








目录
要下载该项目,您也可以访问我的GitHub存储库,网址为:
此外,您可以通过访问以下网站来试用Web应用程序:
介绍
在过去的几十年中,我们观察到人们对IT各个领域的兴趣急剧增长,这为大型企业提供了在线通过语音、视频和文本消息与世界和客户受众进行沟通的能力,这影响了许多基于云的在线消息传递应用程序的显着流行,包括Google和IBM Watson/Bluemix Assistant,Facebook Messenger,WhatsApp,Microsoft Bot Framework,Cisco Spark,Slack和其他个人平台和网站。
根据最新的调查,超过90%的人目前正在使用各种在线消息服务(或简称“聊天”)与外界进行交流。这些人中的许多人是在线购物者,在购买感兴趣的特定产品或服务时需要帮助。这反过来又鼓励许多现有的大型企业将其实时客户协助功能与大多数现有的在线信使集成在一起,从而有机会有效地宣传和推销他们提供的产品和数字内容。您可能已经知道,大约40%最受欢迎的产品和数字内容都在网上做广告并完全售罄,包括2018年的畅销书。每年,援助信使都成为任何网站广告和销售特定产品和服务的组成部分。
然而,通过即时通讯工具发布有关特定产品和服务的查询的客户受众仍在不断增加,逐渐导致提供特定帮助和帮助的渠道上出现巨大的工作量和“瓶颈”,中断了与各自客户的沟通,需要帮助。
后来,这些企业透露,他们不再能够提高其频道带宽,也无法增加接收和传输来自客户或向客户发送消息的消息传递渠道的实际数量。在这种情况下,解决以下严重问题的最有效方法是维护客户协助流程的一部分并将其委托给自动消息传递助手(或“聊天机器人”)。反过来,这可以有效地减少消息传递渠道上的潜在工作量,为简单的查询和常见问题(FAQ)提供答案。如今,大多数现有的在线技术援助和支持信使都将聊天机器人作为永久和不可或缺的功能。
“聊天机器人”(定义)——是一种计算机程序或人工智能(AI),可在企业与其客户受众之间提供基于文本或音频的对话功能,而无需与人类助手进行交互。聊天机器人本身是专门设计的,可以模拟对查询的理解,并在发布回复时生成人类语音。大多数现有的聊天机器人都能够模拟人类对话伙伴,因此通过了著名的艾伦图灵智力标准测试。如今,聊天机器人被用于公共消息应用程序或公司内部平台(如技术支持、人力资源或物联网)的两个常见目的。
有各种已知的策略可以创建和部署聊天机器人,旨在模拟对话。所有这些策略都主要基于使用自然语言理解(NLU),无论是基于规则的还是统计的。
基于规则的自然语言处理器是第一个早期的语言处理系统。自然语言分析的整个过程基本上依赖于硬编码的英语语法规则集。基于规则的NLP的主要问题是,在分析任意且不太正确的英语语法时,没有提供所需的自然语言理解质量。
基于统计的自然语言处理器是另一种自然语言的低估功能,后来在1980年代初发明。以下类型的语言处理器主要基于使用人工神经网络(ANN)和各种机器学习(ML)算法。这些算法和模式中的大多数都使用统计数据模型来自动学习那些英语语法规则,这些语法规则基于过去人类发布到聊天机器人的文档和短语语料库。基于统计的方法的主要缺点是,基于ANN的自然语言处理器学习揭示和识别语法规则的时间通常很长。在这种情况下,文档语料库通常必须很大,并且包含许多正确和不正确的短语。此外,很难找到一个关于特定主题的现有文档语料库,其中包含可用于新聊天的基于ANN的自然语言处理器训练目的的短语。
在当今的现实世界中,在创建和部署聊天引擎时,我们基本上已经处理了一种所谓的“混合”类型的自然语言处理器(NLP),它依赖于基于规则和统计的语言处理方法。
在本文中,我们将深入讨论如何创建和部署基于自然语言处理(NLP)引擎的智能自定义聊天机器人,该引擎使用Node.js开发。具体来说,我们将演示如何维护基于语义网络和一系列算法的高效人类自然语言识别引擎(NLU/NLRE),该算法可以有效地查找和识别作为查询发送到自动协助聊天机器人引擎的短语和话语中的意图和目标。
特别是,我们将讨论如何基于语义图(即网络)的逻辑正确有效地构建聊天的知识库数据模型,其中安排了最“有用”的语言概念,并与客户问题的正确答案相关联,发布到技术援助聊天中。最后,以下方法允许形成一个“有限”的概念词典,语言理解过程基本上依赖于它。
本文详细讨论的自然语言处理算法,根据其性质,是一种高效的基于规则的算法,可用于在传递给自然语言处理引擎输入的句子中查找意图和语法谓词的所有可能变体。以下算法允许我们通过确定每个意图或语法谓词(由语言解析器从句子中提取)与各种语义概念集之间的相关性来找到每个人类短语的一般含义。它只是将从句子中检索到的每个意图与上面提到的语义知识库中的每个概念进行匹配。以下过程实际上称为“语义解析”或“词义消歧”。对于最相关的意图和概念,它为给定的查询提出正确答案的建议。
通常,与过去其他早期基于规则的方法和算法相比,本文讨论的自然语言处理引擎提供了高效率的自然语言理解,并且可以用作许多现有基于统计的引擎的良好替代方案,尤其是那些计算文档主题的总体置信度值或提供仅有有关文档中经常出现的关键字的详细统计信息的引擎。
背景
本文的主要目的是向读者介绍自动聊天机器人助手开发的许多方面。在本文的第一章中,我们将讨论通用的聊天机器人助手解决方案架构,以及允许快速轻松地创建和部署各种聊天机器人的开发方案,这些聊天机器人依赖于基于规则的自然语言处理(NLP)引擎和决策过程,制定为计算机算法,而不是人工智能。在随后的章节中,我们将讨论可用于维护基于规则的自然语言处理引擎的算法系列,该引擎能够执行人类提交的文本消息的分析。具体来说,我们将引入一个“有用”语言概念的语义网络,以数据模型表示,自然语言理解(NLU)的整个过程和决策基本上都依赖于它。此外,我们将制定一个决策算法,用于根据一个或多个特定标准为每个特定查询找到正确答案的建议,由NLP引擎处理。在最后一章“使用代码”中,我们将讨论开发过程本身,特别是演示如何使用Node.js、HTML5、Angular 2和MySQL创建聊天机器人助手引擎。
现代聊天机器人。幕后花絮...
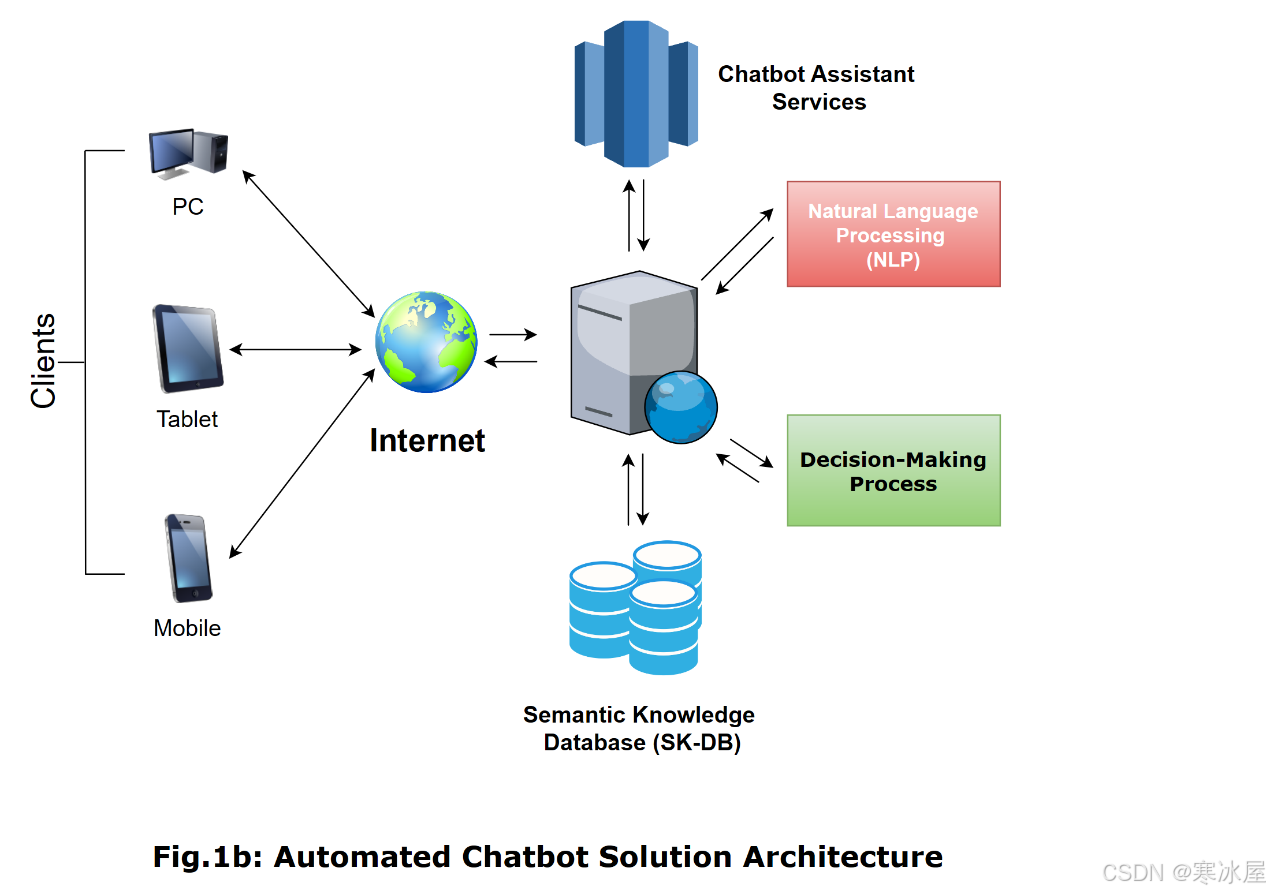
在本章中,我们将讨论正在创建和部署的集成方案,该方案对于大多数现有的聊天机器人助手和其他自动即时通讯工具(IM)来说非常常见。具体来说,我们将深入研究聊天机器人助手解决方案架构,将讨论集中在本文介绍的整个聊天机器人解决方案中的每个特定组件、流程或模型上。
根据互联网和万维网(WWW)的主要思想,聊天机器人通常构建为软件即服务(SaaS)解决方案,使客户能够使用他们的设备(台式PC或移动设备和平板电脑)与聊天机器人进行通信。
在大多数情况下,自动聊天机器人是一种软件解决方案,由两个主要层组成。具体来说,聊天机器人的前端Web应用程序是第一层,它非常简单,并且与万维网上现有的其他服务相同。换句话说,以下层是一个中间件,分别在用户和聊天机器人之间提供所需的交互。主应用程序的HTML网页包含一个嵌入式可视化容器,部署了一个“小部件”,使客户能够输入和发布他们的查询,并且还呈现从聊天机器人助手服务收到的响应。事实上,聊天机器人Web应用程序的后台服务在可供在线客户端使用的Web应用程序和第二层之间传输传入的请求,将在下一段中讨论。
第二层实际上是聊天机器人助手引擎,它比前端Web应用程序本身更复杂。它提供了从特定Web应用程序的第一层接收文本消息查询作为请求的基本功能,并通过执行自然语言分析并就这些查询的正确答案建议做出决定来处理这些请求。该层包括以下组件和流程,例如聊天机器人助手服务、处理传入的客户请求、自然语言处理引擎(NLP)、对到达的文本消息执行分析、查找各种答案建议的决策过程,以及语义知识数据库(SK-DB),用于将语言语义数据存储在“有用”概念的语料库上,NLP引擎和决策过程基本上依赖于它。此外,我们将提供正在讨论的架构中每个特定组件或过程的详细说明。与许多现有的聊天机器人助手服务架构相比,本文中讨论的聊天机器人架构表示要简单得多。为简单起见,我们在NLP引擎和决策过程中结合了特定的组件和流程,例如自然语言生成(NLG)和消息传递后端(MB)。
通常,现代聊天机器人是一个集中的多层解决方案,包括以下组件和流程:
- 前端Web应用程序旨在提供多个客户端和后台聊天机器人助手服务之间的互连。
