



 本文详细介绍代码性能优化的方法,包括性能对比原则、分析工具使用、计算机性能要素、编译器优化技巧及常见代码优化实践,旨在帮助开发者提升软件性能。
本文详细介绍代码性能优化的方法,包括性能对比原则、分析工具使用、计算机性能要素、编译器优化技巧及常见代码优化实践,旨在帮助开发者提升软件性能。
目录
一,性能对比
我们经常对比2份代码的性能,首先要注意控制这几点:
(1)2份代码的功能完全相同
(2)使用相同的测试环境(windows还是linux,编译器等)
(3)使用相同的性能测试代码
(4)使用相同的编译优化级别(VS开release模式)
对于简单的情况,编译器很可能已经做了大量的优化,使得对比结果并不明显。
但是,这却并不代表我们写代码可以完全依赖编译器。
代码的两种写法,在不同程度的编译优化下,哪种写法更快可能没有定论。
例如下面的“循环嵌套条件语句”,clion上运行的是1770 1501,visual studio上运行的是849 1228,感觉应该是vs做的编译优化比较多,简单的if语句可能被优化掉了。
我在windows机器上写C++代码,用cmake编译运行,用clock函数计时,用来判断程序运行时间。
性能测试代码
auto s1 = clock();
test();
auto e1 = clock();
