







 本文探讨了模型量化中的精度问题和量化误差来源,重点关注Post-training Quantization (PTQ)策略,如AdaRound、AdaQuant和BRECQ。这些优化方法旨在通过在保持权重不变的情况下优化量化参数来提升量化效果。AdaQuant作为一种全面的优化解决方案,通过Integer programming寻求Mixed-precision planning,同时结合多种辅助策略,如ADMM和Bias Correction。文章还讨论了PTQ技术的实现,强调轻量化和与推理引擎的结合,以及在不同数据依赖程度下的量化方法选择。
本文探讨了模型量化中的精度问题和量化误差来源,重点关注Post-training Quantization (PTQ)策略,如AdaRound、AdaQuant和BRECQ。这些优化方法旨在通过在保持权重不变的情况下优化量化参数来提升量化效果。AdaQuant作为一种全面的优化解决方案,通过Integer programming寻求Mixed-precision planning,同时结合多种辅助策略,如ADMM和Bias Correction。文章还讨论了PTQ技术的实现,强调轻量化和与推理引擎的结合,以及在不同数据依赖程度下的量化方法选择。
背景
- 模型经过量化,势必引入量化噪声;大多数情况下,会导致推理精度下降;
- 量化误差主要由Round取整、Clip限幅引起,并可归纳为Activation量化误差与Weight量化误差:
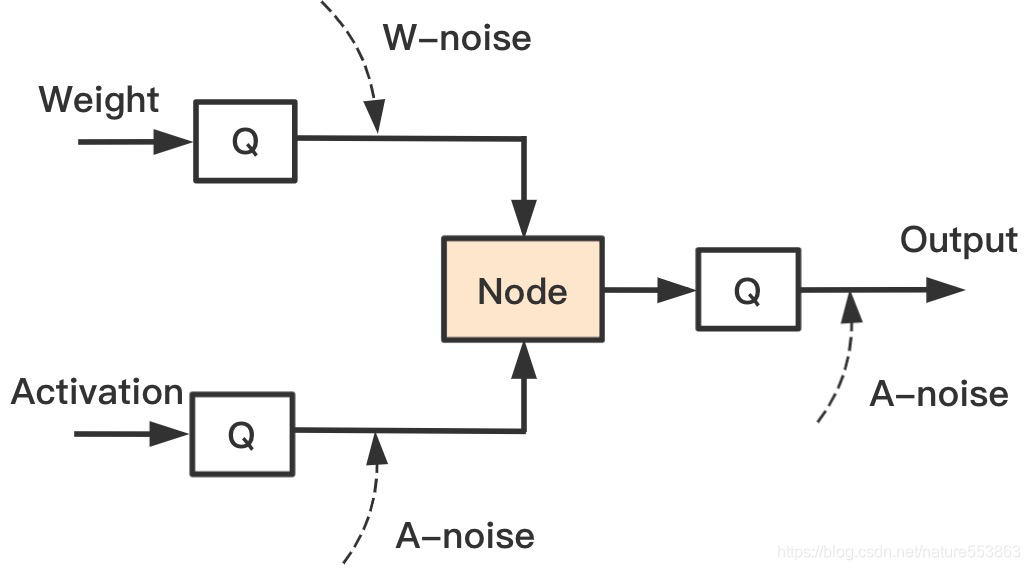
- 为改善量化后精度,通常的策略:
- PTQ (Post-training Quantization)策略:典型方法包括校准算法的改进(如改进KL算法、基于Histogram的非对称量化等),或叠加使用有助于减少量化误差的PTQ策略(如ADMM、Bias Correction、AMP、Weight Adjustment等):
- 优势:简单易用,能快速看到量化效果;
- 劣势:由于模型训练时,并未考虑到量化约束,因此未必能完全消除量化误差或精度损失;
-
QAT (Quantization-aware Training)策略:基于训练数据的在线微调,使模型对量化表现的更为友好,以改善量化效果:
- 优势:训练阶段考虑到了量化约束,精度效果相对更好;更有利于极低比特量化(如INT4、或INT8/INT4混合)的落地实现;更适合特殊量化需求,如INT8 Winograd;
- 劣势:存在训练成本,维护升级相对吃力;精度效果未必好,也依赖策略选择与超参调整;
- PTQ (Post-training Quantization)策略:典型方法包括校准算法的改进(如改进KL算法、基于Histogram的非对称量化等),或叠加使用有助于减少量化误差的PTQ策略(如ADMM、Bias Correction、AMP、Weight Adjustment等):
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