- 聊天机器人助手服务处理传入的请求,包含特定的文本消息,将它们转发到自然处理引擎(NLP),并接收有关决策过程中最正确答案建议的数据。
- 自然语言处理引擎(NLP)通过对传入文本消息中每个特定短语的语法谓词进行分析来完成大部分查询请求处理。
- 决策过程接收来自NLP引擎的特定请求,其中包含NLP引擎从文本消息中提取的意图和术语,并在聊天机器人的知识数据库中执行搜索,以找到最合适的建议,以根据特定标准回答每个特定查询。
- 语义知识数据库(SK-DB)存储一个语言语义网络,表示为“有用”概念语料库上的数据,由自然处理引擎或决策过程用于执行语法谓词分析和正确答案查找建议。
本文讨论的聊天机器人助手架构如图1a所示,如下所示:

根据上面显示的架构,客户使用其本地Web浏览器访问聊天机器人助手网站。在聊天机器人网站的主页上,他们输入并发布他们的查询,与聊天机器人消息传递“小部件”进行交互,该小部件将输入的文本消息定向到网站的主要应用程序服务。消息传递“小部件”本身是一个特殊功能,作为网站主页的一部分实现,通常是HTML和JavaScript嵌入的代码片段。此代码基本上从网页的文本区域控件中检索文本消息数据,并将包含这些数据的特定Ajax请求发布到应用程序的后台服务,该服务接受这些请求,并简单地通过建立的请求管道将它们转发到聊天机器人助手服务。
然后,聊天机器人助手服务将这些请求重定向到NLP引擎,即通过对请求中的文本消息执行基于规则的分析来处理到达的新请求,根据存储在语义知识数据库中的“有用”概念语料库,从每个特定短语中确定和检索意图和术语集,如下所述。NLP引擎基本上依赖于将当前短语中的每个语法谓词与语义知识数据库中可能的概念数据集进行匹配的过程。以下过程将在本文的后续章节中详细讨论。由于所有可能的意图和术语都成功地从短语中提取出来,因此NLP引擎正在将包含特定数据的请求转发给决策过程。反过来,决策过程将这些数据作为请求接收,并在语义知识数据库中执行搜索,以根据特定标准为每个查询找到最合适的答案建议。
此外,还有多种方法可以创建和部署决策过程,基于规则或人工神经网络(ANN)。在本文中,我们将只讨论基于规则的流程,快速可靠。
最后,找到正确答案的建议数据集被转发回聊天机器人助手服务,随后,聊天机器人助手服务将它们重定向到前端Web应用程序,作为对特定Ajax请求的响应。由于已经收到包含正确答案建议数据的Ajax响应,因此应用程序主网页的“小部件”功能通过执行JavaScript代码来呈现答案的建议列表,该代码动态处理特定的文本区域控件以显示响应消息列表。
在上面的段落中,我们已经彻底讨论了基本的聊天机器人助手服务功能。然而,通过将所有这些组件和流程组合到一个Web应用程序中,可以简化许多现有聊天机器人的真实架构,从而完成所有这些任务。聊天机器人助手架构的简化表示如下图1b所示。
自然语言处理引擎(NLP)
自然语言理解(NLP)引擎是正在创建和部署的自动聊天机器人助手的核心组件。本文讨论的NLP引擎是一个基于规则的引擎,基本上依赖于使用一系列文本消息解析器,这些解析器执行语法谓词分析,以便从给定的文本消息中检索意图和术语集。NLP引擎进行的自然语言理解的整个过程在逻辑上可以分为多个阶段,从句子标记和词性(POS)标记开始,到语言谓词解析结束。
NLP引擎接收文本消息作为请求,并通过执行基于将整个消息文本拆分为一组特定句子的多个规则的句子标记化来执行初始文本消息规范化。之后,一组句子标记被传递到执行词性(POS)标记的引擎中,结果,返回词性标记集,例如动词、名词、形容词和副词,这些标记保留在输入文本消息中。这些集合使用存储在语义知识数据库中的数据进一步规范化。此外,在此阶段,将执行随机语法分析以检索主要的持久实体并计算每个实体的基于事件的统计信息。最后,NLP引擎执行“侵略性”语言谓词解析和过滤,以根据句子数组和pos-tags字典中的数据从输入文本消息中检索意图和术语集。执行自然语言理解(NLU)的结果是从输入消息中检索到的一组意图和术语,并转发到决策过程,如上所述。
句子标记化
NLP处理的第一阶段是句子标记化。在开发周期中,我们将基于条件字符串拆分的过程,制定并使用以下句子分词算法:
- 按每个“标点符号”('.',',','!','?’)拆分文本消息字符串;
- 按其“连词”('and'、'or'、'nor'、'but')拆分文本消息字符串;
- 按“代词”('either','neither','also','as well','too')拆分文本消息字符串;
- 用“副词”('also'、'as well'、'too')拆分文本消息字符串;
- 按“否定”拆分文本消息字符串('not','don't','doesn't','haven't, ...);
为了执行实际的条件拆分,我们通常可以使用通用框架例程,以及使用算法的自定义拆分器,该算法在本文的“使用代码”一章中已实现和进一步讨论。作为执行条件拆分的结果,我们将获得一组句子,在NLP处理的下一阶段进行分析。
大多数基于规则的NLP引擎使用所谓的“基于距离”的解析算法,其中一个问题是“距离”问题。例如,假设我们有一条由两句话组成的短信:“我想创建一个频道。另外,我想删除工作区“。显然,在没有距离标准的情况下分析该文本片段时,最常见的意图是“创建通道”、“创建工作区”、“删除通道”和“删除工作区”,这通常是错误的分析结果,造成误解,因此,NLP处理质量一般较差。执行句子标记化使我们能够有效地限制特定操作和实体之间的距离,将查找意图的过程单独限制在每个特定句子上,并具有较小的距离度量。例如,如果我们用标点符号拆分了上面的整个文本消息,我们将获得两个单独分析的句子。在这种情况下,我们将得到更合适的结果,例如一组以下意向:“创建频道”和“删除工作区”,依此类推。句子标记化是一个非常重要的阶段,总体上会影响整个NLP过程的质量。
词性(POS)标记
在进行句子标记化并获取一组句子后,根据本章讨论的NLP算法,我们基本上需要对每个特定句子进行词性(POS)标记。在这个过程中,我们基本上会对当前句子中的每个单词进行类别分类,确定其词性,例如动词、名词、形容词或副词。pos-tagging的整个过程基本上依赖于各种语言解决方案,无论是本地的还是基于云的,都为特定语言提供在线词典服务。执行pos标记结果的最常见示例如下:
输入短语 =“我想创建一个频道...”
POS = { '名词': ['I','channel','want'], 'verbs': ['want','create'] }
与其他NLP解决方案不同,在这种特殊情况下,我们基本上通过将pos-tagging的最终结果与语义知识数据库中存在的“名词”(即“实体”)和“动词”(即“动作”)进行匹配来执行所谓的pos规范化。具体来说,我们的目标是过滤掉所有不属于存储在语义知识数据库中的语料库中任何概念的pos标签。执行这种规范化的主要思想是,我们需要从结果中删除所有pos标签,实际上与对话主题无关。通过这样做,我们将收到以下结果:
输入短语 =“我想创建一个频道...”
POS = { '名词': ['channel'],'verbs': ['create'] }
其他pos标签由于不相关而被省略,因此在这种特殊情况下是多余的。我们将在后面描述语义知识数据库的章节中回到对这个主题的相同讨论。
随机语法
NLP处理的另一个阶段是随机语法分析。在此分析中,我们基本上找到了每个特定位置标签出现的统计数据,不包括所有词性,但“名词”。进行随机语法分析是为了过滤所有出现次数最多的pos标签(即名词)。当我们尝试使用NLP引擎来分析仅包含名词或难以分析的模糊语音片段时,此阶段非常有帮助。执行随机语法分析的算法非常简单,在本文的“使用代码”一章中进行了深入讨论。
语言谓词解析
语言谓词解析是NLP引擎执行的自然语言理解的主要阶段。正如我们已经提到的次数,本文中介绍的NLP引擎是基于规则的引擎,仅依靠使用一系列解析器来完成分析任务,旨在从执行前面阶段获得的每个句子中提取各种语法谓词。
具体来说,在本章中,我们将介绍NLP引擎,该引擎基于使用三个主要的文本数据解析器来执行分析。分析本身就是语法谓词的提取过程,用于查找和这些类型的谓词:
- “动词”+“形容词”+“名词”+“否定?