cout << endl << e1 - s1;二,性能分析工具
1,VS性能分析工具
点击 分析、性能探测器、更改目标
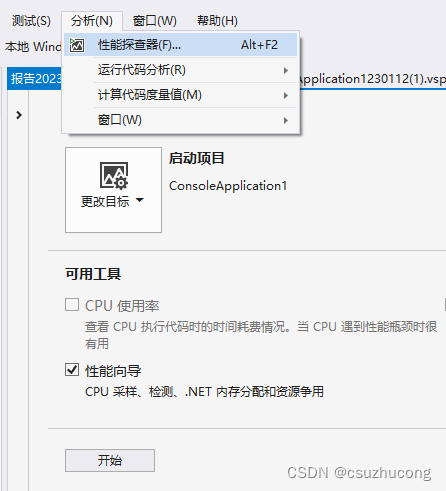
点击 可执行文件、开始、CPU采用、下一步、可执行文件、下一步
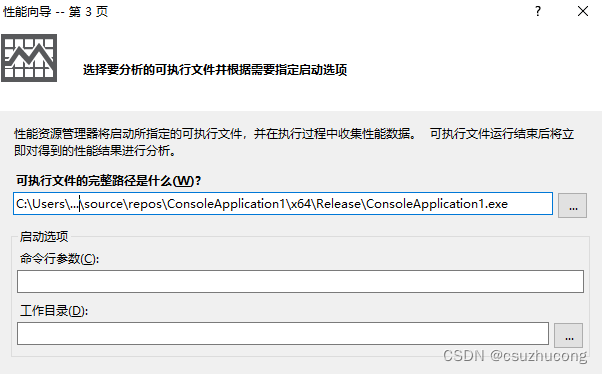
填写路径,完成。
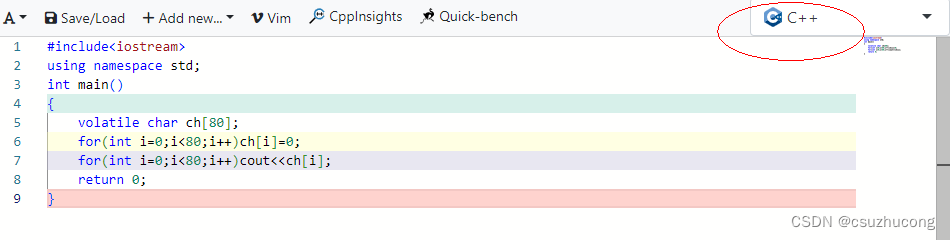
2,汇编分析工具
左边可以用不同语言写代码
右边可以选择不同的环境和编译器版本,还支持输入编译选项。
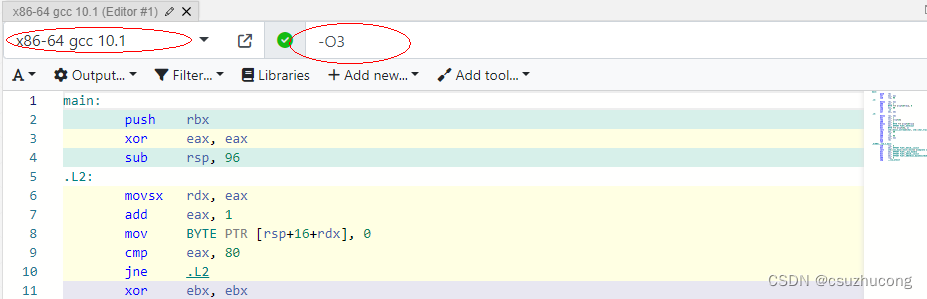
三,计算机性能
1,存储访问
连续的不跳跃的存储访问是最快的,这对程序性能影响很大。
2,处理器性能加速
处理器性能加速:指令乱序执行、流水线、并发
条件分支代码可能打乱流水线,造成性能下降。
3,系统调用开销
read write open close mmap 耗时比较长
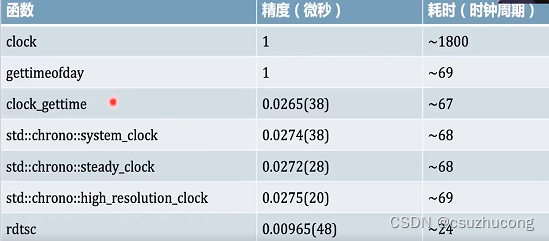
4,时钟函数
Linux中的时钟函数
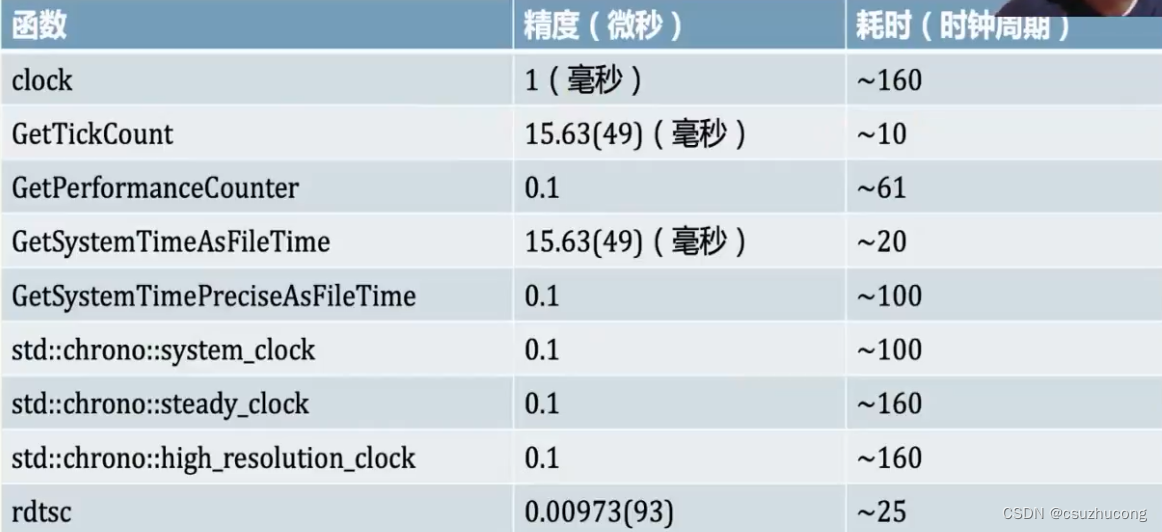
Windows中的时钟函数
四,编译器优化
1,总体特点

