




 在使用Python的Scrapy和Selector尝试通过XPath抓取网站li标签中的title内容时,遇到列表为空的问题。发现title内容实际与a标签文本相同,但直接获取仍为空。通过查看网页源代码,发现内容以键的形式存储,最终利用正则表达式成功获取。此外,还探讨了XPath在HTML解析中的应用和调试方法。
在使用Python的Scrapy和Selector尝试通过XPath抓取网站li标签中的title内容时,遇到列表为空的问题。发现title内容实际与a标签文本相同,但直接获取仍为空。通过查看网页源代码,发现内容以键的形式存储,最终利用正则表达式成功获取。此外,还探讨了XPath在HTML解析中的应用和调试方法。
python问题: xpath获取多个li标签内容是空的?
想通过Selector爬取网站信息,同时保存多个li标签中的title标签值,总是得到空的列表。

names = sel.xpath('//*[@class="list-box"]/li/a/@title')
因为title标签内容和a标签文本内容一致,想获取文本,结果也为空列表。
name=sel.xpath('//div/ul[@class="list-box"]//li//a//text()').extract()
尝试过多种格式,均无果。
发现只有以下代码可得到一些信息,但不能用:
names = sel.xpath('//*[@class="list-box"]/li').extract()

另外,通过增加etree.HTML语句进行获取
content=etree.HTML(sel).xpath('.//ul [@class="list-box"]//li')
for i in content:
print(i.text)
结果如下:
None
None
None
...
None
None
共86个空元素,说明位置没问题,只是提取的信息不全。
查看网页文本发现,这些视频的名称都以键的形式储存,这样就好办了,直接通过正则表达式来获取。
{"cid":35446498,"page":1,"from":"vupload","part":"第1集 简单振子的振动(一)【理想视频教程网:www.mba518.com】","duration":1289,"vid":"","weblink":"","dimension":{"width":450,"height":360,"rotate":0}},
{"cid":35446499,"page":2,"from":"vupload","part":"第2集 简单振子的振动(二)【理想视频教程网:www.mba518.com】","duration":1294,"vid":"","weblink":"","dimension":{"width":480,"height":384,"rotate":0}},
{"cid":35446500,"page":3,"from":"vupload","part":"第3集 简单振子的振动(三)【理想视频教程网:www.mba518.com】","duration":1433,"vid":"","weblink":"","dimension":{"width":480,"height":384,"rotate":0}},
title = re.findall(r'"{}":"([^"]+)"'.format('part'), sel, re.I)
结果也没问题了:
>>> re.findall(r'"{}":"([^"]+)"'.format('part'), sel, re.I)
['第1集 简单振子的振动(一)【理想视频教程网:www.mba518.com】',
'第2集 简单振子的振动(二)【理想视频教程网:www.mba518.com】',
'第3集 简单振子的振动(三)【理想视频教程网:www.mba518.com】',
'第4集 简单振子的振动(四)【理想视频教程网:www.mba518.com】',
至此问题得以解决了。但有个新问题,response.text为何不能获取li标签的详细内容?
note:
该问题很常见,但暂时未找到解决办法,待解决!——20200526
终于通过response.text查看网页文本,原来这部分的内容就是空白的,所以之前的获取方式是没问题的。——20200702
xpath简介:
首先需要了解一下定位符的格式。
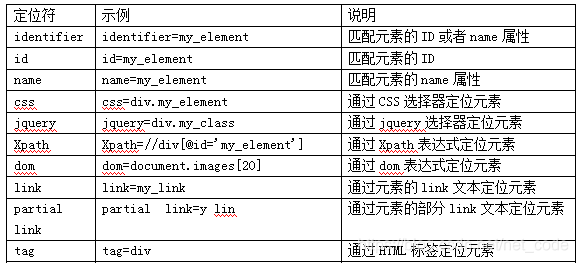
xpath作为一种简单有效定位方法,可为selenium所用。xpath可用来在xml文档中对元素和属性进行遍历。由于html的层次结构与xml的层次结构一致,所以使用xpath也能够进行html元素的定位。
使用xpath可结合lxml库进行使用,
from lxml import etree
Selector=etree.HTML
这样就可以把网页源代码转换成可被xpath识别和匹配的对象,Selector.xpath(’’)引号内容为匹配感兴趣的内容。
其中//定位根节点,/表示往下层寻找,text()为提取文本内容,@#为提取某个属性 #的内容。
xpath定位方法
该网页下选择内容位置右键选择审查元素,将自动定位到浏览器页面上选择需要定位的元素,Elements页中就会自动定位高亮显示页面中的元素。
xpath调试
可以在 console控制台进行xpath的调试,以验证表达式是否正确。以$x(“xpath表达式”)进行,但我又试了试,只能以元素的绝对路径才可以获取,相对路径似乎不行,但绝对路径对于想要的获取的数据不太合适,还得继续摸索一下。

















 896
896

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