- “名词”+“形容词”+“动词”+“否定?
- “名词”+“形容词”+“名词”+“否定?
实际上,我们通过使用三个主要解析器来解析传递给NLP引擎输入的每个特定句子,试图找到并检索上面列出的那些类型的语法谓词。此外,在执行实际解析之前,每个特定的句子都会被拆分为一个单词数组,由空格字符分隔。
我们将要讨论的第一个是基于规则的解析器“动词”+“形容词”+“名词”+“否定”。以下解析器可以表述为下面列出的算法:
- 给定一组令牌|D|={ w1,w2,w3,...,wn-1,wn };
- 对于当前令牌w(k),检查此令牌是否为“谓词”;
- 如果没有,请继续下一个令牌w(k+1)并返回到步骤1,否则继续下一步;
- 在前面的标记|D|[0,K-1]的子集中查找所有“负数”的集合(如果存在);
- 将每个否定w(r)与当前动词w(k)配对并进入下一步;
- 在后续标记|D|[k + 1,n]的子集中查找所有“名词”的集合;
- 将每个名词w(t)与当前动词w(k)配对,然后进入下一步;
- 继续下一个令牌w(k + 1)并转到步骤1;
- 根据“名词”+“动词”+“否定?”对生成一组意图;
根据上面列出的算法,基于以下原则生成意图集。首先,对于每个“动词”标记,我们发现所有负数都持续存在于标记数组中并生成特定的对。然后我们找到所有“名词”,并将每个名词与每对“动词”+“否定?”相关联,获得所有可能的语法谓词的列表,只要输入句子存在。
然后,我们将解析“名词”+“形容词”+“动词”+“否定”和“名词”+“形容词”+“名词”+“否定”语法谓词,使用与上面介绍的非常相似的算法。最后,我们将找到的所有各种意图合并到整个意图集中,并将以下数据传递给决策过程进行进一步分析。下面的示例演示了以下过程。
假设我们有一组短信句子,例如“我想创建一个工作区和频道”、“我还不想加入我的公司”。
句子 #1 = “I”,“want,“to,“create,“a”,“workspace”,“and”,“channel”。
在这一点上,我们的目标是找到句子中的每个“动词”。显然,“want”这个词是第一个被发现的动词。之后,我们将执行检查子集中是否没有负数。显然,以下一组令牌不包含任何否定因素。因此,我们将继续查找集合中的所有“名词”。在本例中,我们找到了以下一组“名词”:[ “workspace”,“channel” ]。最后,我们将每个当前的“动词”标记与每个“名词”标记配对,最终得到以下结果:
'action': 'want', 'entity': 'workspace'
'action': 'want', 'entity': 'channel'
'action': 'create', 'entity': 'workspace'
'action': 'create', 'entity': 'channel'
上面列出的这些对实际上是由动作和实体属性组成的意图,与找到的每个“动词”和“名词”完全对应。
句子 #2 = “I”、“don’t”、“want”、“to”、“onboard”、“my”、“company”、“yet”
在这种情况下,下面的句子包含两个“动词”,即“want”或“onboard”。此时,我们正在执行检查每个“动词”之前是否至少有一个“否定”。显然,这句话中有一个否定的“don’t”,我们将与找到的每个特定的“动词”配对:
'negative': 'don’t', '动词':want,
'negative': 'don’t', '动词':onboard
然后,显然,我们的目标是找到这句话中的所有名词。实际上,以下一组标记只包含一个“名词”——“company”,它将与每个“否定”+“动词”对配对:
'negative':'don’t', '动词': want, '名词': company
'negative':'don’t', '动词': onboard, '名词': company
在最后一点上,NLP分析的过程结束了,使用本章讨论的算法生成的意向集将作为请求传递给决策过程。
决策过程
决策是NLP分析过程的最后阶段,它基于从输入文本消息中检索到的意图和术语集,以及存储在语义知识数据库中的“有用”概念语料库的数据。决策过程的主要目标是根据从NLP引擎收到的意图和术语数据,找到最合适的答案的建议。为此,我们将制定并使用以下算法:
- 给定一组意向|S|= { s1,s2,s3,...,sn-1,sn },摘自文本消息和概念语料库|P|={ p1,p2,p3,...,pm-1,pm },存储在语义知识数据库中;
- 取当前意图“操作”+“实体”s(i);从集合|S|;
- 从概念|P|语料库中获取当前概念 p(j);
- 对于当前对(s(i), p(j))执行检查“action”和“entity”值是否相同。此外,检查s(i)和p(j)是否都设置了负属性。如果条件为“true”,则转到下一步,否则继续执行步骤5;
- 将与当前概念关联的答案建议附加到答案建议集;
- 继续下一个概念p(j+1)并返回步骤 3;
- 继续下一个目的s(i+1)并返回到步骤 2;
根据以下算法,我们实际上是在迭代一组意图,并针对每个特定意图执行线性搜索,以找到具有相似“动作”和“实体”以及相似负属性的概念。对于满足条件的每个概念,我们都会得到一个特定的答案建议。
例如,在前面的示例中,我们有一组由NLP引擎找到的意向:
'action': 'want', 'entity': 'workspace'
'action': 'want', 'entity': 'channel'
'action': 'create', 'entity': 'workspace'
'action': 'create', 'entity': 'channel'
此外,我们还拥有一系列“有用”概念,例如:
'action': 'create', 'entity': 'workspace', 'answer': 'answer#1'
'action': 'create', 'entity': 'channel', 'answer': 'answer#2'
'action': 'delete', 'entity': 'channel', 'answer': 'answer#3'
'action': 'migrate', 'entity': 'company', 'answer': 'answer#4'
让我们从一组意图中获取第一个意图(例如,“action”: 'want', 'entity': 'workspace')。然后,让我们遍历概念集,并针对每个概念执行检查其“操作”和“实体”值是否等于当前意图的相应值。在本例中,这些值对于上述集中的第一个概念是相同的。因此,我们从第一个概念中获取“答案”值,并将其附加到答案建议集。实际上,我们将对集合中的每个意图和每个概念执行完全相同的操作。因此,我们将获得以下一组答案建议:
答案 = { 'answer#1', 'answer#2' };
根据下一章讨论的区别性和消歧限制,概念集中的其他答案被简单地省略了,因为它们与探究主题无关。
语义知识数据库
正如我们之前在上一章中所讨论的,整个决策机制基本上依赖于存储在语义知识数据库中的数据。在这种情况下,该数据用于根据NLP引擎从每条文本消息中检索到的意图和术语之间的相似性标准以及存储在语义知识数据库中的“有用”概念的预定义意图样本来查找最合适的答案建议的数据集。
在本章中,我们将讨论如何构建语义知识数据模型,与NLP/NLU解决方案中使用的大多数现有语义模型相比,该模型略有不同。术语“语义知识数据库”的含义与另一个术语(例如“语义知识库”或“语义网络”)非常接近。为了表示常规语义网络中的特定“概念”,我们使用了三元组(“名词”+“动词+”名词“),也称为语法谓词,然后建立了特定概念之间的所有可能关系。当然,这种特殊方法对于那些通常用于聊天机器人助手和即时通讯工具的NLP引擎来说并不完美。
相反,我们将讨论语义数据模型,其中所有“概念”都由“元组”表示,例如(“动词”+“形容词”+“名词”),(“名词”+“形容词”+“名词”),......这些元组中的每一个都是语法谓词的另一种形式,代表所谓的“意图”。“意图”一词基本上是指人类承诺执行一些所需的行动来修改状态,或者特别是主体或实体本身。每个元组中的“动词”通常映射到特定的动作,而“名词”是应用这些动作的主语或实体。例如:“创建工作区”、“删除共享频道”、“迁移公司”......一个特例是由两个名词组成的元组,其中第一个名词与主语或实体完全匹配,另一个名词与动作本身的过程完全匹配,反之亦然。例如:“创建工作区”、“入职公司”、“添加免费软件应用程序”......这两种类型的元组都可以选择性地在任意位置包含描述主语或实体的“形容词”,例如:“shared”、“freeware”是描述相关主语或实体的形容词(例如,“channel”和“application”)。此外,还有两种类型的元组,“正”或“负”。否定元组也可能包含否定副词,在大多数情况下,描述无法采取行动,例如“我无法创建工作区”、“我想创建一个频道而不是加入我的公司”、......语法谓词中的否定性通常用于提供短语的否定意义或所谓的“操作失败”属性,这有利于在对操作进行故障排除时更好地理解。所提出的语义模型如图3所示。下面。
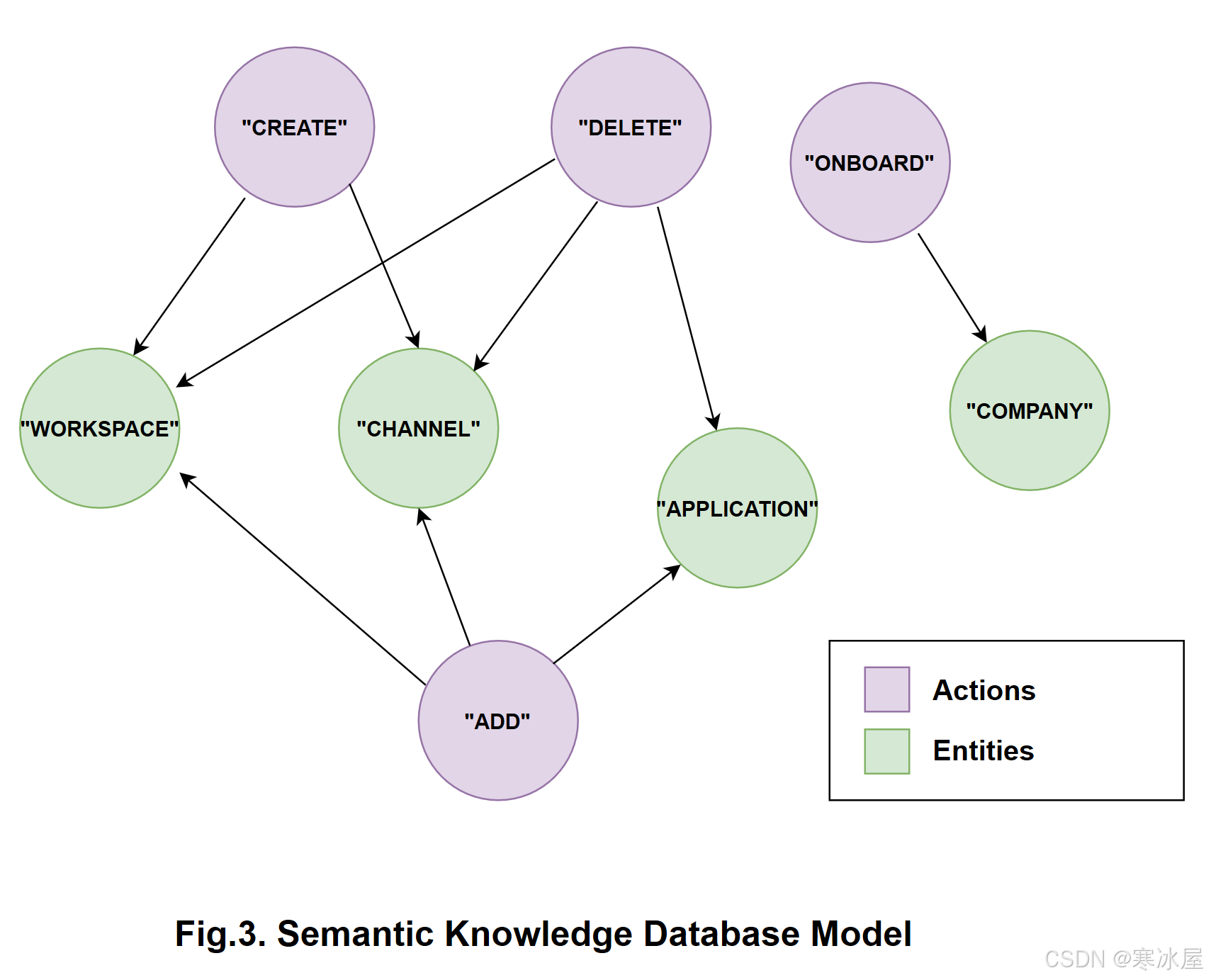
如上图所示,以下语义图的“顶点”基本上分别映射到“动作”或“实体”。反过来,该图的“边”通常表示特定实体和操作之间的关系。在下一段中,我们将简要讨论如何以“有用”概念数据库的形式表示以下语义图。
根据所引入的语义模型,知识数据库中的每个“概念”基本上由一个或多个样本“意图”以及与之相关的“答案”或“响应”组成。每个包含样本“意图”+“答案”的概念是决策过程使用的数据,用于根据NLP引擎从人类短语中检索到的意图与从现有知识库中特定概念中检索的样本意图之间的相似性度量标准,从知识库中查找答案建议。
从语义网络到自适应知识数据库......