2,指令重排
好处是可以提高指令并行度。
int x,y,a;
int main()
{
x=a;
y=2;
return 0;
}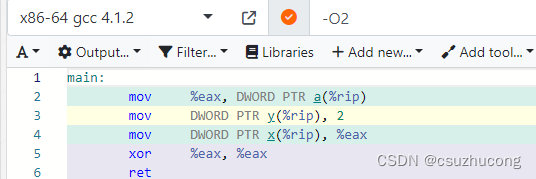
然而从gcc8开始,这个代码在O2下是不进行指令重排的,不知道为啥。
3,防优化技巧

五,常见代码的性能
1,二维数组的访问
二维数组的访问最好不要跳内存。
#include <stdio.h>
#include "time.h"
#define N 1000000
#define M 1000
typedef struct
{
int a[N];
}Node;
#define OUTCLOCK \
printf("%d ",clock()-theClock); \
theClock=clock();
int main()
{
clock_t theClock=clock();
Node *p=(Node *)malloc(sizeof(Node)*M);
OUTCLOCK
for(int i=0;i<M;i++)for(int j=0;j<N;j++)p[i].a[j]=i*j+1;
OUTCLOCK
for(int j=0;j<N;j++)for(int i=0;i<M;i++)p[i].a[j]=i*j+1;
OUTCLOCK
return 0;
}运行结果:
0 2339 2234
单位是毫秒
2,大批量内存拷贝
大批量内存拷贝,用memcpy代替赋值语句
int main()
{
clock_t theClock=clock();
Node *p=(Node *)malloc(sizeof(Node)*M);
int *p2=(int *)malloc(sizeof(int)*N*M);
OUTCLOCK
for(int i=0;i<M;i++)for(int j=0;j<N;j++)p2[i*N+j]=p[i].a[j];
OUTCLOCK
memcpy(p2,p, sizeof(int)*N*M);
OUTCLOCK
return 0;
}运行结果:
0 2811 276
3,多分支语句的顺序
形如如下的代码:
if(con1)do1;
else if(con2)do2;
else if(con3)do3;
else do4;假设do语句里面没有continue、break、goto、return语句,那么这段代码的执行时间分为con判断时间、do语句时间两部分。
其中,无论这些分支如何调整顺序,都不影响do语句时间,所以只需要考虑con判断时间。
假设各个分支的命中概率分别为p1 p2 p3 p4,判断时间(单个con表达式的执行时间)分别为t1 t2 t3 t4
则con判断时间T=p1t1 + p2(t1+t2) + p3(t1+t2+t3) + p4(t1+t2+t3+t4)
显然当p1/t1 > p2/t2 > p3/t3 > p4/t4时,T取到最小值。
也就是说,命中率高的分支往前放,单个con表达式执行时间较长的往后放(这种比如con表达式包含了执行一个函数)
4,循环嵌套条件语句
如果循环里面有if语句,无论是对程序员还是对cpu来说,都是一个复杂的行为。
#include <stdio.h>
#include "time.h"
#define N 1000000
#define M 1000
int x[M],y[M];
#define OUTCLOCK \
printf("%d ",clock()-theClock); \
theClock=clock();
int main()
{
for(int i=0;i<M;i++)x[i]=i*i,y[i]=i*i*i+i*3+1;
int d,s=0;
scanf("%d",&d);
clock_t theClock=clock();
for(int i=0;i<N;i++)for(int i=0;i<M;i++)if(x[i]==d)s+=y[i];
OUTCLOCK
for(int i=0;i<N;i++)for(int i=0;i<M;i++)s+=((x[i]==d)?y[i]:0);
OUTCLOCK
return 0;
}运行结果:
250000
1770 1501
可此可见,让条件只控制数据不控制指令跳转,对于CPU来说是很友好的。
5,虚函数
虚函数比较慢的原因有两个,一是需要通过函数指针来调用,二是通常会防止内联。
所以,CRTP模式会比继承模式要快。
6,volatile
普通代码:
#include<iostream>
using namespace std;
int main()
{
char ch[80];
for(int i=0;i<80;i++)ch[i]=0; //核心代码
for(int i=0;i<80;i++)cout<<ch[i];
return 0;
}其中赋值的那一行是核心代码。
汇编:
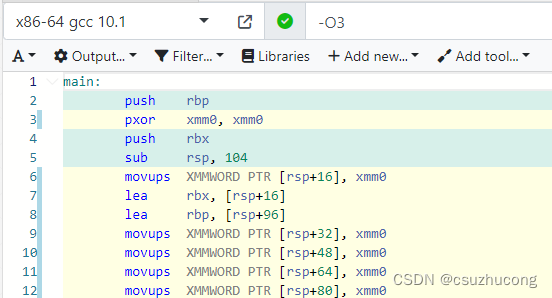
汇编结果是5次操作,每次操作16个字节。
加了volatile的代码:
#include<iostream>
using namespace std;
int main()
{
volatile char ch[80];
for(int i=0;i<80;i++)ch[i]=0; //核心代码
for(int i=0;i<80;i++)cout<<ch[i];
return 0;
}汇编:
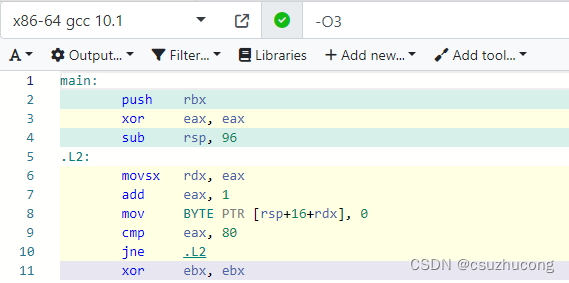
加了volatile的代码,汇编结果就是80次的循环了。
所以, volatile是对性能有负面影响的。
六,经验总结
1,异常性能
功能相同,代码差不多,但性能差异明显,有可能是算法写错了。
实例:杀手数独
错误代码中漏了规则,即少了DFS的剪枝条件,或许即使少了条件也有唯一答案,但搜索效率一定会降低。
2,性能优化手段总结
(来自吴咏炜老师)

3,增加Cache命中率
(1)增加Cache块大小
(2)增加Cache容量
(3)增加Cache相联度
(4)way预测
(5)编译优化
4,并行处理
(1)指令级并行
流水线、超标量、超长指令字、乱序执行
(2)向量数据并行
向量架构、多媒体SIMD指令集拓展、脉动阵列、gpu
(3)线程级并行
多处理机,多核,多线程

















 1882
1882

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









