



KNN:
在样本空间中,计算目标与所有样本的距离,并选取k个来进行投票 投票最多的类即为目标所属类。其中K需要指定,也是关键所在
# argsort() 返回排序后的索引值
sortedDistIndices = argsort(distance)
classCount = {} # define a dictionary (can be append element)
for i in range(k):
# # step 3: 选择k个最近邻
voteLabel = labels[sortedDistIndices[i]]
# # step 4: 计算k个最近邻中各类别出现的次数
# when the key voteLabel is not in dictionary classCount, get()
# will return 0
classCount[voteLabel] = classCount.get(voteLabel, 0) + 1
随机森林:
随机森林中有多个模型,并随机选数据来训练每一个模型(有放回的),即boot strap sample
for i in xrange(numberOfTrees):
bag = data.getBag()
self.forest.append(C45Tree(bag))
#Create the bag
for i in range(0, len(self.data)):
bag.append(random.choice(self.data))
Adaboost:
Boosting算法要涉及到两个部分,加法模型和前向分步算法。
加法模型就是说强分类器由一系列弱分类器线性相加而成
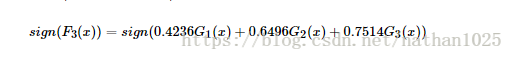
特点是:会改变训练集的权重,也会改变分类器的权重。
朴素贝叶斯分类器:
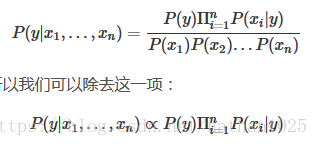

逻辑回归:
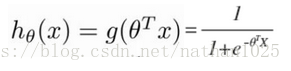
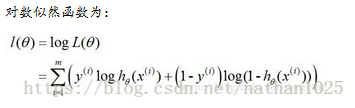

SVM:
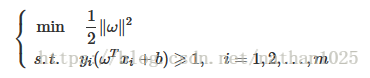
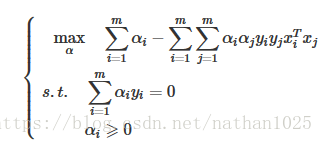
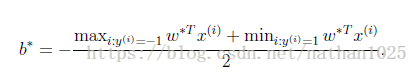
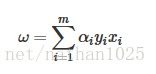
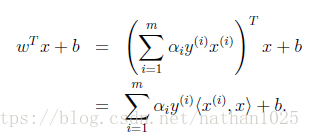
GBDT:
GBDT的核心就在于,每一棵树学的是之前所有树结论和的残差,这个残差就是一个加预测值后能得真实值的累加量。

PCA:

mean-shift:

层次聚类: 需要知道分为几类

k-means:

XGBoost:
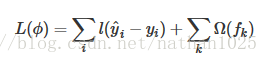
![]()
目标要求预测误差尽量小,叶子节点尽量少,节点数值尽量不极端

LLE((locally linear embedding):
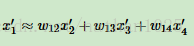
LLE算法可以归结为三步:
(1)寻找每个样本点的k个近邻点;
(2)由每个样本点的近邻点计算出该样本点的局部重建权值矩阵;
(3)由该样本点的局部重建权值矩阵和其近邻点计算出该样本点的输出值。

OPTICS:算法输出的是样本的一个有序队列,从这个队列里面可以获得任意密度的聚类。

https://blog.youkuaiyun.com/nathan1025/article/details/81316987

















 16万+
16万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