本章讨论的方法允许我们将通用语义模型转换为更简单的语义模型,快速轻松地部署为常规数据库,旨在存储“有用”概念的数据集,而不是以更复杂的多维数据结构排列的语义数据。图4所示为“有用”示例概念数据集的示例,如下所示。

从上面的示例中可以看出,整个数据库由概念组成,每个概念都具有多个属性,例如操作和实体、描述性标记、否定性属性,最后是与特定概念相关的答案,以及其他杂项属性,例如引用URL。“实体”是每个概念的“关键”属性,明确描述一个“主题”,可以对其应用一个或多个操作。在NLP引擎执行的随机语法分析期间,使用样本实体集上的数据来揭示给定短语的一般含义。
由每个“动作”和“实体”组成的基于意图的不同概念集构建了语言知识库的所谓“词典”,在语言理解过程中,受益于更好的意图和术语的歧义消除,由NLP引擎执行。正如我们已经讨论过的,NLP引擎在词性(POS)标记阶段,创建了一个包含所有可能的动词和名词的“字典”,与知识库中的特定“动作”和“实体”完全对应。该动词和名词词典被NLP引擎和决策过程用作词典,消除了NLP引擎无法从给定短语中检索特定意图和术语的情况,以及检索与以下会话主题无关的不必要的冗余语音片段。
假设我们有一个如上图所示的语义知识库,以及诸如“我想创建工作区、骑马并删除共享频道”之类的短语。在pos-tagging阶段,NLP引擎在给定短语中创建一个单词(即动词和名词)的字典,过滤掉那些在下面的语义知识库中不作为“动作”或“实体”出现的单词。pos-tagging 的结果必须如下:
输入短语 = “I want to create workspace, ride a horse and also delete a shared channel”;
字典 = { 'verbs': ['create', 'delete'], 'nouns': ['workspace', 'channel'], 'adj': ['shared'] };
从上面的例子中可以看出,“ride”和“horse”,以及“I”、“want”、“to”、“also”、“a”等词被简单地从字典中排除,因为这些都是多余的词,与调查的主题没有任何共同之处。
语义知识库词典本身的“独特性”是非常重要的方面,对NLP引擎执行的语言理解质量有很大影响。
稍后,在“使用代码”一章中,我们将彻底讨论如何创建和部署关系数据库来存储“有用”概念的语料库,我们在本章中已经深入讨论了这些概念。
使用代码
在本章中,我们将讨论在Node.js、JavaScript/jQuery、HTML5、CSS、MDBootstrap4、Angular2和MySQL中开发Web应用程序,以执行输入文本消息的自然语言处理(NLP)。
前端Web应用程序
该应用程序的主页旨在提供用户与NLP引擎之间的交互,作为Web应用程序的后台服务运行。以下HTML文档是使用HTML/CSS和MDBootstrap4创建的。我嵌入了引导程序强大的导航栏,以支持在两个主要选项卡之间导航,呈现允许输入和提交用户查询的输入文本区域,或语义知识数据库内容的图表,这反过来又提供了用户查看、修改或删除语义知识数据库条目的能力。此外,主应用程序的HTML文档包括使用CSS-bootstrap设计的模式对话框的数量。这些模态用作子组件或响应式UI增强功能,在编辑语义知识数据库的内容时支持用户输入。下面列出了实现Web应用程序主页的完整HTML代码:
views/index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no">
<meta http-equiv="x-ua-compatible" content="ie=edge">
<title>NLP-Samurai@0.0.10 Demo</title>
<!-- Font Awesome -->
<link rel="stylesheet" href="https://use.fontawesome.com/releases/v5.7.0/css/all.css">
<!-- Bootstrap core CSS -->
<link href="mdb/css/bootstrap.min.css" rel="stylesheet">
<!-- Material Design Bootstrap -->
<link href="mdb/css/mdb.min.css" rel="stylesheet">
<!-- Your custom styles (optional) -->
<link href="stylesheets/main.css" rel="stylesheet">
<!-- MDB core jQuery -->
<script type="text/javascript" src="mdb/js/jquery-3.3.1.min.js"></script>
<!-- Angular.js core -->
<script src="https://ajax.googleapis.com/ajax/libs/angularjs/1.2.23/angular.min.js">
</script>
<script type="text/javascript">
var concepts = angular.module('concepts', []);
concepts.controller('conceptsViewCtrl', function ($scope, $http) {
$http.post("/")
.then(function (response) {
$scope.model = response.data['model'];
});
$scope.scrollIntoView = function (elem, ratio) {
var answ_render_offset =
$(elem).offset();
answ_render_offset.left -= ratio;
answ_render_offset.top -= ratio;
$('html, body').animate({
scrollTop: answ_render_offset.top,
scrollLeft: answ_render_offset.left
});
}
$('#navbarSupportedContent-7 a[data-toggle="tab"]').
