




 本文介绍了作者作为Python爬虫初学者,从零开始学习爬虫并实现下载meizitu静态网站及burberry动态网站图片的过程。内容包括Python基础知识、请求库的使用、BeautifulSoup解析网页、动态网站的处理方法,以及如何应对网站的反爬策略。
本文介绍了作者作为Python爬虫初学者,从零开始学习爬虫并实现下载meizitu静态网站及burberry动态网站图片的过程。内容包括Python基础知识、请求库的使用、BeautifulSoup解析网页、动态网站的处理方法,以及如何应对网站的反爬策略。
文章目录
1.前言
2.知识储备
3.爬取静态网站
4.爬取动态网站
5.源代码
1.前言
近日疫情严重,手机已经玩吐了,闲着无聊逛衣服品牌官网发现,结果一时兴起,想学一学python,写一个爬虫下载官网所有最新上架的衣服图片和价格;说干就干,但身为一个只学过一些c和c++的python 零基础大二小白,csdn上的各种教程里涉及的各种发法、工具和库让我眼花缭乱;因此走了很多弯路,终于花三天时间完成了爬虫的设计实现。自己总结下来发现学习+上手其实 真的一点都不难!
今天我把自己的从零开始的所有经验记录下来,让所有想学爬虫但是面对各类教程不知所措的童鞋们能从中收获一二。
2.知识储备
-
python基本语法
-
库(安装方式自行百度)
-
request库
主要用库中的get方法和post方法用来向指定的url(网址)请求数据,
import requests url = 'https://cn.burberry.com/service/shelf/mens-new-arrivals-new-in/' response = requests.get(url)值得注意的是,对于一些网页必须加入指定的headers,用来将你的爬虫伪装成阅览器,并添加一些重要的标志,否则网站不会让你访问它的数据,
User_Agent = 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:66.0) Gecko/20100101 Firefox/66.0' header = { 'User-agent':User_Agent, } response = requests.get(url,headers = header)另外,请求到的数据是requests类型,我们要对其进行分析,必须把它转化成bytes类型或者str类型,即
content = response.content #或者使用text属性得到相应字符串 #content = response.text这样就成功得到bytes类型的网站源代码啦!
