr3d/configs/lidar_cam/lidar_0075v_cam_vov.py work_dirs/lidar_0075v_cam_vov/latest.pth 2 --eval bbox
报错改成:
bash tools/dist_test.sh plugin/futr3d/configs/lidar_cam/lidar_0075v_cam_vov.py work_dirs/lidar_0075v_cam_vov/latest.pth 2 --eval bbox
2表示用两个GPU推理,latest.pth是训练后的模型文件。
报错汇总:
①报错:“SystemError: initialization of _internal failed without raising an exception”参考这篇文章解决办法,直接运行
pip install numpy==1.23.5
②如果报错TypeError: FormatCode() got an unexpected keyword argument ‘verify‘,yapf包的版本降低为yapf==0.40.1:
pip install yapf==0.40.1
③如果运行代码报错AttributeError: module ‘distutils’ has no attribute ‘version’,执行
pip install setuptools==59.5.0
④报错:RuntimeError: /tmp/mmcv/mmcv/ops/csrc/pytorch/cuda/sparse_indice.cu 123
cuda execution failed with error 2
解决方法,执行(这里cu111是我的cuda版本,如果你是其他版本换对应版本号就行,比如10.2换成cu102)
pip install spconv-cu111
更新:L+C的训练出了点问题,训练过程中每个epoch后输出的mAP和NDS都太高了,感觉上应该是数据泄露了,并且,在以batchsize为4进行训练后,仅仅一轮,使用test.py测试结果都比官方提供的模型推理结果高了近十个点,这推理结果有点吓人,很明显是出问题了。不过不知道是怎么了,目前还在思考哪个环节出了问题。
更新:破案了,在DETR3D的GitHub仓库下载了一个camera-only的模型,但是没有注意到,DETR3D, VoVNet on trainval, evaluation on test set这个模型是DETR最终提交到nuscenes官网时训练的最终模型,也就是说在训练过程中,训练集和验证集全都用于训练了,所以拿这个模型和lidar-only分支fuse后再去训练相当于帮模型作弊了,对于vov模型的camera-only分支如果想用的话可能需要自己按照DETR3d官方的方法自己去训练一下,或者在DETR3d下载resnet作为backbone的模型使用,这个模型没有使用验证集。

















 275
275

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