bind('click', function (e) {
e.preventDefault();
if ($(this).attr("href") == "#smdb") {
$scope.scrollIntoView("#smdb_renderer", 20);
}
});
$scope.onSendInquiry = function (inquiry) {
if ($("#responses").display == "block") {
$("responses").hide();
}
$http.post('/inquiry',
{ 'inquiry': inquiry, 'model': $scope.model }).then((results) => {
$scope.model.responses =
results["data"]["intents"].map(function (obj) {
return {
'action': obj["intent"]["action"],
'entity': obj["intent"]["ent"],
'response': obj["response"]
};
});
$("#responses").show();
$scope.scrollIntoView("#answers_renderer", 0);
});
}
$scope.onAddConceptModal = function () {
$scope.add_concept = true;
}
$scope.onViewAnswer = function (answer, url) {
$scope.answer_show = true;
$scope.answer = answer; $scope.url = url;
}
$scope.onUpdateConceptModal = function (concept) {
$scope.concept = concept;
$scope.concept_orig =
angular.copy($scope.concept);
$scope.update_concept = true;
}
$scope.onConfirmRemovalModal = function (concept_id) {
$scope.concept_id = concept_id;
$scope.confirm_removal = true;
}
$scope.onRemoveConcept = function () {
$scope.model = $scope.model.filter(function (obj) {
return obj['id'] != $scope.concept_id;
});
}
});
concepts.directive('addNewConceptModal', function () {
return {
restrict: 'EA',
link: function (scope, element, attributes) {
scope.$watch('add_concept', function (add_concept) {
element.find('.modal').modal(add_concept ? 'show' : 'hide');
});
element.on('shown.bs.modal', function () {
scope.$apply(function () {
scope.concept = {};
scope.concept.negative = 'false';
scope.add_concept = true;
});
});
element.on('hidden.bs.modal', function () {
scope.$apply(function () {
scope.model.push(scope.concept);
scope.add_concept = false;
});
});
},
templateUrl: '/concepts'
};
});
concepts.directive('answerViewModal', function () {
return {
restrict: 'E',
link: function (scope, element, attributes) {
scope.$watch('answer_show', function (answer_show) {
element.find('.modal').modal(answer_show ? 'show' : 'hide');
});
element.on('shown.bs.modal', function () {
scope.$apply(function () {
scope.answer_show = true;
});
});
element.on('hidden.bs.modal', function () {
scope.$apply(function () {
scope.answer_show = false;
});
});
},
templateUrl: '/answers'
};
});
concepts.directive('updateConceptModal', function () {
return {
restrict: 'EA',
link: function (scope, element, attributes) {
scope.$watch('update_concept', function (update_concept) {
element.find('.modal').modal(update_concept ? 'show' : 'hide');
});
element.on('shown.bs.modal', function () {
scope.$apply(function () {
scope.update_concept = true;
});
});
element.on('hidden.bs.modal', function () {
scope.$apply(function () {
scope.update_concept = false;
scope.model[scope.concept_orig.entity].entity =
scope.concept.entity;
scope.model[scope.concept_orig.action].action =
scope.concept.action;
});
});
},
templateUrl: '/modify'
};
});
concepts.directive('confirmRemovalModal', function () {
return {
restrict: 'EA',
link: function (scope, element, attributes) {
scope.$watch('confirm_removal', function (confirm_removal) {
element.find('.modal').modal(confirm_removal ? 'show' : 'hide');
});
element.on('shown.bs.modal', function () {
scope.$apply(function () {
scope.confirm_removal = true;
});
});
element.on('hidden.bs.modal', function () {
scope.$apply(function () {
$scope.model.splice($scope.concept_id, 1);
scope.confirm_removal = false;
});
});
},
templateUrl: '/confirm'
};
});
</script>
</head>
<body ng-app="concepts" ng-controller="conceptsViewCtrl">
<header>
<!--Navbar-->
<nav class="navbar navbar-expand-lg navbar-dark fixed-top scrolling-navbar">
<div class="container">
<a class="navbar-brand" href="#">
<strong>NLP-Samurai@0.0.10 (Node.js Demo)</strong>
</a>
<button class="navbar-toggler" type="button" data-toggle="collapse"
data-target="#navbarSupportedContent-7"
aria-controls="navbarSupportedContent-7" aria-expanded="false"
aria-label="Toggle navigation">
<span class="navbar-toggler-icon"></span>
</button>
<div class="collapse navbar-collapse" id="navbarSupportedContent-7">
<ul class="nav navbar-nav mr-auto" id="myTab" role="tablist">
<li class="nav-item">
<a class="nav-link active" id="nlp-tab" data-toggle="tab"
href="#nlp" role="tab" aria-controls="nlp"
aria-selected="true">Natural Language Processing</a>
</li>
<li class="nav-item">
<a class="nav-link" id="smdb-tab" data-toggle="tab" href="#smdb"
role="tab" aria-controls="smdb"
aria-selected="false">Semantic Knowledge Database</a>
</li>
</ul>
</div>
</div>
</nav>
<!-- Full Page Intro -->
<div class="view" style="background-image: url('images/background.png');
background-repeat: no-repeat; background-size: cover;
background-position: center center;">
<!-- Mask & flexbox options-->
<div class="mask rgba-gradient d-flex justify-content-center align-items-center">
<!-- Content -->
<div class="container">
<!--Grid row-->
<div class="row">
<!--Grid column-->
<div class="col-md-6 white-text text-center text-md-left mt-xl-5 mb-5
wow fadeInLeft" data-wow-delay="0.3s">
<h2 class="h2-responsive font-weight-bold mt-sm-5">
Natural Language Processing Engine</h2>
<hr class="hr-light">
<h6 class="mb-4">Introducing NLP-Samurai@0.0.10
Natural Language Processing Engine - a Node.js framework
that allows to find and recongize intents and grammar predicates
in human text messages, based on the corpus of 'useful' concepts
stored in sematic knowledge database, providing correct answers
to the most of frequently asked questions and other inquiries...
<br/><br/>Author: Arthur V. Ratz @ CodeProject (CPOL License)</h6><br>
</div>
<!--Grid column-->
<!--Grid column-->
<div class="col-md-6 col-xl-5 mt-xl-5 wow fadeInRight" data-wow-delay="0.3s">
<img src="./images/nlp.png" alt="" class="img-fluid">
</div>
<!--Grid column-->
</div>
<!--Grid row-->
</div>
<!-- Content -->
</div>
<!-- Mask & flexbox options-->
</div>
<!-- Full Page Intro -->
</header>
<!-- Main navigation -->
<!--Main Layout-->
<main>
<div id="smdb_renderer"></div>
<div class="container">
<div class="tab-content">
<div class="tab-pane active" id="nlp" role="tabpanel" aria-labelledby="">
<!--Grid row-->
<div class="row py-5">
<!--Grid column-->
<div class="col-md-12">
<h2>What would you like to know about Slack Hub?</h2><br />
<div class="md-form my-0">
<div class="input-group">
<input ng-model="inquiry" id="inquiry"
class="form-control mr-sm-2" type="text"
placeholder="Type In Your Inquiry Here..."
aria-label="Type In Your Inquiry Here..." autofocus>
<a data-ng-click="onSendInquiry(inquiry)">
<i class="fas fa-angle-double-right fa-2x"></i></a>
</div>
<p style="font-size:12px">For example:
"I want to create a workspace and channel,
and also to find out how to migrate company to Slack..."</p>
</div>
<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit,
sed do eiusmod tempor incididunt ut labore et dolore magna
aliqua. Ut enim ad minim veniam, quis nostrud exercitation
ullamco laboris nisi ut aliquip ex ea commodo consequat.
Duis aute irure dolor in reprehenderit in voluptate velit
esse cillum dolore eu fugiat nulla pariatur. Excepteur sint
occaecat cupidatat non proident, sunt in culpa qui officia
deserunt mollit anim id est laborum.</p>
<div id="responses" style="display: none">
<table class="table">
<tr ng-repeat="resp in model.responses">
<td>
<div class="card">
<div class="card-body">
<h3><b>{
{resp.action}} {
{resp.entity}}</b></h3><br/>
{
{resp.response.answer}} Visit:
<a href="{
{resp.response.url}}" style="color: blue">
{
{resp.response.url}}</a>
</div>
</div>
</td>
</tr>
</table>
</div>
<div id="answers_renderer"></div>
</div>
</div>
</div>
<div class="tab-pane" id="smdb" role="tabpanel" aria-labelledby="">
<div class="row py-5">
<!--Grid column-->
<div class="col-md-12">
<h2>Semantic Knowledge Database...</h2><br />
</div>
<div class="col-md-12 text-md-right">
<button data-ng-click="onAddConceptModal()"
type="button" class="btn btn-primary">Add A New Concept</button>
</div>
<div class="col-md-12">
<table class="table table-hover">
<thead>
<tr>
<th>#</th>
<th>Action</th>
<th>Entity</th>
<th>Description</th>
<th>Is Negative?</th>
<th> </th>
</tr>
</thead>
<tbody>
<tr ng-repeat="concept in model track by concept.id">
<td>{
{ $index + 1 }}</td>
<td>{
{ concept.action }}</td>
<td><b>{
{ concept.entity }}</b></td>
<td>{
{ concept.desc }}</td>
<td>{
{ concept.negative }}</td>
<td>
<a data-ng-click="onViewAnswer
(concept.answer, concept.url)"
style="color:blue"><b>View Answer</b>
</a> |
<a data-ng-click="onUpdateConceptModal(concept)"
style="color:green"><b>Modify</b></a> |
<a data-ng-click="onConfirmRemovalModal(concept.id)"
style="color:red"><b>Remove</b></a>
</td>
</tbody>
</table>
<add-new-concept-modal></add-new-concept-modal>
<answer-view-modal></answer-view-modal>
<update-concept-modal></update-concept-modal>
<confirm-removal-modal></confirm-removal-modal>
</div>
</div>
</div>
</div>
</div>
</main>
<!-- SCRIPTS -->
<!-- Bootstrap tooltips -->
<script type="text/javascript" src="mdb/js/popper.min.js"></script>
<!-- Bootstrap core JavaScript -->
<script type="text/javascript" src="mdb/js/bootstrap.min.js"></script>
<!-- MDB core JavaScript -->
<script type="text/javascript" src="mdb/js/mdb.js"></script>
<!--Main Layout-->
<script type="text/javascript" src="mdb/js/compiled-4.7.1.min.js">
</script><script type="text/javascript">(function runJS()
{new WOW().init();})();</script>
</body>
</html>views/concepts.html:
<div class="modal fade" id="addConceptModal" tabindex="-1"
role="dialog" aria-labelledby="Add a new concept"
aria-hidden="true">
<div class="modal-dialog modal-side modal-bottom-right" role="document">
<div class="modal-content">