接下来对该文本进行分析,怎么进行呢?有两个选择,一是正则表达式(比较难),二就是方便我们初学者使用的BeautifulSoup库啦!
但首先,我们需要安装使BeautifulSoup的使用更为方便快速的解码库lxml库 -
lxml库
用来为BeautifulSoup的初始化构造提供解码器。
-
BeautifulSoup库
主要使用库中的“构造函数”完成对bytes类型数据的格式化,即将其转化为可以利用库中方法进行检索的对象
import lxml from bs4 import BeautifulSoup soup = BeautifulSoup(content,'lxml')之后便可以利用库中的find 和 find_all方法,用来找源码中相应的标签! 举个栗子,下面是burberry官网的源码截图,
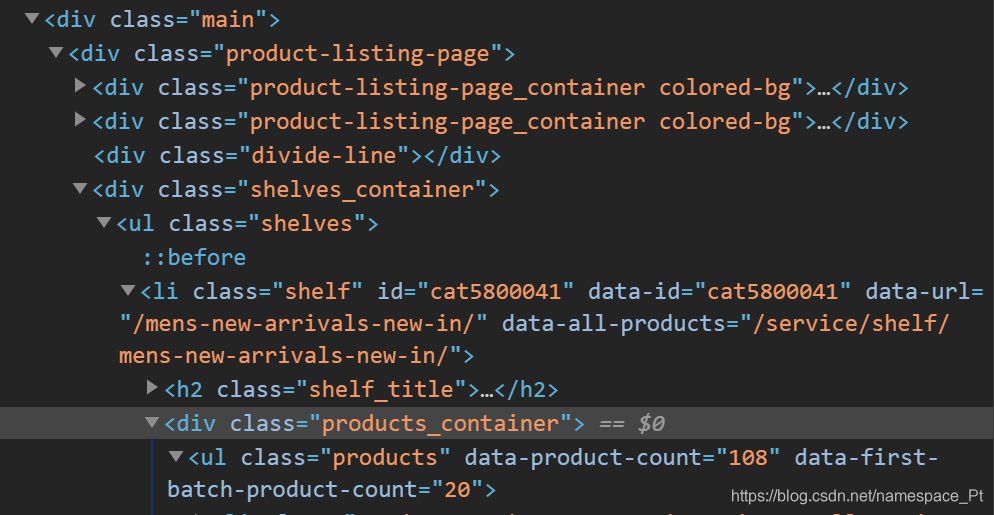
假设我们已经构造好了其BeautifulSoup类型的对象soup,
现在我们想从中找到加亮的那一行代码,首先明确其 标签 是 div, 其中class = xxx* 为该标签下的 属性,那么我们就用find函数来找:target = soup.find(name = 'div',attrs = { 'class':'productts_container'}) #name代表着标签的名称 #attrs是属性的字典,class是属性名,product_container是该属性的值 #如果只匹配name,不匹配属性,会找错,因为find默认返回第一个 #找到匹配的值,而加亮代码行上面也有名为div的标签,因此必须匹配独一无二的属性值得注意的是,find函数返回的是BeautifulSoup类型的对象,如果想要访问其中的某项属性,需要使用attrs[]方法,例如现在我们要访问上述的class属性值:
class_result = target.attrs['class'] #attrs可以省略 #class_result = target['class'] print(class_result) #products_containerfind_all函数的调用方法和find函数相同,传入参数也一样,只不过find_all会找到所有匹配的项,并将其构建为一个列表
-
-
JSON文件基础
-
在爬取动态网页时会用到,我理解其为字典的列表,其中字典有嵌套的结构
-
具体可参考
-
3.爬取静态网站
-
流程(我们遵循csdn传统~以下载https://www.mzitu.com/221136每一页图片为例,内容不重要!学习才是根本目的)
1.我们看到网站的每一页图片都是加载好的,即没有***查看更多***等按钮,也不会随着鼠标 滚轮拖动而加载新的内容,所以是静态网页。