<div class="modal-header">
<h5 class="modal-title" id="addConceptModalLabel">
Add a new concept...</h5>
<button type="button" class="close" data-dismiss="modal"
aria-label="Close">
<span aria-hidden="true">×</span>
</button>
</div>
<div class="modal-body">
<input ng-model="concept.action" class="form-control mr-sm-2"
type="text" placeholder="Action" aria-label="Action" autofocus><br />
<input ng-model="concept.entity" class="form-control mr-sm-2"
type="text" placeholder="Entity" aria-label="Action" autofocus><br />
<input ng-model="concept.desc" class="form-control mr-sm-2"
type="text" placeholder="Description (i.e. Adjectives)"
aria-label="Description (i.e. Adjectives)" autofocus><br />
<textarea ng-model="concept.answer"
class="form-control rounded-0" id="answer" rows="6"
cols="6" placeholder="Answer"></textarea><br />
<textarea ng-model="concept.url"
class="form-control rounded-0" id="answerUrl"
rows="3" cols="6" placeholder="Url"></textarea><br />
<span>Is Negative? </span>
<select ng-model="concept.negative">
<option value="false" selected>No</option>
<option value="true">Yes</option>
</select>
</div>
<div class="modal-footer">
<button type="button" class="btn btn-secondary"
data-dismiss="modal">Close</button>
<button type="button" class="btn btn-primary"
data-dismiss="modal">Save changes</button>
</div>
</div>
</div>
</div>views/answers.html
<div class="modal fade" id="answersViewModal" tabindex="-1"
role="dialog" aria-labelledby="Answer..." aria-hidden="true">
<div class="modal-dialog" role="document">
<div class="modal-content">
<div class="modal-header">
<h5 class="modal-title" id="answerViewModalLabel">Answer...</h5>
<button type="button" class="close"
data-dismiss="modal" aria-label="Close">
<span aria-hidden="true">×</span>
</button>
</div>
<div class="modal-body">
<textarea class="form-control rounded-0"
id="answerContents" rows="6" cols="6">{
{answer}}</textarea><br />
<textarea class="form-control rounded-0"
id="answerUrl" rows="3" cols="6">{
{url}}</textarea>
</div>
<div class="modal-footer">
<button type="button" class="btn btn-secondary"
data-dismiss="modal">Close</button>
</div>
</div>
</div>
</div>views/updates.html
<div class="modal fade" id="conceptEditModal" tabindex="-1"
role="dialog" aria-labelledby="Edit Concept" aria-hidden="true">
<div class="modal-dialog" role="document">
<div class="modal-content" ng-controller="conceptsViewCtrl">
<div class="modal-header">
<h5 class="modal-title" id="conceptEditViewModalLabel">
Edit Concept...</h5>
<button type="button" class="close" data-dismiss="modal"
aria-label="Close">
<span aria-hidden="true">×</span>
</button>
</div>
<div class="modal-body">
<input type="hidden" name="concept_id" value="{
{concept.id}}" />
<input type="text" ng-model="concept.action"
class="form-control rounded-0" value="{
{concept.action}}" /><br />
<input type="text" ng-model="concept.entity"
class="form-control rounded-0" value="{
{concept.entity}}" /><br />
<input type="text" ng-model="concept.desc"
class="form-control rounded-0" id="desc" value="{
{concept.desc}}"><br />
<textarea ng-model="concept.answer"
class="form-control rounded-0" id="answer" rows="6"
cols="6">{
{ concept.answer }}</textarea><br />
<textarea ng-model="concept.url"
class="form-control rounded-0" id="answerUrl"
rows="3" cols="6">{
{concept.url}}</textarea><br />
<span>Is Negative?</span>
<select ng-model="concept.negative">
<option value="false">No</option>
<option value="true">Yes</option>
</select>
</div>
<div class="modal-footer flex-center">
<button class="btn btn-outline-danger"
data-dismiss="modal">Save</button>
<button class="btn btn-danger waves-effect" data-dismiss="modal">
Cancel</button>
</div>
</div>
</div>
</div>views/confirm.html
<div class="modal fade" id="confirmDeleteModal"
tabindex="-1" role="dialog" aria-labelledby="exampleModalLabel" aria-hidden="true">
<div class="modal-dialog modal-sm modal-notify modal-danger" role="document">
<!--Content-->
<div class="modal-content text-center">
<!--Header-->
<div class="modal-header d-flex justify-content-center">
<p class="heading">Are you sure?</p>
</div>
<!--Body-->
<div class="modal-body">
<i class="fas fa-times fa-4x animated rotateIn"></i>
</div>
<!--Footer-->
<div class="modal-footer flex-center">
<button data-ng-click="onRemoveConcept()"
class="btn btn-outline-danger" data-dismiss="modal">Yes</button>
<button class="btn btn-danger waves-effect"
data-dismiss="modal">No</button>
</div>
</div>
<!--/.Content-->
</div>
</div>在这种情况下,大多数事件处理任务由控制器执行Angular.js从而提供对用户输入的响应能力。此控制器在以下HTML文档的脚本部分中作为多个JavaScript函数实现。
当页面加载到Web浏览器中时,它通过执行以下代码来实例化angular模块对象:var concepts = angular.module('concepts', [])。之后,我们定义一个控制器和一个回调函数,实现加载数据模型机制,以及用于处理特定事件的函数数量,例如发送查询、添加概念、查看高级内容、更新或删除概念。具体来说,对后台Web应用程序的服务执行Ajax请求以从语义知识数据库中获取数据的代码在控制器的回调函数的开头实现,如下所示:
$http.post("/")
.then(function (response) {
$scope.model = response.data['model'];
});在这种情况下,每次加载页面时,通过调用jQuery的$http.post(…)函数发送Ajax请求,并将响应作为特定回调的参数传递。然后,它被复制到全局范围变量$scope.model中,该变量保存从数据库中获取的数据。
此外,控制器的回调函数包含处理用户输入事件的函数数的实现:
$scope.onSendInquiry = function (inquiry) {
if ($("#responses").display == "block") {
$("responses").hide();
}
$http.post('/inquiry', { 'inquiry': inquiry,
'model': $scope.model }).then((results) => {
$scope.model.responses =
results["data"]["intents"].map(function (obj) {
return {
'action': obj["intent"]["action"],
'entity': obj["intent"]["ent"],
'response': obj["response"]
};
});
$("#responses").show();
$scope.scrollIntoView("#answers_renderer", 0);
});
}
$scope.onAddConceptModal = function () {
$scope.add_concept = true;
}
$scope.onViewAnswer = function (answer, url) {
$scope.answer_show = true;
$scope.answer = answer; $scope.url = url;
}
$scope.onUpdateConceptModal = function (concept) {
$scope.concept = concept;
$scope.concept_orig =
angular.copy($scope.concept);
$scope.update_concept = true;
}
$scope.onConfirmRemovalModal = function (concept_id) {
$scope.concept_id = concept_id;
$scope.confirm_removal = true;
}
$scope.onRemoveConcept = function () {
$scope.model = $scope.model.filter(function (obj) {
return obj['id'] != $scope.concept_id;
});
}这些函数处理诸如查看概念高级数据、添加新概念、更新现有概念和删除特定概念等事件。此外,Angular.js代码包含指令函数的数量,负责呈现特定的模态和加载的模型修改:
concepts.directive('addNewConceptModal', function () {
return {
restrict: 'EA',
link: function (scope, element, attributes) {
scope.$watch('add_concept', function (add_concept) {
element.find('.modal').modal(add_concept ? 'show' : 'hide');
});
element.on('shown.bs.modal', function () {
scope.$apply(function () {
scope.concept = {};
scope.concept.negative = 'false';
scope.add_concept = true;
});
});
element.on('hidden.bs.modal', function () {
scope.$apply(function () {
scope.model.push(scope.concept);
scope.add_concept = false;
});
});
},
templateUrl: '/concepts'
};
});
concepts.directive('answerViewModal', function () {
return {
restrict: 'E',
link: function (scope, element, attributes) {
scope.$watch('answer_show', function (answer_show) {
element.find('.modal').modal(answer_show ? 'show' : 'hide');
});
element.on('shown.bs.modal', function () {
scope.$apply(function () {
scope.answer_show = true;
});
});
element.on('hidden.bs.modal', function () {
scope.$apply(function () {
scope.answer_show = false;
});
});
},
templateUrl: '/answers'
};
});
concepts.directive('updateConceptModal', function () {
return {
restrict: 'EA',
link: function (scope, element, attributes) {
scope.$watch('update_concept', function (update_concept) {
element.find('.modal').modal(update_concept ? 'show' : 'hide');
});
element.on('shown.bs.modal', function () {
scope.$apply(function () {
scope.update_concept = true;
});
});
element.on('hidden.bs.modal', function () {
scope.$apply(function () {
scope.update_concept = false;
scope.model[scope.concept_orig.entity].entity =
scope.concept.entity;
scope.model[scope.concept_orig.action].action =
scope.concept.action;
});
});
},
templateUrl: '/modify'
};
});
concepts.directive('confirmRemovalModal', function () {
return {
restrict: 'EA',
link: function (scope, element, attributes) {
scope.$watch('confirm_removal', function (confirm_removal) {
element.find('.modal').modal(confirm_removal ? 'show' : 'hide');
});
element.on('shown.bs.modal', function () {
scope.$apply(function () {
scope.confirm_removal = true;
});
});
element.on('hidden.bs.modal', function () {
scope.$apply(function () {
$scope.model.splice($scope.concept_id, 1);
scope.confirm_removal = false;
});
});
},
templateUrl: '/confirm'
};
});Web应用程序的后台服务代码在server.js文件中实现,如下所示:
server.js
'use strict';
var debug = require('debug');
var express = require('express');
var path = require('path');
var favicon = require('serve-favicon');
var logger = require('morgan');
var cookieParser = require('cookie-parser');
var bodyParser = require('body-parser');
var eventSource = require("eventsource");
var morgan = require('morgan');
var SqlString = require('sqlstring');
var db = require('./database');
var nlp_engine = require('./engine');
var con_db = db.createMySqlConnection(JSON.parse(
require('fs').readFileSync('./database.json')));
var routes = require('./routes/index');
var app = express();
app.engine('html', require('ejs').renderFile);
// view engine setup
app.set('views', path.join(__dirname, 'views'));
app.set('view engine', 'html');
// uncomment after placing your favicon in /public
//app.use(favicon(__dirname + '/public/favicon.ico'));
app.use(logger('dev'));
app.use(bodyParser.json());
app.use(bodyParser.urlencoded({ extended: false }));
app.use(cookieParser());
app.use(express.static(path.join(__dirname, 'public')));
app.use('/', routes);
app.post('/', function (req, res) {
let query = 'SELECT * FROM `nlp-samurai_db`.concepts_view';
db.execMySqlQuery(con_db, query).then((dataset) => {
var model_html = "\0", model = [];
dataset.forEach(function (data_obj) {
data_obj["negative"] =
(data_obj["negative"] == 0) ? "false" : "true";
data_obj["desc"] =
(data_obj["desc"] == 'NULL') ? "none" : data_obj["desc"];
model.push({
'id': data_obj["concept_id"],
'action': data_obj["action"],
'entity': data_obj["entity"],
'desc': data_obj["desc"],
'negative': data_obj["negative"],
'answer': Buffer.from(data_obj["answer"]).toString(),
'url': data_obj["url"]
});
});
if ((model != undefined) && (model.length > 0)) {
res.send(JSON.stringify({ 'model': model }));
}
});
});
app.post('/inquiry', function (req, res) {
var model_html = "\0", model = [];
req.body.model.forEach(function (data_obj) {
data_obj["negative"] =
(data_obj["negative"] == "false") ? 0 : 1;
model.push({
'intent': {
'action': data_obj["action"],
'ent': data_obj["entity"],
'desc': data_obj["desc"]
},
'response': {
'answer': Buffer.from(data_obj["answer"]).toString(),
'url': data_obj["url"]
}, 'negative': data_obj["negative"]
});
});
if ((model != undefined) && (model.length > 0)) {
nlp_engine.analyze(req.body.inquiry, model).then((results) => {
res.send(results);
});
}
});
// catch 404 and forward to error handler
app.use(function (req, res, next) {
var err = new Error('Not Found');
err.status = 404;
next(err);
});
// error handlers
// development error handler
// will print stacktrace
if (app.get('env') === 'development') {
app.use(function (err, req, res, next) {
res.status(err.status || 500);
res.render('error', {
message: err.message,
error: err
});
});
}
// production error handler
// no stacktraces leaked to user
app.use(function (err, req, res, next) {
res.status(err.status || 500);
res.render('error', {
message: err.message,
error: {}
});
});
app.set('port', process.env.PORT || 3000);
var server = app.listen(app.get('port'), function () {
debug('Express server listening on port ' + server.address().port);
});这段代码的基本部分基本上依赖于两个函数的实现,从应用程序的主网页接收Ajax请求并触发NLP引擎来执行分析:
app.post('/', function (req, res) {
let query = 'SELECT * FROM `nlp-samurai_db`.concepts_view';
db.execMySqlQuery(con_db, query).then((dataset) => {
var model_html = "\0", model = [];
dataset.forEach(function (data_obj) {
data_obj["negative"] =
(data_obj["negative"] == 0) ? "false" : "true";
data_obj["desc"] =
(data_obj["desc"] == 'NULL') ? "none" : data_obj["desc"];
model.push({
'id': data_obj["concept_id"],
'action': data_obj["action"],
'entity': data_obj["entity"],
'desc': data_obj["desc"],
'negative': data_obj["negative"],
'answer': Buffer.from(data_obj["answer"]).toString(),
'url': data_obj["url"]
});
});
if ((model != undefined) && (model.length > 0)) {
res.send(JSON.stringify({ 'model': model }));
}
});
});以下函数只是执行从nlp-samurai_db数据库中获取数据,并以JSON字符串格式发送数据模型作为响应。
app.post('/inquiry', function (req, res) {
var model_html = "\0", model = [];
req.body.model.forEach(function (data_obj) {
data_obj["negative"] =
(data_obj["negative"] == "false") ? 0 : 1;
model.push({
'intent': {
'action': data_obj["action"],
'ent': data_obj["entity"],
'desc': data_obj["desc"]
},
'response': {
'answer': Buffer.from(data_obj["answer"]).toString(),
'url': data_obj["url"]
}, 'negative': data_obj["negative"]
});
});
if ((model != undefined) && (model.length > 0)) {
nlp_engine.analyze(req.body.inquiry, model).then((results) => {
res.send(results);
});
}
});上面列出的以下函数执行NLP引擎触发,从主应用程序的网页接收Ajax请求并调用执行NLP分析的特定nlp_engine.analyze(req.body.inquiry, model)请求。从NLP引擎返回结果后,此函数将Ajax响应发送到主网页中的特定Angular控制器。
自然语言处理(NLP)引擎
在本小节中,我们将讨论NLP引擎实现语法谓词解析器的几个例程。具体来说,我们将学习如何执行文本消息的条件拆分,解析语法谓词并从这些消息中检索语调和术语,维护决策过程以及创建和部署语义知识数据库。
按条件将文本拆分为句子
作为NLP引擎的一部分编写的第一个函数是下面列出的split_by_condition(...)函数:
function split_by_conditions(tokens, callback) {
let index = 0, substrings = [];
while (index < tokens.length) {
if ((callback(tokens[index], index) == true) || (index == 0)) {
let prep_n = index, is_prep = false; index++;
while ((index < tokens.length) && (is_prep == false))
if (!callback(tokens[index], index)) index++;
else is_prep = true;
substrings.push(tokens.slice(prep_n, index));
}
}
if ((substrings != undefined)) {
return substrings.filter(function (sub) { return sub != ''; });
}
}此函数使用以下算法执行条件拆分。它遍历一个令牌数组,并针对每个令牌执行作为其参数之一传递的回调函数。在回调函数中,我们正在执行条件检查当前令牌是否满足特定条件。如果条件检查的结果为“true”,则它会找到另一个满足相同条件的令牌,该令牌位于成功令牌子集中的某个位置。最后,提取位于满足条件的第一个和第二个标记之间的其余标记并将其附加到数组中。
实现语法谓词解析器
整个NLP分析基本上依赖于执行语法谓词解析,正如我们在本文的背景章节中已经讨论的那样。下面列出了实现这些解析器的代码:
async function parse_verb_plus_noun(features, pos, concepts) {
return new Promise(async (resolve, reject) => {
var nouns = pos['nouns'];
var verbs = pos['verbs'];
var negatives = get_negatives(features);
var intents = [];
for (let index = 0; index < features.length; index++) {
if ((verbs.includes(features[index]) == true) &&
(negatives.includes(features[index]) == false)) {
let noun_pos = index + 1;
while (noun_pos < features.length) {
if (nouns.includes(features[noun_pos]) == true) {
intents.push({
'pos': [index, noun_pos],
'intent': {
'action': features[index],
'ent': features[noun_pos],
'negative': false
}
});
}
noun_pos++
}
}
}
for (let index = 0; index < intents.length; index++) {
var neg_pos = intents[index]['pos'][0];
while ((neg_pos >= 0) && !negatives.includes(
features[neg_pos])) neg_pos--;
if ((neg_pos != -1)) {
intents[index]['intent']['negative'] = true;
}
}
if ((intents != undefined)) {
resolve(intents.map((obj) => { return obj['intent']; }));
} else reject(0);
});
}
async function parse_noun_plus_verb(features, pos, concepts) {
return new Promise(async (resolve, reject) => {
var nouns = pos['nouns'];
var verbs = pos['verbs'];
var negatives = get_negatives(features);
var intents = [];
for (let index = 0; index < features.length; index++) {
if ((nouns.includes(features[index]) == true)) {
let verb_pos = index + 1;
while (verb_pos < features.length) {
if (verbs.includes(features[verb_pos]) == true) {
var neg_pos = verb_pos - 1, is_negative = false;
while (neg_pos >= index && !is_negative) {
is_negative = (negatives.includes
(features[neg_pos--]) == true);
}
intents.push({
'intent': {
'action': features[verb_pos],
'ent': features[index],
'negative': is_negative
}
});
}
verb_pos++;
}
}
}
if ((intents != undefined)) {
resolve(intents.map((obj) => { return obj['intent']; }));
} else reject(0);
});
}
async function parse_noun_plus_verb_rev(features, pos, concepts) {
return new Promise(async (resolve, reject) => {
var nouns = pos['nouns'];
var verbs = pos['verbs'];
var negatives = get_negatives(features);
var intents = [], verb_pos_prev = 0;
for (let index = 0; index < features.length; index++) {
if ((nouns.includes(features[index]) == true)) {
let verb_pos = index - 1, is_verb = false;
while (verb_pos >= verb_pos_prev && !is_verb) {
if (verbs.includes(features[verb_pos]) == true) {
var neg_pos = verb_pos - 1, is_negative = false;
while (neg_pos >= 0 && !is_negative) {
is_negative = (negatives.includes(
features[neg_pos]) == true);
if (verbs.includes(features[neg_pos]) == true) {
is_negative = false; break;
}
neg_pos--;
}
intents.push({
'intent': {
'action': features[verb_pos],
'ent': features[index],
'negative': is_negative
}
});
is_verb = true;
}
verb_pos--;
}
verb_pos_prev = verb_pos + 1;
}
}
if ((intents != undefined)) {
resolve(intents.map((obj) => { return obj['intent']; }));
} else reject(0);
});
}
async function parse_noun_plus_suffix_noun(features, pos, concepts) {
return new Promise(async (resolve, reject) => {
var nouns = pos['nouns'];
var verbs = pos['verbs'];
var negatives = get_negatives(features);
var intents = [];
for (let index = 0; index < features.length; index++) {
if ((nouns.includes(features[index]) == true)) {
var noun_pos = 0;
while (noun_pos < features.length) {
var is_suffix_noun = noun_suffixes.filter(function (suffix) {
return features[noun_pos].match('\\' +
suffix + '$') != undefined ||
features[noun_pos].match('\\' + suffix + 's$') != undefined;
}).length > 0;
if ((is_suffix_noun == true) &&
(nouns.includes(features[noun_pos]) == true)) {
intents.push({
'intent': {
'action': features[index],
'ent': features[noun_pos],
'negative': false
}
});
}
noun_pos++;
}
}
}
if ((intents != undefined)) {
resolve(intents.map((obj) => { return obj['intent']; }));
} else reject(0);
});
}维护决策过程
决策过程基本上依赖于执行以下代码:
module.exports = {
analyze: async function (document, concepts) {
return new Promise(async (resolve, reject) => {
await normalize(document, concepts).then(async (results) => {
let index = 0, nouns_suggs = [];
while (index < results['tokens'].length) {
const word_ps = new NlpWordPos();
var wd_stats = words_stats(results['tokens'][index]);
await word_ps.getPOS(results['tokens'][index]).then((details) => {
var nouns_stats = wd_stats.filter(function (stats) {
return details['nouns'].includes(stats['word']);
});
var nouns_prob_avg = nouns_stats.reduce((acc, stats) => {
return acc + stats['prob'];
}, 0) / nouns_stats.length;
nouns_suggs.push(nouns_stats.filter(function (stats) {
return stats['prob'].toFixed(4) >=
nouns_prob_avg.toFixed(4);
}));
});
index++;
}
var nouns = results['details']['nouns'];
var verbs = results['details']['verbs'];
var adjectives = results['details']['adjectives'];
var adverbs = results['details']['adverbs'];
var intents = results['tokens'], sentences = [],
intents_length = results['tokens'].length;
for (let index = 0; index < intents_length; index++) {
sentences = sentences.concat(split_by_conditions
(intents[index], function (intent) {
var is_entity = intents[index].filter(function (intent) {
return prep_list5.filter(function (entity) {
return intent.match('^' + entity);
}).length > 0;
}).length > 0;
return prep_list1.filter(function (value) {
return value == intent;
}).length > 0 && !is_entity;
}));
}
if (sentences.length > 0) {