2.用开发人员工具f12分析原网页,一步步找到要爬的图片所在的位置,如图,一个红圈是标题,一个红圈是图片所在的url,一个是当前页数,一个是总页数
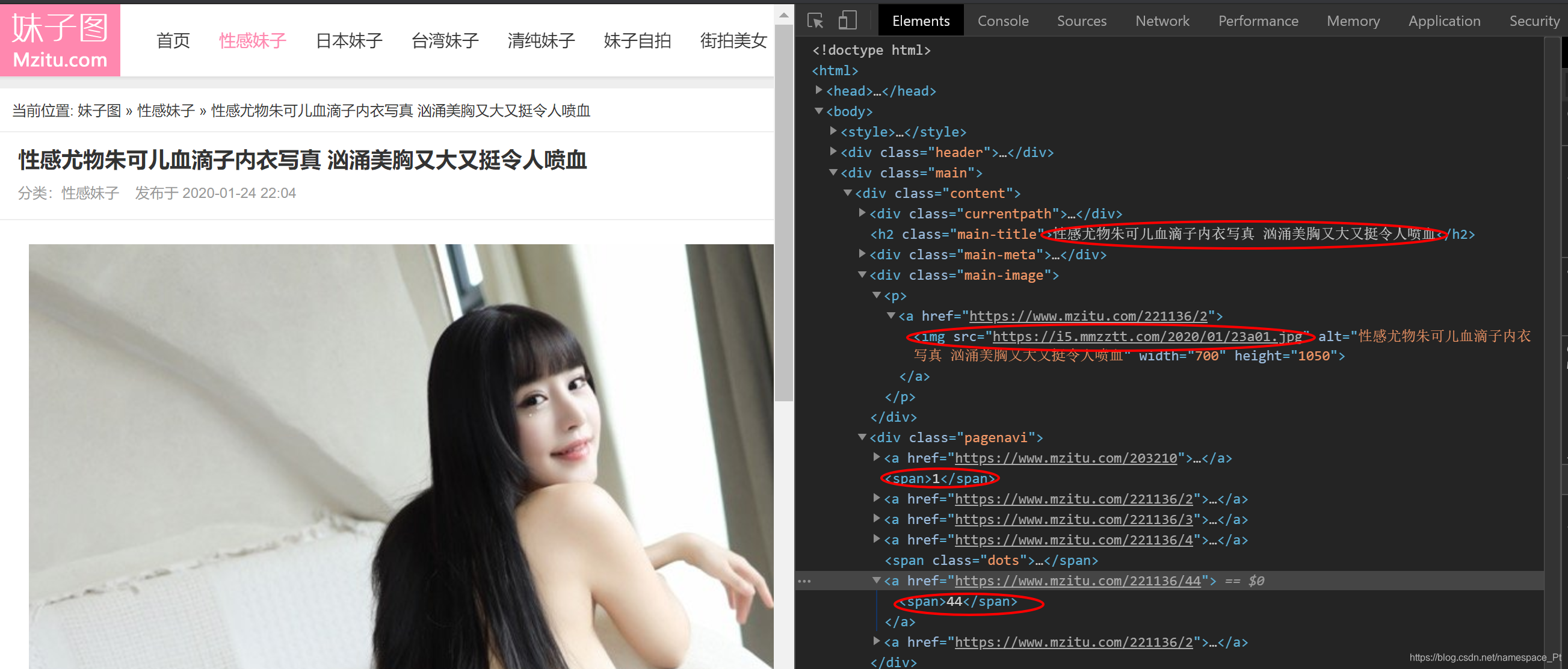
- 发现标题是在名为h2的标签的字符串,并且该标签有class属性,其值为main-title
- 同时图片的url存在名为img的标签的src属性里,并且该img标签还有属性alt,其值和标题相同
- 我们不关心当前是第几页,只需要获取页数上界,而页数存储在名为div,有属性class = pagenavi的标签的名为a的子标签的名为span的子标签的字符串里,而上界存在倒数第二个上述标签中(自己观察网页,发现最后一个存的是下一页)
3.分析网址的变化:
- 我们点进第二页图片,发现网站url在初始页的基础上添加了’/2’,如图:

- 同时第二页的标题、图片url所在位置都没有发生变化,如图:
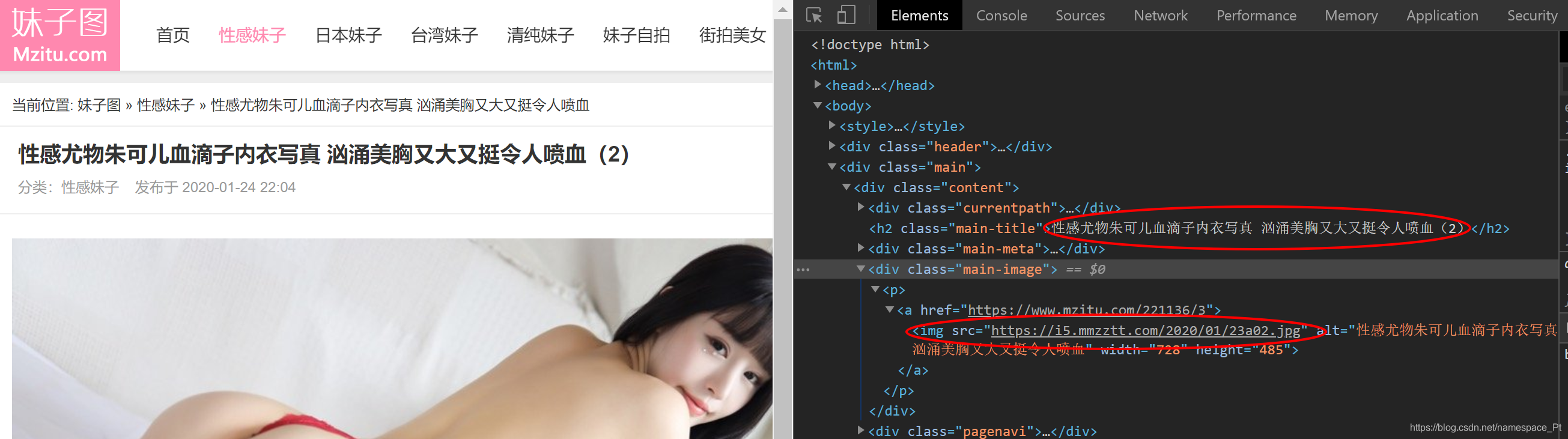
- 再试一试能否通过在原url上添加’/1’能否访问到第一页,发现可以;至此,全部分析结束,开始写代码。
4.用requests库的get方法获得数据
import requests import lxml from bs4 import BeautifulSoup #引入库 url = 'https://www.mzitu.com/221136' header = { "User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:66.0) Gecko/20100101 Firefox/66.0", "Referer":"https://www.mzitu.com/jiepai/comment-page-1/"} #header里必须设置Referer属性,否则无法下载图片 response = requests.get(url,headers = header) #请求网页4.将其构造为BeautifulSoup对象
bsobj = BeautifulSoup(content,'lxml') #解析html5.用find、find_all方法找到相应的数据
#get_text()方法获取中文字样,用string属性也可以 title = bsobj
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




























 到【灌水乐园】发言
到【灌水乐园】发言