intents = sentences;
}
intents_length = intents.length; sentences = [];
for (let index = 0; index < intents_length; index++) {
var intent_pos = 0;
sentences = sentences.concat
(split_by_conditions(intents[index], function (intent, n) {
let neg_pos = n - 1, has_negative = false;
while ((neg_pos >= intent_pos) && (!has_negative)) {
has_negative = negatives.includes(intents[index][neg_pos]);
if (has_negative == false)
neg_pos--;
}
var dup_count = intents[index].filter(function (token) {
return token == intent;
}).length;
var split = ((dup_count >= 2) &&
(!nouns.includes(intent) &&
!verbs.includes(intent) &&
!adjectives.includes(intent) &&
!adverbs.includes(intent) &&
!prep_list1.includes(intent) &&
!prep_list2.includes(intent) &&
!prep_list3.includes(intent) &&
!prep_list4.includes(intent) &&
!prep_list5.includes(intent)));
if (split == true) {
intent_pos = n;
}
return (split == true) && (has_negative == false);
}));
}
if (sentences.length > 0) {
intents = sentences;
}
var entity_intents = intents;
intents_length = intents.length; sentences = [];
for (let index = 0; index < intents_length; index++) {
sentences = sentences.concat
(split_by_conditions(intents[index], function (intent) {
return prep_list3.filter(function (value) {
return value == intent;
}).length > 0;
}));
}
if (sentences.length > 0) {
intents = sentences;
}
intents = intents.map(function (intents) {
return intents.filter(function (intent) {
return prep_list3.filter(function (prep) {
return prep == intent;
}).length == 0;
})
});
intents_length = intents.length; sentences = [];
for (let index = 0; index < intents_length; index++) {
sentences = sentences.concat(split_by_conditions
(intents[index], function (intent) {
var is_entity = intents[index].filter(function (intent) {
return prep_list5.filter(function (entity) {
return intent.match('^' + entity);
}).length > 0;
}).length > 0;
return negatives.filter(function (value) {
return value == intent;
}).length > 0 && !is_entity;
}));
}
if (sentences.length > 0) {
intents = sentences;
}
intents_length = intents.length; sentences = [];
for (let index = 0; index < intents_length; index++) {
sentences = sentences.concat(split_by_conditions(intents[index],
function (intent, n) {
let split = false;
var is_prep = prep_list2.filter(
function (value)
{ return value == intent; }).length > 0;
if (is_prep == true) {
if ((n > 0) && (n < intents[index].length - 1)) {
var is_noun_left = nouns.filter(function (noun) {
return noun == intents[index][n - 1];
}).length > 0;
var is_noun_right = nouns.filter(function (noun) {
return noun == intents[index][n + 1];
}).length > 0;
var is_verb_left = verbs.filter(function (verb) {
return verb == intents[index][n - 1];
}).length > 0;
var is_verb_right = verbs.filter(function (verb) {
return verb == intents[index][n + 1];
}).length > 0;
if ((prep_list4.includes(intents[index][n - 1])) ||
(prep_list4.includes(intents[index][n + 1]))) {
split = false;
}
else if ((is_noun_left = true) &&
(is_noun_right == true)) {
split = false;
}
else if (((is_noun_left == true) &&
(is_verb_right == true)) ||
((is_verb_left == true) &&
(is_noun_right == true))) {
split = (intent == 'or') ? false : true;
}
else {
var is_adj_left = adjectives.filter
(function (adjective) {
return adjective == intents[index][n - 1];
}).length > 0;
var is_adj_right = adjectives.filter
(function (adjective) {
return adjective == intents[index][n + 1];
}).length > 0;
var is_adv_left =
adverbs.filter(function (adverb) {
return adverb == intents[index][n - 1];
}).length > 0;
var is_adv_right = adverbs.filter
(function (adverb) {
return adverb == intents[index][n + 1];
}).length > 0;
var is_negative_left =
negatives.includes(intents[index][n - 1]);
var is_negative_right =
negatives.includes(intents[index][n + 1]);
if (intent == 'or') {
split = (!(is_adj_left &&
is_adj_right)) ? false : true;
split = (!(is_adv_left && is_adv_right)) ?
false : true;
split = ((is_negative_left == true ||
is_negative_right == true)) ? true : false;
}
else if (intent == 'and') {
if (!(is_noun_left && is_noun_right)) {
split = true;
}
}
}
return split;
}
}
}));
}
if (sentences.length > 0) {
intents = sentences;
}
intents = intents.map(function (intents) {
var is_entity = intents.filter(function (intent) {
return prep_list5.filter(function (entity) {
return intent.match('^' + entity);
}).length > 0;
}).length > 0;
return (is_entity == false) ?
intents.filter(function (value) {
return nouns.includes(value) ||
verbs.includes(value) ||
negatives.includes(value);
}) : intents;
}).filter(function (intents) {
return intents.length > 0;
});
var predicates = [];
for (let index = 0; index < intents.length; index++) {
if (intents[index].length > 1) {
await parse_verb_plus_noun(intents[index],
results['details'], concepts).then((results) => {
if (results != undefined && results.length > 0) {
predicates = predicates.concat(results);
}
});
}
}
for (let index = 0; index < entity_intents.length; index++) {
if (entity_intents[index].length > 1) {
await parse_noun_plus_verb(entity_intents[index],
results['details'], concepts).then((results) => {
predicates = predicates.concat(results);
});
}
}
for (let index = 0; index < entity_intents.length; index++) {
if (entity_intents[index].length > 1) {
await parse_noun_plus_suffix_noun(entity_intents[index],
results['details'], concepts).then((results) => {
predicates = predicates.concat(results);
});
}
}
for (let index = 0; index < entity_intents.length; index++) {
if (entity_intents[index].length > 1) {
await parse_noun_plus_verb_rev(entity_intents[index],
results['details'], concepts).then((results) => {
if (results != undefined && results.length > 0) {
predicates = predicates.concat(results);
}
});
}
}
var intents_results = [];
for (let i = 0; i < predicates.length; i++) {
for (let j = 0; j < concepts.length; j++) {
var is_similar = false;
var is_negative1 = predicates[i]['negative'];
var is_negative2 = concepts[j]['negative'];
var action1 = predicates[i]['action'];
var action2 = concepts[j]['intent']['action'];
var subject1 = predicates[i]['ent'];
var subject2 = concepts[j]['intent']['ent'];
if (is_negative1 == is_negative2) {
if ((action1 == action2) && (subject1 == subject2)) {
is_similar = true;
}
}
if (is_similar == true) {
intents_results.push(concepts[j]);
}
}
}
if (intents_results.length > 0) {
resolve({
'suggestions': nouns_suggs,
'intents': Array.from(new Set(intents_results))
});
} else reject(0);
});
});
},
}以下代码在多个阶段中执行NLP分析,包括规范化、语法解析和决策。规范化的代码如下所示:
async function normalize(sentence, concepts) {
return new Promise(async (resolve, reject) => {
const word_ps = new NlpWordPos();
var tokens = sentence.replace(
new RegExp(/[.!?]/gm), '%').split(/[ %]/gm);
var tokens = split_by_conditions(tokens,
function (token) { return token == ''; });
tokens = tokens.map(function (tokens) {
return tokens.filter(function (token) { return token != ''; });
});
tokens = tokens.map(function (tokens) {
return tokens.map(function (token) {
return token.replace(/,$/gm, '');
});
});
var words = sentence.split(/[ ,]/gm).map(function (word) {
return word.replace(new RegExp(/[.!?]/gm), '');
}).filter(function (word) {
return word != '';
});
await word_ps.getPOS(sentence).then((details) => {
var actions = Array.from(new Set(
concepts.map(function (class_obj) {
return class_obj['intent']['action'];
})));
if (actions.length > 0) {
details['verbs'] = actions;
}
var entities = Array.from(new Set(
concepts.map(function (class_obj) {
return class_obj['intent']['ent'];
})));
if (entities.length > 0) {
details['nouns'] = entities;
details['nouns'] = details['nouns'].concat(
details['verbs'].filter(function (verb) {
return noun_suffixes.filter(function (suffix) {
return verb.match('\\' + suffix + '$') != undefined ||
verb.match('\\' + suffix + 's$') != undefined;
}).length > 0 || adj_suffixes.filter(function (suffix) {
return verb.match('\\' + suffix + '$') != undefined ||
verb.match('\\' + suffix + 's$') != undefined;
}).length > 0;
}));
}
tokens = tokens.map(function (tokens) {
return tokens.filter(function (value) {
return value.length > 2 ||
details['verbs'].includes(value) ||
prep_list2.includes(value) || prep_list3.includes(value) ||
prep_list5.includes(value);
})
});
if (tokens != undefined && tokens.length > 0) {
resolve({
'tokens': tokens, 'details': details,
'stats': { 'words': words,
'count': Array.from(new Set(words)).length }
});
} else reject(0);
});
});
}这两个主要功能对于整个NLP分析过程至关重要。
创建语义知识数据库
我们将在“使用代码”一章中重点介绍的最后一个方面是使用MySQL创建部署语义知识数据库。以下数据库是关系数据库,下面列出了SQL脚本:
CREATE TABLE `actions` (
`action_id` int(11) NOT NULL AUTO_INCREMENT,
`action` varchar(255) NOT NULL,
PRIMARY KEY (`action_id`)
);CREATE TABLE `entities` (
`entity_id` int(11) NOT NULL AUTO_INCREMENT,
`entity` varchar(255) NOT NULL,
PRIMARY KEY (`entity_id`)
);CREATE TABLE `answers` (
`answer_id` int(11) NOT NULL AUTO_INCREMENT,
`answer` blob NOT NULL,
`url` varchar(255) DEFAULT NULL,
PRIMARY KEY (`answer_id`)
);
CREATE TABLE `concepts` (
`concept_id` int(11) NOT NULL AUTO_INCREMENT,
`action_id` int(11) NOT NULL,
`entity_id` int(11) NOT NULL,
`desc` text,
`negative` int(11) NOT NULL,
`answer_id` int(11) NOT NULL,
PRIMARY KEY (`concept_id`)
)
CREATE VIEW `concepts_view` AS SELECT
1 AS `concept_id`,
1 AS `action`,
1 AS `entity`,
1 AS `desc`,
1 AS `negative`,
1 AS `answer`,
1 AS `url`;可用于 model/nlp-samular_db.sql 中包含的数据库维护和数据导入的完整代码。
兴趣点
在本文中,我们介绍了基于规则的自然语言处理(NLP)引擎的示例。*但是*自然处理引擎(NLP)开发的真正工作才刚刚开始:)。使用其他策略将相当有趣,例如用人工智能或基于人工神经网络或现代分类器算法的机器学习取代基于算法的决策过程。
https://www.codeproject.com/Articles/1278022/A-Natural-Language-Processing-Engine-NLP-for-Chatb

















 2029
2029

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









